基于Storm的Nginx log实时监控系统
- - UC技术博客UAE(UC App Engine)是一个UC内部的PaaS平台,总体架构有点类似CloudFoundry,包括:. 快速部署:支持Node.js、Play!、PHP等框架. 信息透明:运维过程、系统状态、业务状况. 灰度试错:IP灰度、地域灰度. 基础服务:key-value存储、MySQL高可用、图片平台等.
日志是个好东西,对技术人员来说写日志能纪录成长,分享经验;对机器来说纪录日志能及时发现错误,为日后的排错提供信息。如果还在一台机器上用 tail -f 监听单个日志或者 用 multitail 监听多个日志也太 out 了,我们需要一种工具能纪录上百台机器、不同类型的日志,并最好能汇集到一个界面里方便查看,最好还是实时的。log.io 就是这样一个实时日志监控工具,采用 node.js + socket.io 开发,使用浏览器访问,每秒可以处理超过5000条日志变动消息。有一点要指出来的是 log.io 只监视日志变动并不存储日志,不过这个没关系,我们知道日志存储在哪个机器上。
和其他的监控工具一样,log.io 也采用服务器-客户端的模式。log.io 由两部分组成:server 和 harvester, server 运行在机器 A(服务器)上监视和纪录其他机器发来的日志消息;log harvester 运行在机器 B(客户端)上用来监听和收集机器 B 上的日志改动,并将改动发送给机器 A,每个需要纪录日志的机器都需要一个 harvester.
因为 log.io 基于 node.js,所以在服务器和客户端都要安装 node.js,这里采用编译安装的办法,首先安装需要的依赖包:
$ sudo apt-get install g++ make git libssl-dev pkg-config
下载 node.js 源代码,编译并安装:
$ wget http://nodejs.org/dist/v0.8.14/node-v0.8.14.tar.gz $ tar zxvf node-v0.8.14.tar.gz $ cd node-v0.8.14/ $ ./configure $ make $ sudo make install
安装 NPM:
$ curl https://npmjs.org/install.sh | sudo sh
安装 log.io(包含了 log server 和 log harvester)
$ sudo npm config set unsafe-perm true $ sudo npm install -g --prefix=/usr/local log.io
$ sudo log.io server start
server 用来监听各个机器发来的日志消息,harvester 用来把本机的日志发给 server,所以 harvester 配置的时候需要指定 server 的主机地址(或域名)。如何告诉 harvester 哪些日志需要监控呢?log_file_paths 就是指定日志路径的地方。下面的配置是 harvester 把 auth.log 和 harvester.log 这两个日志的改动发送给 server:
$ sudo vi /etc/log.io/harvester.conf
exports.config = {
// Log server host & port
server: {
host: 'log.vpsee.com', // 也可以用 IP 地址
port: 8998,
},
// Watch the following log files, defined by label:path mappings
log_file_paths: {
logio_auth: '/var/log/auth.log',
logio_harvester: '/var/log/log.io/harvester.log',
},
instance_name : 'log_node_1'
}
启动 harvester:
$ sudo log.io harvester start
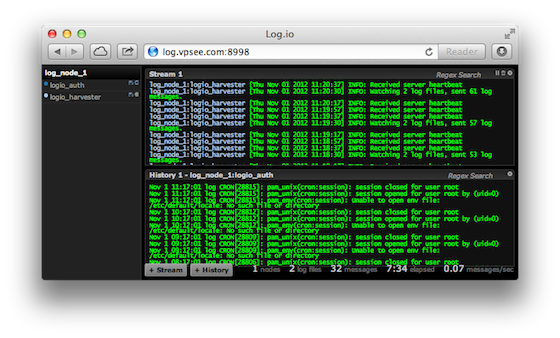
打开浏览器访问 log server 所在的机器 A,域名是 log.vpsee.com(也可以用 IP 地址),端口是 8998: