李斯宁(高级测试开发工程师)
一、摘要
由于硬件问题、系统资源紧缺或者程序本身的BUG,Java服务在线上不可避免地会出现一些“系统性”故障,比如:服务性能明显下降、部分(或所有)接口超时或卡死等。其中部分故障隐藏颇深,对运维和开发造成长期困扰。笔者根据自己的学习和实践,总结出一套行之有效的“逐步排除”的方法,来快速定位Java服务线上“系统性”故障。
二、导言
Java语言是广泛使用的语言,它具有跨平台的特性和易学易用的特点,很多服务端应用都采用Java语言开发。由于软件系统本身以及运行环境的复杂性,Java的应用不可避免地会出现一些故障。尽管故障的表象通常比较明显(服务反应明显变慢、输出发生错误、发生崩溃等),但故障定位却并不一定容易。为什么呢?有如下原因:
1. 程序打印的日志越详细,越容易定位到BUG,但是可能有些时候程序中没有打印相关内容到日志,或者日志级别没有设置到相应级别
2. 程序可能只对很特殊的输入条件发生故障,但输入条件难以推断和复现
3. 通常自己编写的程序出现的问题会比较容易定位,但应用经常是由多人协作编写,故障定位人员可能并不熟悉其他人员编写的程序
4. 应用通常会依赖很多第三方库,第三方库中隐藏着的BUG可能是始料未及的
5. 多数的开发人员学习的都是“如何编写业务功能”的技术资料,但对于“如何编写高效、可靠的程序”、“如何定位程序故障”却知之甚少。所以一旦应用出现故障,他们并没有足够的技术背景知识来帮助他们完成故障定位。
尽管有些故障会很难定位,但笔者根据学习和实践总结出一套“逐步排除”的故障定位方法: 通过操作系统和Java虚拟机提供的监控和诊断工具,获取到系统资源和目标服务(出现故障的Java服务)内部的状态,并依据服务程序的特点,识别出哪些现象是正常的,哪些现象是异常的。而后通过排除正常的现象,和跟踪异常现象,就可以达到 故障定位的目标。
在正式介绍该方法之前,先申明一下这个方法使用的范围。
三、本方法适用的范围
本方法主要适用于Linux系统中Java服务线上“系统性”故障的定位,比如:服务性能明显下降、部分(或所有)接口超时或卡死。其它操作系统或其它语言的服务,也可以参考本文的思路。
不适用本方法的情况:对于“功能性”故障,例如运算结果不对、逻辑分支走错等,不建议使用本方法。对待这些情况比较恰当的方法是在测试环境中重现,并使用Java虚拟机提供的“远程调试”功能进行动态跟踪调试。
前面说过,本方法基于“异常现象”的识别来定位故障。那系统中可能有哪些异常现象呢?
四、有哪些异常现象
我们可以将异常现象分成两类:系统资源的异常现象、“目标服务”内部的异常现象。目标服务,指的是出现故障的Java服务。
1. 系统资源的异常现象
一个程序由于BUG或者配置不当,可能会占用过多的系统资源,导致系统资源匮乏。这时,系统中其它程序就会出现计算缓慢、超时、操作失败等“系统性”故障。常见的系统资源异常现象有:CPU占用过高、物理内存富余量极少、磁盘I/O占用过高、发生换入换出过多、网络链接数过多。可以通过top、iostat、vmstat、netstat工具获取到相应情况。
2. 目标服务内部的异常现象
- Java堆满
Java堆是“Java虚拟机”从操作系统申请到的一大块内存,用于存放Java程序运行中创建的对象。当Java堆满或者较满的情况下,会触发“Java虚拟机”的“垃圾收集”操作,将所有“不可达对象”(即程序逻辑不能引用到的对象)清理掉。有时,由于程序逻辑或者Java堆参数设置的问题,会导致“可达对象”(即程序逻辑可以引用到的对象)占满了Java堆。这时,Java虚拟机就会无休止地做“垃圾回收”操作,使得整个Java程序会进入卡死状态。我们可以使用jstat工具查看Java堆的占用率。
- 日志中的异常
目标服务可能会在日志中记录一些异常信息,例如超时、操作失败等信息,其中可能含有系统故障的关键信息。
- 疑难杂症
死锁、死循环、数据结构异常(过大或者被破坏)、集中等待外部服务回应等现象。这些异常现象通常采用jstack工具可以获取到非常有用的线索。
了解异常现象分类之后,我们来具体讲讲故障定位的步骤。
五、故障定位的步骤
我们采用“从外到内,逐步排除”的方式来定位故障:
1. 先排除其它程序过度占用系统资源的问题
2. 然后排除“目标服务”本身占用系统资源过度的问题
3. 最后观察目标服务内部的情况,排除掉各种常见故障类型。
对于不能排除的方面,要根据该信息对应的“危险程度”来判断是应该“进一步深入”还是“暂时跳过”。例如“目标服务Java堆占用100%”这是一条危险程度较高的信息,建议立即“进一步深入”。而对于“在CPU核数为8的机器上,其它程序偶然占用CPU达200%”这种危险程度不是很高的信息,则建议“暂时跳过”。当然,有些具体情况还需要故障排查人员根据自己的经验做出判断。
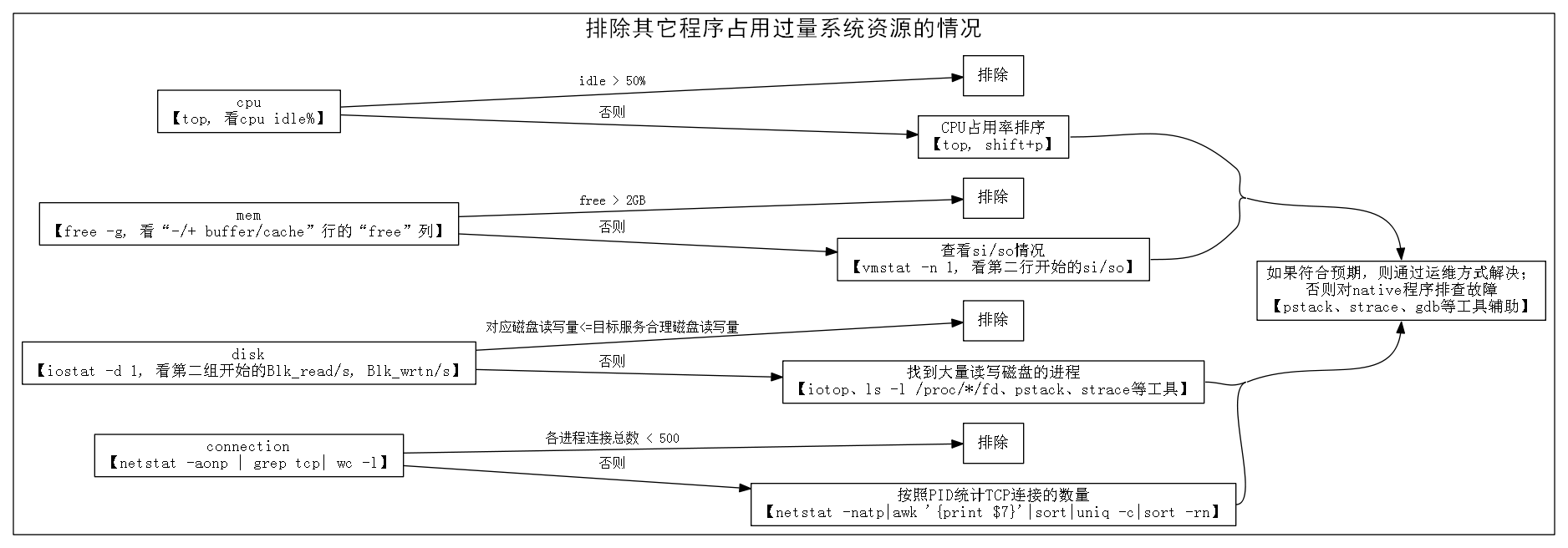
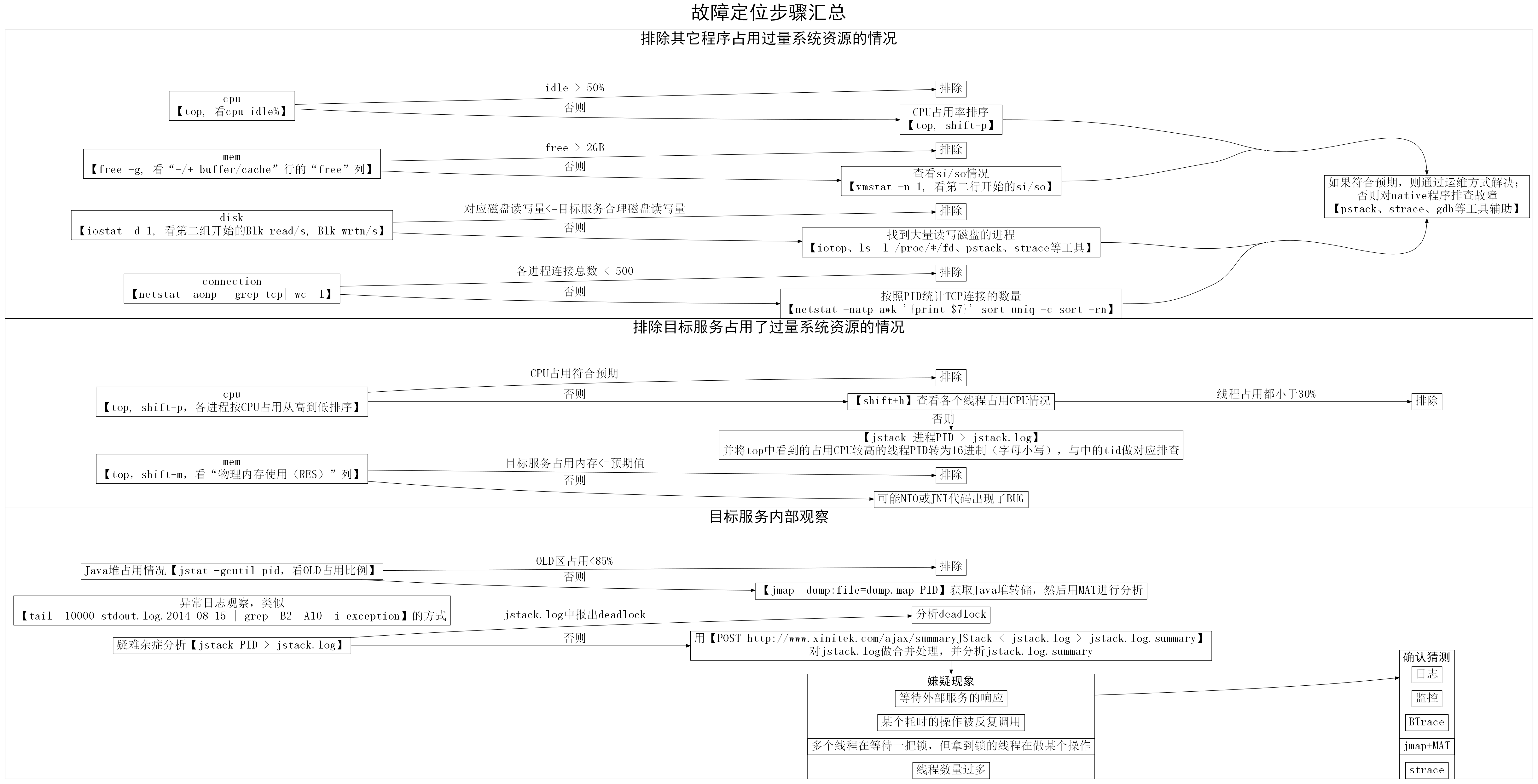
第一步:排除其它程序占用过量系统资源的情况
图示:排除其它程序占用过量系统资源的情况
1. 运行【top】,检查CPU idle情况,如果发现idle较多(例如多余50%),则排除其它进程占用CPU过量的情况。
如果idle较少,则按shift+p,将进程按照CPU占用率从高到低排序,逐一排查(见下面TIP)。
2. 运行【free -g】,检查剩余物理内存(“-/+ buffer/cache”行的“free”列)情况,如果发现剩余物理内存较多(例如剩余2GB以上),则排除占用物理内存过量的情况。
如果剩余物理内存较少(例如剩余1GB以下),则运行【vmstat -n 1】检查si/so(换入换出)情况,
第一行数值表示的是从系统启动到运行命令时的均值,我们忽略掉。从第二行开始,每一行的si/so表示该秒内si/so的block数。如果多行数值都为零,则可以排除物理内存不足的问题。如果数值较大(例如大于1000 blocks/sec,block的大小一般是1KB)则说明存在较明显的内存不足问题。我们可以运行【top】输入shift+m,将进程按照物理内存占用(“RES”列)从大到小进行排序,然后对排前面的进程逐一排查(见下面TIP)。
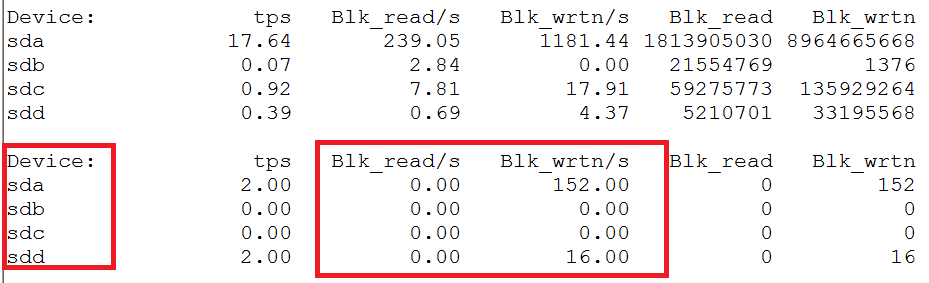
3. 如果目标服务是磁盘I/O较重的程序,则用【iostat -d 1】,检查磁盘I/O情况。若“目标服务对应的磁盘”读写量在预估之内(预估要注意cache机制的影响),则排除其它进程占用磁盘I/O过量的问题。
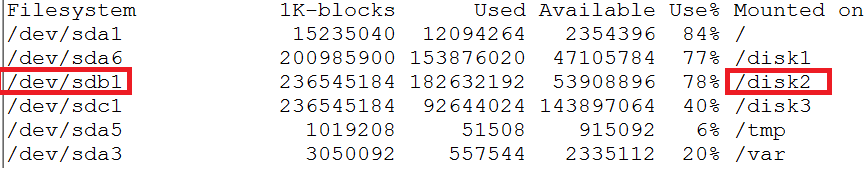
第一组数据是从该机器从开机以来的统计值。从第二组开始,都是每秒钟的统计值。通过【df】命令,可以看到Device与目录的关系。下图设备“sdb”就对应了目录“/disk2”。
假如发现目标服务所在磁盘读写量明显超过推算值,则应该找到大量读写磁盘的进程(见下面TIP)
4. 运行【netstat -aonp | grep tcp| wc -l】查看各种状态的TCP连接数量和。如果总数较小(例如小于500),则排除连接数占用过多问题。
假如发现连接数较多,可以用【netstat -natp|awk ‘{print $7}’|sort|uniq -c|sort -rn】按照PID统计TCP连接的数量,然后对连接数较多的进程逐一排查(见下面TIP)。
TIP:如何“逐一排查”:假如定位到是某个外部程序占用过量系统资源,则依据进程的功能和配置情况判断是否合乎预期。假如符合预期,则考虑将服务迁移到其他机器、修改程序运行的磁盘、修改程序配置等方式解决。假如不符合预期,则可能是运行者对该程序不太了解或者是该程序发生了BUG。外部程序通常可能是Java程序也可能不是Java程序,如果是Java程序,可以把它当作目标服务一样进行排查;而非Java程序具体排查方法超出了本文范围,列出三个工具供参考选用:
- 系统提供的调用栈的转储工具【pstack】,可以了解到程序中各个线程当前正在干什么,从而了解到什么逻辑占用了CPU、什么逻辑占用了磁盘等
- 系统提供的调用跟踪工具【strace】,可以侦测到程序中每个系统API调用的参数、返回值、调用时间等。从而确认程序与系统API交互是否正常等。
- 系统提供的调试器【gdb】,可以设置条件断点侦测某个系统函数调用的时候调用栈是什么样的。从而了解到什么逻辑不断在分配内存、什么逻辑不断在创建新连接等
TIP:如何“找到大量读写磁盘的进程”:
1. 如果Linux系统比较新(kernel v2.6.20以上)可以使用iotop工具获知每个进程的io情况,较快地定位到读写磁盘较多的进程。
2. 通过【ls -l /proc/*/fd | grep 该设备映射装载到的文件系统路径】查看到哪个进程打开了该设备的文件,并根据进程身份、打开的文件名、文件大小等属性判断是否做了大量读写。
3. 可以使用pstack取得进程的线程调用栈,或者strace跟踪磁盘读写API来帮助确认某个进程是否在做磁盘做大量读写
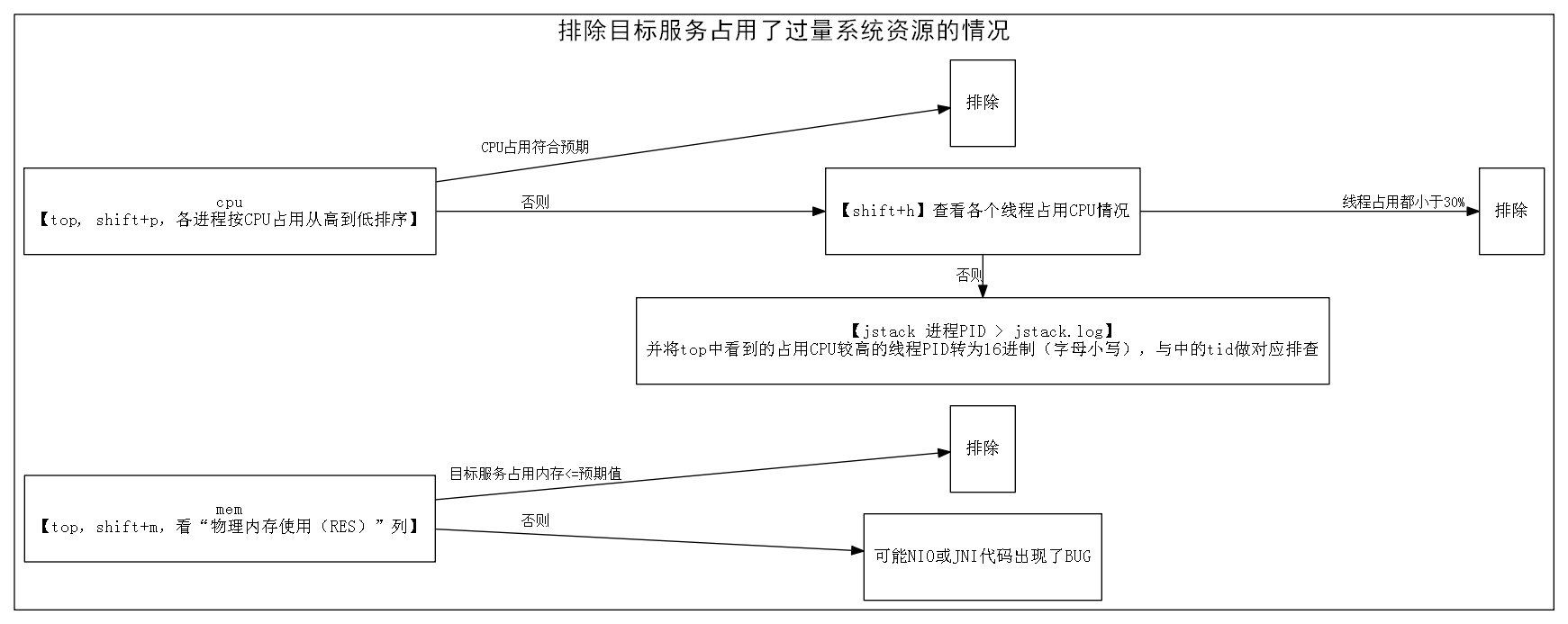
第二步:排除目标服务占用了过量系统资源的情况
图示:排除目标服务占用了过量系统资源的情况
1. 运行【top】,shift+p按照“CPU使用”从高到低的排序查看进程,假如目标服务占用的CPU较低(<100%,即小于一个核的计算量),或者符合经验预期,则排除目标服务CPU占用过高的问题。
假如目标服务占用的CPU较高(>100%,即大于一个核的计算量),则shift+h观察线程级别的CPU使用分布。
- 如果CPU使用分散到多个线程,而且每个线程占用都不算高(例如都<30%),则排除CPU占用过高的问题
- 如果CPU使用集中到一个或几个线程,而且很高(例如都>95%),则用【jstack pid > jstack.log】获取目标服务中线程调用栈的情况。top中看到的占用CPU较高的线程的PID转换成16进制(字母用小写),然后在jstack.log中找到对应线程,检查其逻辑:
- 假如对应线程是纯计算型任务(例如GC、正则匹配、数值计算等),则排除CPU占用过高的问题。当然如果这种线程占用CPU总量如果过多(例如占满了所有核),则需要对线程数量做控制(限制线程数 < CPU核数)。
- 假如对应线程不是纯计算型任务(例如只是向其他服务请求一些数据,然后简单组合一下返回给用户等),而该线程CPU占用过高(>95%),则可能发生了异常。例如:死循环、数据结构过大等问题,确定具体原因的方法见下文“第三步:目标进程内部观察”。
2. 运行【top】,shift+m按照“物理内存使用(RES)”从高到低排序进程,评估目标服务占的内存量是否在预期之内。如果在预期之内,则排除目标服务Native内存占用过高的问题。
提示:由于Java进程中有Java级别的内存占用,也有Native级别的内存占用,所以Java进程的“物理内存使用(RES)”比“-Xmx参数指定的Java堆大小”大一些是正常的(例如1.5~2倍左右)。
假如“物理内存使用(RES)”超出预期较多(例如2倍以上),并且确定JNI逻辑不应该占用这么多内存,则可能是NIO或JNI代码出现了BUG。由于本文主要讨论的是Java级别的问题,所以对这种情况不做过多讨论。读者可以参考上文“TIP:如何逐一排查”进行native级别的调试。
第三步:目标服务内部观察
图示:目标服务内部观察
1. Java堆占用情况
用【jstat -gcutil pid】查看目标服务的OLD区占用比例,假如占用比例低于85%则排除Java堆占用比例过高的问题。
假如占用比例较高(例如超过98%),则服务存在Java堆占满的问题。这时候可以用jmap+mat进行分析定位内存中占用比例的情况(见下文TIP),从而较快地定位到Java堆满的原因。
TIP:用jmap+mat进行分析定位内存中占用比例的情况
先通过【jmap -dump:file=dump.map pid】取得目标服务的Java堆转储,然后找一台空闲内存较大的机器在VNC中运行mat工具。mat工具中打开dump.map后,可以方便地分析内存中什么对象引用了大量的对象(从逻辑意义上来说,就是该对象占用了多大比例的内存)。具体使用可以ca
2. 异常日志观察
通过类似【tail -10000 stdout.log.2014-08-15 | grep -B2 -A10 -i exception】这样的方式,可以查到日志中最近记录的异常。
3. 疑难杂症
用【jstack pid > jstack.log】获取目标服务中“锁情况”和“各线程调用栈”信息,并分析
- 检查jstack.log中是否有deadlock报出,如果没有则排除deadlock情况。
Found one Java-level deadlock:
=============================
waiting to lock monitor 0x1884337c (object 0x046ac698, a java.lang.Object),
waiting to lock monitor 0x188426e4 (object 0x046ac6a0, a java.lang.Object),
which is held by “Thread-0″
Java stack information for the threads listed above:
===================================================
“Thread-0″:
at LockProblem$T2.run(LockProblem.java:14)
- waiting to lock <0x046ac698> (a java.lang.Object)
- locked <0x046ac6a0> (a java.lang.Object)
“main”:
at LockProblem.main(LockProblem.java:25)
- waiting to lock <0x046ac6a0> (a java.lang.Object)
- locked <0x046ac698> (a java.lang.Object)
Found 1 deadlock.
如果发现deadlock则则根据jstack.log中的提示定位到对应代码逻辑。
通过jstack.log.summary中的情况,我们可以较迅速地定位到一些嫌疑点,并可以猜测其故障引起的原因(后文有jstack.log.summary情况举例供参考)
| 情况 |
嫌疑点 |
猜测原因 |
| 线程数量过多 |
某种线程数量过多 |
运行环境中“限制线程数量”的机制失效
|
|
多个线程在等待一把锁,但拿到锁的线程在做某个操作
|
拿到这把锁的线程在做网络connect操作
|
被connect的服务异常 |
|
|
拿到锁的线程在做数据结构遍历操作
|
该数据结构过大或被破坏
|
|
某个耗时的操作被反复调用
|
某个应当被缓存的对象多次被创建
|
对象池的配置错误 |
|
等待外部服务的响应
|
很多线程都在等待外部服务的响应
|
该外部服务故障
|
|
|
很多线程都在等待FutureTask完成,而FutureTask在等待外部服务的响应
|
该外部服务故障
|
猜测了原因后,可以通过日志检查、监控检查、用测试程序尝试复现等方式确认猜测是否正确。如果需要更细致的证据来确认,可以通过BTrace、strace、jmap+MAT等工具进行分析,最终确认问题所在。
下面简单介绍下这几个工具:
BTrace:用于监测Java级别的方法调用情况。可以对运行中的Java虚拟机插入调试代码,从而确认方法每次调用的参数、返回值、花费时间等。第三方免费工具。
strace:用于监视系统调用情况。可以得到每次系统调用的参数、返回值、耗费时间等。Linux自带工具。
jmap+MAT:用于查看Java级别内存情况。jmap是JDK自带工具,可以将Java程序的Java堆转储到数据文件中;MAT是eclipse.org上提供的一个工具,可以检查jmap转储数据文件中的数据。结合这两个工具,我们可以非常容易地看到Java程序内存中所有对象及其属性。
TIP:jstack.log.summary情况举例
1. 某种线程数量过多
1000 threads at
“Timer-0″ prio=6 tid=0x189e3800 nid=0x34e0 in Object.wait() [0x18c2f000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.util.TimerThread.mainLoop(Timer.java:552)
- locked [***] (a java.util.TaskQueue)
at java.util.TimerThread.run(Timer.java:505)
2. 多个线程在等待一把锁,但拿到锁的线程在做数据结构遍历操作
38 threads at
“Thread-44″ prio=6 tid=0×18981800 nid=0x3a08 waiting for monitor entry [0x1a85f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at SlowAction$Users.run(SlowAction.java:15)
- waiting to lock [***] (a java.lang.Object)
1 threads at
“Thread-3″ prio=6 tid=0x1894f400 nid=0×3954 runnable [0x18d1f000]
java.lang.Thread.State: RUNNABLE
at java.util.LinkedList.indexOf(LinkedList.java:603)
at java.util.LinkedList.contains(LinkedList.java:315)
at SlowAction$Users.run(SlowAction.java:18)
- locked [***] (a java.lang.Object)
3. 某个应当被缓存的对象多次被创建(数据库连接)
99 threads at
“resin-tcp-connection-*:3231-321″ daemon prio=10 tid=0x000000004dc43800 nid=0x65f5 waiting for monitor entry [0x00000000507ff000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.commons.dbcp.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:290)
- waiting to lock <0x00000000b26ee8a8> (a org.apache.commons.dbcp.PoolableConnectionFactory)
at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:771)
at org.apache.commons.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:95)
…
1 threads at
“resin-tcp-connection-*:3231-149″ daemon prio=10 tid=0x000000004d67e800 nid=0x66d7 runnable [0x000000005180f000]
java.lang.Thread.State: RUNNABLE
…
at org.apache.commons.dbcp.DriverManagerConnectionFactory.createConnection(DriverManagerConnectionFactory.java:46)
at org.apache.commons.dbcp.PoolableConnectionFactory.makeObject(PoolableConnectionFactory.java:290)
- locked <0x00000000b26ee8a8> (a org.apache.commons.dbcp.PoolableConnectionFactory)
at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:771)
at org.apache.commons.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:95)
at …
4. 很多线程都在等待外部服务的响应
100 threads at
“Thread-0″ prio=6 tid=0x189cdc00 nid=0×2904 runnable [0x18d5f000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:150)
at java.net.SocketInputStream.read(SocketInputStream.java:121)
…
at RequestingService$RPCThread.run(RequestingService.java:24)
5. 很多线程都在等待FutureTask完成,而FutureTask在等待外部服务的响应
100 threads at
“Thread-0″ prio=6 tid=0×18861000 nid=0x38b0 waiting on condition [0x1951f000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for [***] (a java.util.concurrent.FutureTask$Sync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:186)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:834)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(AbstractQueuedSynchronizer.java:994)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1303)
at java.util.concurrent.FutureTask$Sync.innerGet(FutureTask.java:248)
at java.util.concurrent.FutureTask.get(FutureTask.java:111)
at IndirectWait$MyThread.run(IndirectWait.java:51)
100 threads at
“pool-1-thread-1″ prio=6 tid=0x188fc000 nid=0×2834 runnable [0x1d71f000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:150)
at java.net.SocketInputStream.read(SocketInputStream.java:121)
…
at IndirectWait.request(IndirectWait.java:23)
at IndirectWait$MyThread$1.call(IndirectWait.java:46)
at IndirectWait$MyThread$1.call(IndirectWait.java:1)
at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:334)
at java.util.concurrent.FutureTask.run(FutureTask.java:166)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1110)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:603)
at java.lang.Thread.run(Thread.java:722)
为方便读者使用,将故障定位三个步骤的图合并如下:
图示:故障定位步骤汇总
故障定位是一个较复杂和需要经验的过程,如果现在故障正在发生,对于分析经验不很多的开发或运维人员,有什么简单的操作步骤记录下需要的信息吗?下面提供一个
六、给运维人员的简单步骤
如果事发突然且不能留着现场太久,要求运维人员:
1. top: 记录cpu idle%。如果发现cpu占用过高,则c, shift+h, shift + p查看线程占用CPU情况,并记录
2. free: 查看内存情况,如果剩余量较小,则top中shift+m查看内存占用情况,并记录
3. 如果top中发现占用资源较多的进程名称(例如java这样的通用名称)不太能说明进程身份,则要用ps xuf | grep java等方式记录下具体进程的身份
4. 取jstack结果。假如取不到,尝试加/F
jstack命令: jstack PID > jstack.log
5. jstat查看OLD区占用率。如果占用率到达或接近100%,则jmap取结果。假如取不到,尝试加/F
jstat命令: jstat -gcutil PID
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 21.35 88.01 97.35 59.89 111461 1904.894 1458 291.369 2196.263
jmap命令: jmap -dump:file=dump.map PID
6. 重启服务
七、参考资料