120余万的搜狗细胞词库-fcitx&ibus拼音输入法词库:个人无聊的作品 (附加说明) - 查看主题 • Ubuntu中文论坛
http://code.google.com/p/hslinuxextra/downloads/list
上面的地址中,增加了三个词库文件和工程的源代码,有兴趣的同学可以自己去搞搞。
三个词库文件分别为:精简的词库、较全面的词库和非常全面的词库,自己下载解压后使用。
另外,很多人说词频不对,我现在调整了一下逻辑:ibus中词频信息没做任何变化,而fcitx中原有词频是较高等级而新词等级较低。
ibus pinyin要求最低为1.3.0,这个大家注意一下。
大家需要注意的是,不同版本甚至同一个版本不同发行版上词库db的目录可能不一样
请根据您自己的发行版和版本查找对应的文件覆盖
另外,经过与ibus开发者协商,ibus-pinyin的词库查找规则做了一些更改,只要在词库目录(就是有一个.db文件的那个目录,一般是/usr/share/ibus-pinyin/db目录)把新词库复制过来并改名为local.db就可以使用了,如果感觉词库不好直接删除掉local.db就可以让ibus使用原来的词库。
这两天,真的很累,没有一刻闲着的,公司的事情太多,太累了。
忙着无聊的时候,去搜狐的输入法网站上转了转,发现它竟然能下输入法词库文件
这个词库,utf-16编码的,反向出来以后,我给导入到了ibus拼音输入法里面了
唉,大家别怪我
去下面这个地址下载下来
http://code.google.com/p/hslinuxextra/downloads/list上的android.7z
或者直接点击链接:
http://hslinuxextra.googlecode.com/files/android.7z
然后解压,你应该会看到一个android.db文件,把这个文件放到/usr/share/ibus-pinyin/db里面,覆盖同名的db文件
不过有的同学ibus-pinyin的词库是openphrase的,反正这个目录里面只有一个db文件,你用你下载解压的那个文件改名后覆盖掉就行了
覆盖以后,你把ibus重启一下,如果你能打出下面的这个词组,说明生效了:
我的这个词库,基于ibus原有的android词库文件,另外增加了搜狐的下列词库:
IT计算机 电脑词汇大全 历史名人大全 搜狗标准大词库 医学词汇大全
财会词汇大全 电子计算机通信专业术语农业词汇大全 搜狗精选词库 艺术家小辞海
常用餐饮词汇【官方推荐】电子术语大全 农业类词库 搜狗万能词库 音乐大杂烩
常用植物名 动物词汇大全 农业系统扩充词库唐诗宋词成语俗语 饮食词汇大全
虫蛇类名词 概率与数理统计词库pro 全面词库 网络流行新词 影视歌名库
船舶港口词汇大全 化学词汇大全 诗词名句大全 网上最全的11.44万全国四级行政区划词库职业作家词库
地理地质词汇大全 机械工程词汇大全 书法词库大全 药品名称大全 最详细的全国地名大全
地质大词典 计算机名词 搜狗标准词库 医学词汇大全 (1)
我知道我的行为不妥,但是我的目的是让大家能学到新的词语
望大家勿怪
PS:我发现这个词库虽然比较大,但是实际占用内存不多,ibus的相应也挺迅速
---------------------------我是华丽的分割线-----------------------------------
另外,我增加了fcitx的词库:pyPhrase.org pyphrase.mb pybase.mb
http://hslinuxextra.googlecode.com/files/fcitx.7z
下载并解压
其中pyphrase.mb pybase.mb是编译好的词库,连同pyPhrase.org直接覆盖已经安装好的fcitx中的同名文件即可:/usr/share/fcitx/data中(把解压后的三个文件同时覆盖fcitx原有文件)
pyPhrase.org是源文件,编译时覆盖源代码目录的同名文件,也同样会生成pyphrase.mb。
请同学们多加使用
另外,由于ibus使用的sql,所以兼容性问题不大,但是对于fcitx来说可能会有问题出现,如果你的不能用,那么用下面的命令自己根据pyPhrase来做mb文件:
把生成的mb文件连同pyPhrase.org覆盖掉fcitx安装的data文件就可以了
最佳网页宽度及其实现 - 阮一峰的网络日志
1.
设计网页的时候,确定宽度是一件很苦恼的事。
以minifun.cn为例,根据Google Analytics的统计,半年多以来,访问者的屏幕分辨率一共有81种。最小的分辨率是122x160,这应该是手机;最大的分辨率是3360x1050,天知道是什么设备。
一张网页要在大小如此悬殊的各种屏幕上,都呈现令人满意的效果,难度可想而知。举例来说,一张400px宽的图片,在800px的屏幕上会占据50%的宽度,而在1920px的屏幕上(Windows Vista的流行设置),只占据20%。
2.
目前,常见的屏幕分辨率宽度大概有6种:800px,1024px,1280px,1440px,1680px和1920px。其中,1024px最常见,但是随着大屏幕显示器的流行,更高的分辨率正变得越来越多。
常见的解决方法有两种:
第一种:用javascript根据不同的客户端分辨率,选择css样式表文件,具体的做法可以看这里。
第二种:采用弹性布局(Fluid Width Layout),实现网页宽度的自适应。
第一种方法的优点是,可以根据不同屏幕分辨率,采用完全不同的布局,缺点是要设计和维护多张样式表,比较麻烦。第二种方法只采用一张样式表,比较省事。
下文就根据css-tricks上的解决方案,讨论如何实现第二种方法,实际上是很简单的。
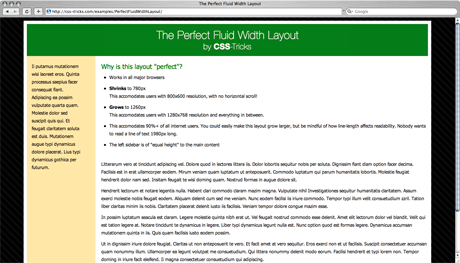
3.
首先,网页的缺省宽度,确定为满足1024px宽度的显示器。这不仅因为1024x768是现在最常见的分辨率,还因为这个宽度对网页最合适:1)它放得下足够的内容,足够三栏的布局;2)单行文字不宜太长,1024px已是极限,否则容易产生阅读疲劳;3)在当前的互联网带宽条件下,网页难以采用大分辨率所要求的大尺寸图片。
其次,网页宽度会在780px-1260px的范围内,自动变化,即最小不小于780px,最大不超过1280px。
最后,对于更大的分辨率,网页内容会自动居中。
4.
下面就是CSS文件的写法,只要4行。需要注意的是,这几行的语句都针对整个页面,即body标签或者最外层的那个div区域。
margin: 10px auto;
这一行保证了网页在任何分辨率下,都会居中。
min-width: 780px;
max-width: 1260px;
这二行规定了网页的最小和最大宽度。注意,IE6不支持这二行,即它们在IE6中是无效的。
width:expression(document.body.clientWidth < 782? "780px" : document.body.clientWidth > 1262? "1260px" : "auto");
这一行是针对IE6的解决方法。它采用了CSS表达式,也可以通过javascript实现。
另外,如果想让内层的各个区块也自动伸缩,它们的宽度可以采用百分比的形式,比如:
#div-left{
width:50%;
}#div-right{
width:50%;
}
最后的效果和源码下载请查看这里。通过变动浏览器窗口的大小,可以发现网页在780px-1260px的范围内会自动伸缩。
5.
最后,建议大家平时使用计算机的时候,不要盲目采用高分辨率,意义不大。
软件需求最佳实践读书笔记
1、需求规格说明不应该采用技术为导向,应该采用业务为导向来组织,分别面向不同层面(决策者、事务管理层、操作层)将需求分成不同的部分,让合适的人验证适当的部分,然后再汇总。
2、不要再把review活动叫做评审了。
3、最简单、最有效的review就是在用户代表阐述了需求之后,需求分析用自己的语言再复述一遍,以确保沟通没有失真。(工作安排技巧:让工作接受者复述任务内容)
4、业务场景中才能得到需求实质,业务场景中步骤性工作可能不是连续进行的。
5、采用满意/不满意模型进行需求必要性评价以辅助确定需求的优先级。
6、需要按照业务、技术开发、项目管理三个角度来确定优先级,技术开发、项目管理只提级不降级。业务角度根据业务价值和频度进行评价,技术开发根据技术依赖性进行调整,项目管理根据项目风险对优先级进行调整
7、编写需求规格功能书时,应确保一类信息只在一处描述,特别是数据字段信息。
8、SERU模型:Subject->Event/Report->User Case。按照构建主题域,标识业务事件和报表类型,再进行事、物、人分析标识出用例,再建模。
9、需求定义可按照目标->问题->可选方案->建议方案来进行
10、问题定义过程中寻找本源需要深刻理解《你的灯还亮着吗?》中的隐喻。即需要思考确定解决方案时是否会引发新问题,务必直接修改错误,不要用其他方案来弥补错误。
11、常用的业务流程+管理形式的主题域划分方式是基于“物”的线索的,这样划分在进行需求捕获和分析时就会发现各个子系统和模块与客户部门是交错在一起的,每个模块都需要对不同的部门进行调研,这只是一种逻辑划分,并没有很好体现业务结构。
12、需求捕获过程中不仅仅需要捕获意识到的需求,还要捕获无意识的需求,如果在捕获到未梦想的需求就更好了。
13、需求分析人员需要尝试理解业务场景,并需要处理客户言过其实、越俎代庖、非正事、抗拒、推卸责任等心理,分别采取多人访谈找差异、识别正确访谈者、离开办公室或对访谈进行计划、倾听抱怨、让被访谈者介绍工作场景方法来化解这类心理活动造成的阻碍。
14、客户如果提出解决方案,需要多问一次为什么需要这样,以找到问题的本质。
15、用户访谈中被访谈者建议包括四类:高层管理人员、中层管理人员、操作层、技术团队,分别在需求定义、需求捕获阶段
16、业务流程分析过程中应该以部门级作为主线索,并针对岗位级进行细化,针对组织级进行抽象概括。
17、流程通常分为三类:生产性流程、管理性流程、支持性流程。
18、流程分析完毕之后需要进行瓶颈和利益分析,一般需要消除瓶颈
19、业务实体分析过程中除非十分熟悉ER图,否则建议采用类图,这里的类图并不等价于开发过程中的类图,而是类型图的意思。
20、需求建模时,使用类图过程中应该大胆使用中文来表示类名和属性名,但不必像设计阶段那样添加很多辅助建模元素。
21、领域建模过程中广泛采用“名词动词法来标识类。
22、导航性、角色名、导出属性、限定符、约束等修饰属性需要根据类图情况来确定是否需要加入。
23、领域建模过程中不要考虑成员方法,行为需求应该放到流程图和用例图中描述,确定类的操作属于设计范畴无需对客户明示;不要先去明确关联的多重性;不要考虑业务类的通用性;不要过度分析名词和动词;不要过多讨论聚合和组合表示;不要将类的名称弄得难以理解,需要直观;不要关心友元关系和参数化等具体实现;不要先直接映射到数据库表结构;忘记设计模式;不要过早合并子类;不要分拆大类;不要过早抽象同类。拒绝实现、保持简单、忠于问题域。
24、概念模型(设计)和物理模型(设计)区分:概念模型(设计)属于需求视图,物理模型(设计)属于开发视图。
25、用例图仅仅是一个针对用例描述的目录,用例描述是封装所有需求的形式。
26、用例图中参与者多半可以用角色替代,但不仅仅由人承担,参与者可能是其他系统、硬件设备、时钟等。
27、CRUD动作名词和业务名词在用例名称一起使用时需要仔细注意是否会掩盖实际用例。
28、用例命名建议采用业务动词命名,避免系统动词加业务名词方式,但对系统创建的东西则不尽然。
29、采用基本事件、扩展事件、子事件的方式来描述会比冗长的if else描述要好多。
30、界面原型不应该是解决方案,应该是客户对业务的要求和约束,应该是需求人员的实现建议;开发人员不应该画地为牢,界面原型目的是支持有效的UI设计。