网站日志实时分析工具 GoAccess
- - vpsee.comGoAccess 是一款开源的网站日志实时分析工具. GoAccess 的工作方式很容易理解,就是读取和解析 Apache/Nginx/Lighttpd 的访问日志文件 access log,然后以更友好的方式把统计信息显示出来. 统计的内容包括:访问概况、动态页面请求、静态页面请求(如图片、样式表、脚本等)、访客排名,访客使用的操作系统,访客使用的浏览器,来路域名,404 错误,搜索爬虫,搜索关键词等等.
GoAccess 是一款开源的网站日志实时分析工具。GoAccess 的工作方式很容易理解,就是读取和解析 Apache/Nginx/Lighttpd 的访问日志文件 access log,然后以更友好的方式把统计信息显示出来。统计的内容包括:访问概况、动态页面请求、静态页面请求(如图片、样式表、脚本等)、访客排名,访客使用的操作系统,访客使用的浏览器,来路域名,404 错误,搜索爬虫,搜索关键词等等。
GoAccess 的性能也不赖,据官方测试,在一台 Intel Xeon CPU @ 2.40ghz CPU, 2GB 内存的机器上处理日志文件的速度是97000行每秒。
Linux 发行版本自带的 GoAccess 一般太老,比如 Ubuntu 12.04 带的是 0.4.2,Ubuntu 13.10 带的是 0.5,而最新的 goaccess 版本是 0.7.1. 所以类似不常用的软件,Linux 发行官方关注也少,为了使用最新的版本,最好采用源代码安装的方式。
在 CentOS 6.5 上安装编译 GoAccess 时需要的工具和库:
# yum groupinstall 'Development Tools' # yum install glib2 glib2-devel ncurses-devel
在 Ubuntu 12.04 上安装编译 GoAccess 时需要的工具和库:
$ sudo apt-get install build-essential $ sudo apt-get install libglib2.0-dev libncursesw5-dev
下载 GoAccess 的源代码、编译和安装:
$ wget http://downloads.sourceforge.net/project/goaccess/0.7.1/goaccess-0.7.1.tar.gz $ tar -xzvf goaccess-0.7.1.tar.gz $ cd goaccess-0.7.1/ $ ./configure --enable-utf8 $ make $ sudo make install
运行 GoAccess,选择 NCSA Combined Log Format:
$ /usr/local/bin/goaccess -f /var/log/apache2/access.log
+--------------------------------------------------+
| Log Format Configuration |
| [SPACE] to toggle - [ENTER] to proceed |
| |
| [ ] Common Log Format (CLF) |
| [ ] Common Log Format (CLF) with Virtual Host |
| [x] NCSA Combined Log Format |
| [ ] NCSA Combined Log Format with Virtual Host |
| [ ] W3C |
| [ ] CloudFront (Download Distribution) |
| |
| Log Format - [c] to add/edit format |
| %h %^[%d:%^] "%r" %s %b "%R" "%u" |
| |
| Date Format - [d] to add/edit format |
| %d/%b/%Y |
+--------------------------------------------------+
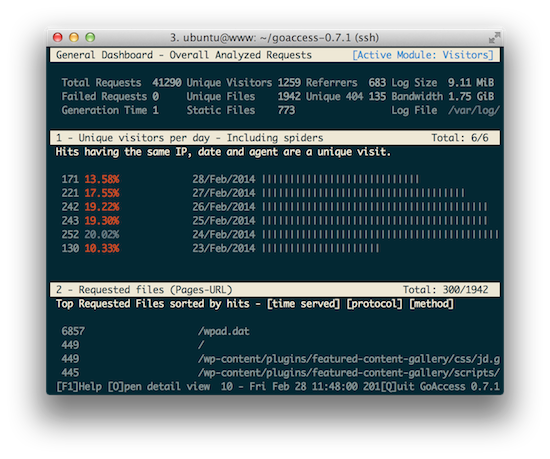
界面如下:
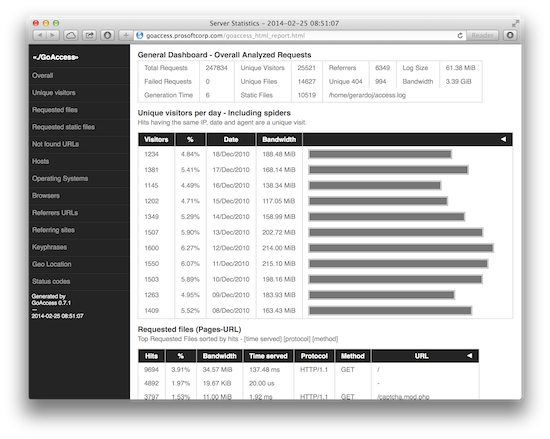
GoAccess 还可以生成 HTML 格式的报告:
$ /usr/local/bin/goaccess -f /var/log/apache2/access.log -a > report.html