elasticsearch集群搭建
- - zzm之前对于CDN的日志处理模型是从 . logstash agent==>>redis==>>logstash index==>>elasticsearch==>>kibana3,对于elasticsearch集群搭建,可以把索引进行分片存储,一个索引可以分成若干个片,分别存储到集群里面,而对于集群里面的负载均衡,副本分配,索引动态均衡(根据节点的增加或者减少)都是elasticsearch自己内部完成的,一有情况就会重新进行分配.
〇、环境配置
服务器:3台(node1 -> node3)
操作系统:Cent OS 5.6,添加普通用户deploy
ElasticSearch版本:1.7.1
JDK版本:1.8
一、安装JDK(所有服务器)
在每台服务器(node1 -> node3)上安装JDK,安装过程略。
以下二至六步可以选取某台服务器执行。
二、安装ElasticSearch
1、下载elasticsearch-1.7.1.tar.gz
2、解压:[deploy@node1 ~]$ tar -xf elasticsearch-1.4.2.tar.gz
三、安装elasticsearch-head插件
elasticsearch-head是一个elasticsearch的集群管理工具,它是完全由html5编写的独立网页程序。
1、联网环境,执行下面语句进行安装:
[deploy@node1 ~]$ ./elasticsearch-1.7.1/bin/plugin -install mobz/elasticsearch-head
2、离线安装:
[deploy@node190 ~]$ unzip elasticsearch-head-master.zip
[deploy@node1 ~]$ mkdir ./elasticsearch-1.7.1/plugins
[deploy@node1 ~]$ mkdir ./elasticsearch-1.7.1/plugins/head
[deploy@node1 ~]$ mkdir ./elasticsearch-1.7.1/plugins/head/_site
[deploy@node1 ~]$ cp -r ~/elasticsearch-head-master/* ./elasticsearch-1.7.1/plugins/head/_site
在执行:[deploy@node190 ~]$ ./elasticsearch-1.7.1/bin/elasticsearch
启动ElasticSearch后,可以通过访问: http://node1:9200/_plugin/head/,
可以看到如下图:

四、安装elasticsearch-sql插件
elasticsearch-sql插件可以做到:Query elasticsearch using familiar SQL syntax. You can also use ES functions in SQL.
执行下面语句进行安装:
[deploy@node1 ~]$ ./bin/plugin -u https://github.com/NLPchina/elasticsearch-sql/releases/download/1.3.5/elasticsearch-sql-1.3.5.zip --install sql
在启动ElasticSearch后,可以通过访问: http://localhost:9200/_plugin/sql/,
可以看到如下图:
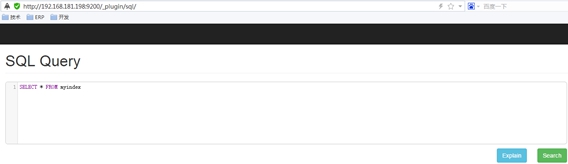
看到这个界面你也能想像到它是做什么的了吧?更多的信息可以去 https://github.com/NLPchina/elasticsearch-sql 获取,当然不能通过elasticsearch-sql把elasticsearch当关系型数据库用,但毕竟elasticsearch的查询语句不如solr那般简洁,所以对于熟悉sql的朋友,这样拼sql语句也是很方便的吧。此工具的开发者真是体贴。
五、安装elasticsearch-Bigdesk插件
bigdesk是elasticsearch的一个集群监控工具,可以通过它来查看es集群的各种状态,如:cpu、内存使用情况,索引数据、搜索情况,http连接数等。
1、联网环境
[deploy@node1 ~]$ ./bin/plugin -install lukas-vlcek/bigdesk
在启动ElasticSearch后,可以通过访问: http://node1:9200/_plugin/bigdesk/,
可以看到如下图:
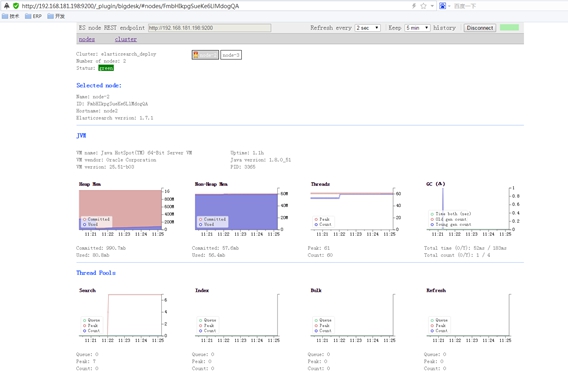

这个插件使得elasticsearch太直观了,数据在哪、怎么变动的都显示的一清二楚,大赞!为啥Solr没有这样的东东呢?
六、安装elasticsearch-servicewrapper插件
elasticsearch-servicewrapper插件是ElasticSearch的服务化插件。
在https://github.com/elasticsearch/elasticsearch-servicewrapper下载该插件后,解压缩。将service目录拷贝到elasticsearch目录的bin目录下。
而后,可以通过执行以下语句安装、启动、停止ElasticSearch。(先不要执行)
[root@node1 service]# sh elasticsearch install(Must be root to perform this action.)
[root@node1 service]# sh elasticsearch start
[root@node1 service]# sh elasticsearch stop
这个插件也是实用的不要不要的。没有此插件,有多少人还要写一个脚本来开机启动啊。需要的请举手!
七、将配置好的ElasticSearch拷贝到各服务器
在一台服务器上执行完成步骤二到步骤七后,得到最终的elasticsearch-1.7.1文件夹。将此文件夹打包并scp拷贝到各服务器。
八、配置ElasticSearch集群
在各服务器(node1 -> node3)中。
执行下面语句对配置文件elasticsearch.yml中的内容进行修改:
[deploy@node1 ~]$ vim elasticsearch-1.7.1/config/elasticsearch.yml
修改elasticsearch.yml后的部分文件内容:
################################### Cluster ###################################
# Cluster name identifies your cluster for auto-discovery. If you're running
# multiple clusters on the same network, make sure you're using unique names.
#
cluster.name: elasticsearch_deploy
#################################### Node #####################################
# Node names are generated dynamically on startup, so you're relieved
# from configuring them manually. You can tie this node to a specific name:
#
node.name: "node196"
九、启动ElasticSearch集群
可以通过执行sh elasticsearch start或./elasticsearch语句启动ElasticSearch。
也可以在通过执行[root@node1 service]# sh elasticsearch install后,通过执行:[root@node1 service]# chmod 777 /home/deploy/elasticsearch-1.7.1/bin/service/elasticsearch,分配给elasticsearch执行权限。执行[root@node1 service]# /etc/init.d/elasticsearch start启动ElasticSearch服务。而后就可以执行[root@node1 service]# service elasticsearch start来启动ElasticSearch了。系统reboot后也能开机启动。
在所有服务器(node1 -> node3)上的ElasticSearch配置相同的cluster.name后,依次启动各服务器上的ElasticSearch,便可以通过bigdesk查看该集群下的所有node状态。集群启动结束。
十、ElasticSearch集群功能测试
可以在head页面新建索引、删除索引、数据浏览、查询等操作,新建索引时需要设置分片数、副本数,可以在bigdesk页面进行分片及副本的查看。
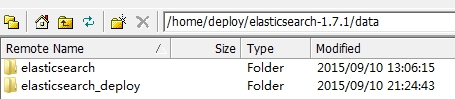
数据均存储于elasticsearch-1.7.1/data目录下,以cluster.name进行分目录存储。下图说明了两个cluster.name的存储方式。
我们对已启动的(node1 -> node3)上的ElasticSearch进行监控。下面图1 -> 图4是当集群中一个node重启时,集群内数据复制移动的过程。索引的分片数为5,副本数为1。
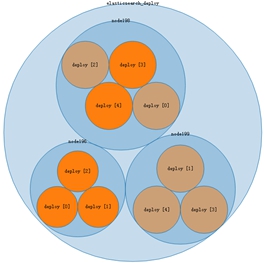
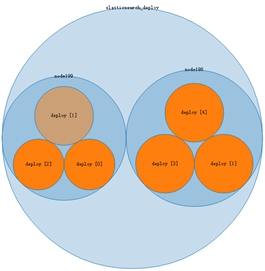
图1: 三个node稳定后 图2: 关闭一个node196

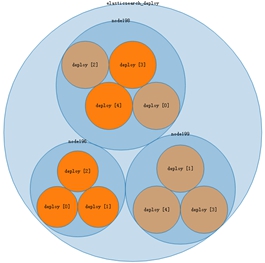
图3: 两个node稳定后 图4: 启动node196,恢复三个node稳定后
可以通过上面的操作和形象的图形,看到宕机一个对这个集群真是一点关系都没有,数据在各服务器间自如流动、分布,各服务器并无主次之分。
Solr我也用过很久,我个人感觉,ElasticSearch比Solr好就好在有那么多好用的插件可以用,即有形象直观的显示,又有方便实用的工具,真是感谢这些开源贡献者们,没有你们就没有这么一个好用的搜索引擎ElasticSearch了,很多的公司业务也便无法开展了!当然ElasticSearch目前也有不少亟需解决的问题,以后有空再聊。
本文链接: 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知,转载请注明。