linux 系统监控、诊断工具之 IO wait - leejun_2005的个人页面 - 开源中国社区
1、问题:
最近在做日志的实时同步,上线之前是做过单份线上日志压力测试的,消息队列和客户端、本机都没问题,但是没想到上了第二份日志之后,问题来了:
集群中的某台机器 top 看到负载巨高,集群中的机器硬件配置一样,部署的软件都一样,却单单这一台负载有问题,初步猜测可能硬件有问题了。
同时,我们还需要把负载有异常的罪魁祸首揪出来,到时候从软件、硬件层面分别寻找解决方案。
2、排查:
从 top 中可以看到 load average 偏高,%wa 很高,%us 偏低:
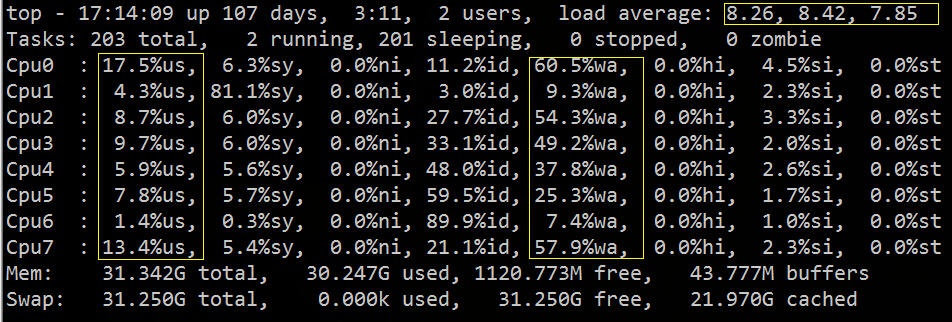
从上图我们大致可以推断 IO 遇到了瓶颈,下面我们可以再用相关的 IO 诊断工具,具体的验证排查下。
PS:如果你对 top 的用法不了解,请参考我去年写的一篇博文:
常用组合方式有如下几种:
- 用vmstat、sar、iostat检测是否是CPU瓶颈
- 用free、vmstat检测是否是内存瓶颈
- 用iostat、dmesg 检测是否是磁盘I/O瓶颈
- 用netstat检测是否是网络带宽瓶颈
2.1 vmstat
vmstat命令的含义为显示虚拟内存状态(“Viryual Memor Statics”),但是它可以报告关于进程、内存、I/O等系统整体运行状态。

它的相关字段说明如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
Procs(进程)• r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)• b: 等待IO的进程数量,也就是处在非中断睡眠状态的进程数,展示了正在执行和等待CPU资源的任务个数。当这个值超过了CPU数目,就会出现CPU瓶颈了Memory(内存)• swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。• free: 空闲物理内存大小。• buff: 用作缓冲的内存大小。• cache: 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。Swap• si: 每秒从交换区写到内存的大小,由磁盘调入内存。• so: 每秒写入交换区的内存大小,由内存调入磁盘。注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。IO(现在的Linux版本块的大小为1kb)• bi: 每秒读取的块数• bo: 每秒写入的块数注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。system(系统)• in: 每秒中断数,包括时钟中断。• cs: 每秒上下文切换数。注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。CPU(以百分比表示)• us: 用户进程执行时间百分比(user time)us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。• sy: 内核系统进程执行时间百分比(system time)sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。• wa: IO等待时间百分比wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。• id: 空闲时间百分比 |
2.2 iostat
下面再用更加专业的磁盘 IO 诊断工具来看下相关统计数据。
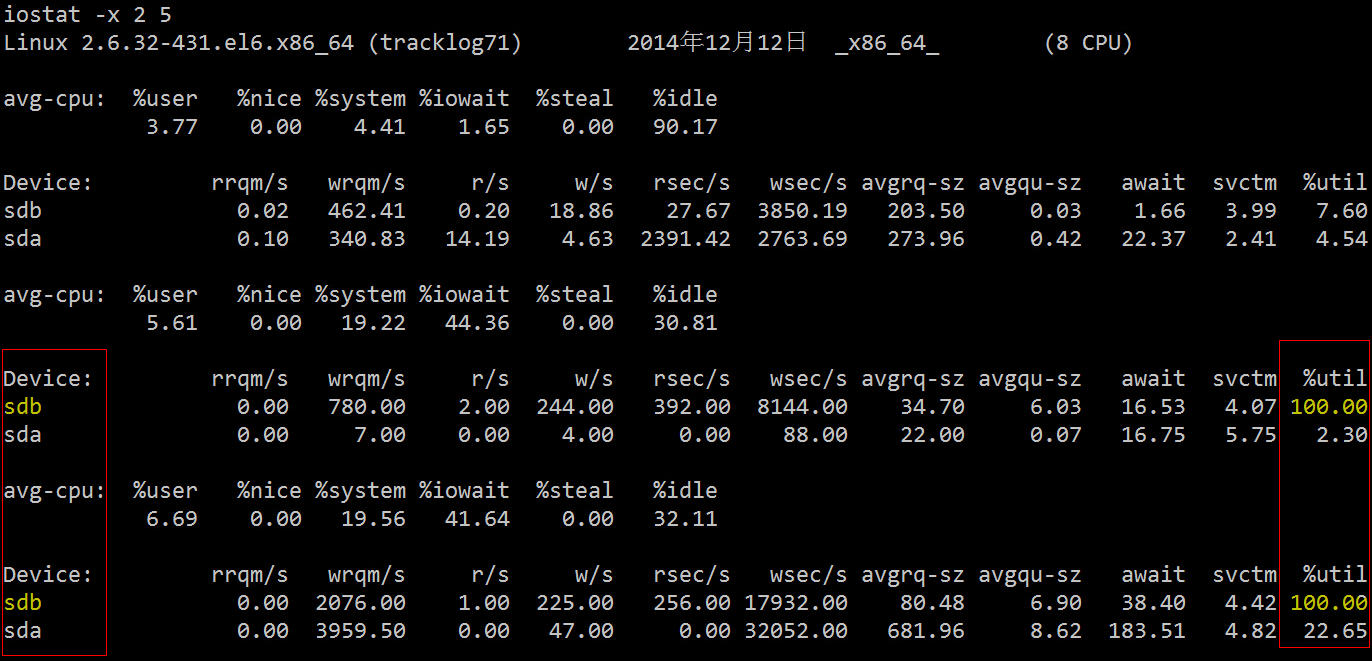
它的相关字段说明如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/swrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/sr/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/sw/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/srsec/s: 每秒读扇区数。即 delta(rsect)/swsec/s: 每秒写扇区数。即 delta(wsect)/srkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒) |
可以看到两块硬盘中的 sdb 的利用率已经 100%,存在严重的 IO 瓶颈,下一步我们就是要找出哪个进程在往这块硬盘读写数据。
2.3 iotop
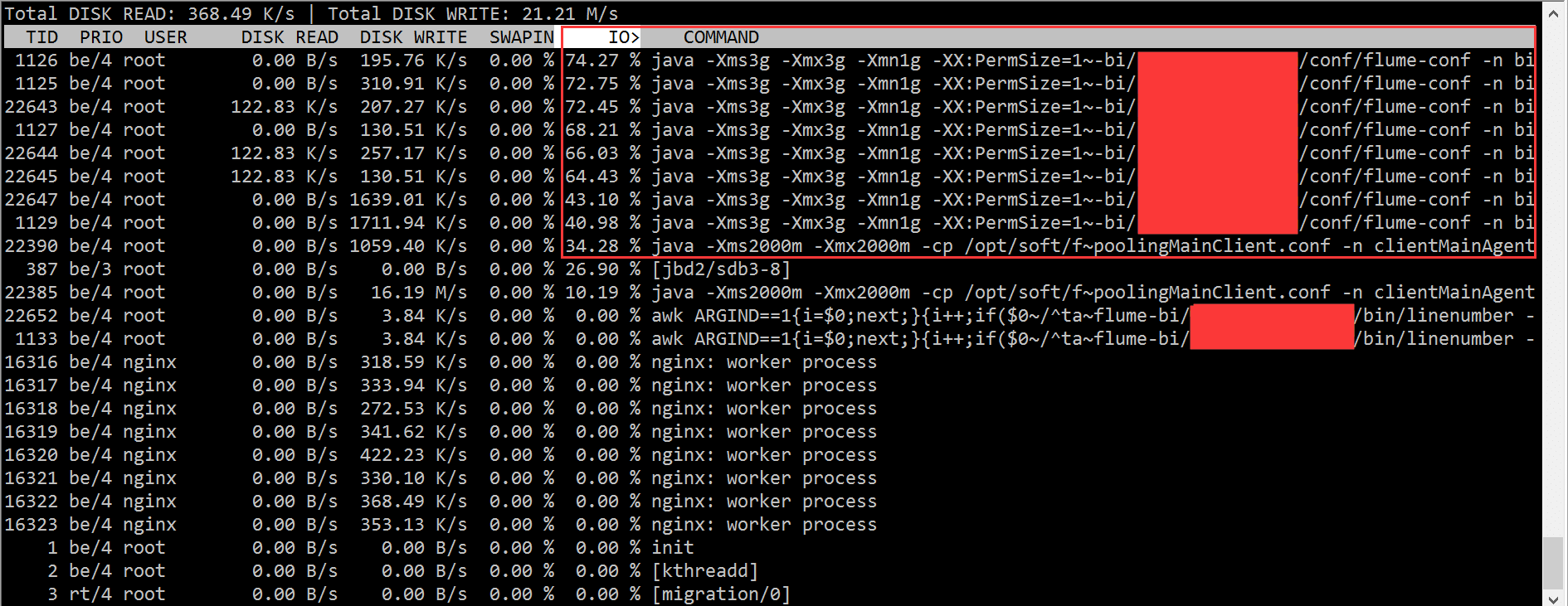
根据 iotop 的结果,我们迅速的定位到是 flume 进程的问题,造成了大量的 IO wait。
但是在开头我已经说了,集群中的机器配置一样,部署的程序也都 rsync 过去的一模一样,难道是硬盘坏了?
这得找运维同学来查证了,最后的结论是:
Sdb为双盘raid1,使用raid卡为“LSI Logic / Symbios Logic SAS1068E”,无cache。近400的IOPS压力已经达到了硬件极限。而其它机器使用的raid卡是“LSI Logic / Symbios Logic MegaRAID SAS 1078”,有256MB cache,并未达到硬件瓶颈,解决办法是更换能提供更大IOPS的机器,比如最后我们换了一台带 PERC6/i 集成RAID控制器卡的机器。需要说明的是,raid信息是在raid卡和磁盘固件里面各存一份,磁盘上的raid信息和raid卡上面的信息格式要是匹配的,否则raid卡识别不了就需要格式化磁盘。
IOPS本质上取决于磁盘本身,但是又很多提升IOPS的方法,加硬件cache、采用RAID阵列是常用的办法。如果是DB那种IOPS很高的场景,现在流行用SSD来取代传统的机械硬盘。
不过前面也说了,我们从软硬件两方面着手的目的就是看能否分别寻求代价最小的解决方案:
知道硬件的原因了,我们可以尝试把读写操作移到另一块盘,然后再看看效果:

3、最后的话:另辟蹊径
其实,除了用上述专业的工具定位这个问题外,我们可以直接利用进程状态来找到相关的进程。
我们知道进程有如下几种状态:
|
1
2
3
4
5
6
7
8
|
PROCESS STATE CODES D uninterruptible sleep (usually IO) R running or runnable (on run queue) S interruptible sleep (waiting for an event to complete) T stopped, either by a job control signal or because it is being traced. W paging (not valid since the 2.6.xx kernel) X dead (should never be seen) Z defunct ("zombie") process, terminated but not reaped by its parent. |
其中状态为 D 的一般就是由于 wait IO 而造成所谓的”非中断睡眠“,我们可以从这点入手然后一步步的定位问题:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
for x in `seq 10`; do ps -eo state,pid,cmd | grep "^D"; echo "----"; sleep 5; done D 248 [jbd2/dm-0-8] D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp ---- D 22 [kdmflush] D 16528 bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp ----# 或者:while true; do date; ps auxf | awk '{if($8=="D") print $0;}'; sleep 1; done Tue Aug 23 20:03:54 CLT 2011 root 302 0.0 0.0 0 0 ? D May22 2:58 \_ [kdmflush] root 321 0.0 0.0 0 0 ? D May22 4:11 \_ [jbd2/dm-0-8] Tue Aug 23 20:03:55 CLT 2011 Tue Aug 23 20:03:56 CLT 2011cat /proc/16528/io rchar: 48752567 wchar: 549961789 syscr: 5967 syscw: 67138 read_bytes: 49020928 write_bytes: 549961728 cancelled_write_bytes: 0 lsof -p 16528 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME bonnie++ 16528 root cwd DIR 252,0 4096 130597 /tmp <truncated> bonnie++ 16528 root 8u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 9u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 10u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 11u REG 252,0 501219328 131869 /tmp/Bonnie.16528 bonnie++ 16528 root 12u REG 252,0 501219328 131869 <strong>/tmp/Bonnie.16528</strong> df /tmp Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/workstation-root 7667140 2628608 4653920 37% / fuser -vm /tmp USER PID ACCESS COMMAND /tmp: db2fenc1 1067 ....m db2fmp db2fenc1 1071 ....m db2fmp db2fenc1 2560 ....m db2fmp db2fenc1 5221 ....m db2fmp |
4、Refer:
[1] Troubleshooting High I/O Wait in Linux
——A walkthrough on how to find processes that are causing high I/O Wait on Linux Systems
http://bencane.com/2012/08/06/troubleshooting-high-io-wait-in-linux/
[2] 理解Linux系统负荷
http://www.ruanyifeng.com/blog/2011/07/linux_load_average_explained.html
[3] 24 iostat, vmstat and mpstat Examples for Linux Performance Monitoring
http://www.thegeekstuff.com/2011/07/iostat-vmstat-mpstat-examples/
[4] vmstat vmstat命令
http://man.linuxde.net/vmstat
[5] Linux vmstat命令实战详解
http://www.cnblogs.com/ggjucheng/archive/2012/01/05/2312625.html
[6] 影响Linux服务器性能的因素
http://www.rocklv.net/2004/news/article_284.html
[7] linux磁盘IO查看iostat,vmstat
http://blog.csdn.net/qiudakun/article/details/4699587
[8] What Process is using all of my disk IO
http://stackoverflow.com/questions/488826/what-process-is-using-all-of-my-disk-io
[9] Linux Wait IO Problem
http://www.chileoffshore.com/en/interesting-articles/126-linux-wait-io-problem
[10] Tracking Down High IO Wait in Linux
http://ostatic.com/blog/tracking-down-high-io-wait-in-linux
[11] 磁盘IOPS计算与测量
http://blog.csdn.net/liuaigui/article/details/6168186
[12] [DOC]磁盘性能指标—IOPS - Huawei
[13] RAID卡
拼写纠错设计 - quweiprotoss的日志 - 网易博客
一.计划解决的问题
1. 繁简转换
2. 拼音转汉字
3. 同音词拼写错误
4. 英文拼写错误
5. 形近词错误
6. 方言纠错
二. 核心思路
1. 繁体转简体是可以独立出来,最先处理。
2. 其它的4步从查询日志中找出纠错的候选查询词,全部在线下计算。
多数拼写纠错算法基于2 个基本原则(Introduction to IR 3.3.1节):
1. 在多个拼写纠错的可选结果中,选择与原term 最相似的一个,当然这就要求有一个相似的标准。
2. 当两个候选term 与要纠错的term 一样相似时,选择最常见的那个term,比如,grunt和grant,都与grnt 差不多相似,最简单的办法就是看grant 和grunt 在文档中的各出现了多少次,将出现次数多的返回。另一种更常见的做法是把用户最常搜索的查询返回。再讨论一下纠错的功能如何展示的方案:
数据的问题:
要进行纠错,首先要确定什么是正确的查询,最简单的想法就是确定一个阈值,比如说前80%的搜索查询算是正确的搜索词,但这有一个问题,比如在Introduction to IR里的一个例子,如果很多用户不太确定一个热搜词,britney spears,很多人搜索时用的是britian spears, britney’s spears, brandy spears, prittany spears,这些词都有可能是前80%的,所以最先就要对搜索查询进行过滤后,才能认为它们是正确的,过滤的方法可以是下面介绍的方法之一。
三.具体步骤
1. 繁简转换
使用繁简转换表转换。
2. 拼音转汉字
拼音转汉字想法是较为直接的,建立一个以拼音为term的查询词索引,posting list中只保存查询频率最高的K个查询词。
|
zhijiucaotang |
子九草堂, 子久草堂 |
|
xufuniuza |
徐福牛杂, 许府牛杂, 徐府牛杂 |
|
shoujichongzhi |
手机冲值, 手机充值 |
这一步可以在自动提示中使用,但自动提示与它的区别是,自动提示在拼音输入了一部分的情况下也要提示,比如输入 “xufu”就要提示“许府牛杂”。
3. 同音词拼音写
同音词拼音写也基于同样的想法,但是需要一个可能出错的查询词列表,这个列表可以为借鉴于下列几种情况 (Introduction to IR 3.3.1节)
1. 以carot为例,返回有carot的文档,也返回一些包含纠错后的term carrot和torot的文档。
2. 与(1)相似,但仅当carot不在词典中时,返回纠错后的结果。
3. 与(1)相似,但仅当包含carot的文档数小于一个预定义的阈值时。
4. 当原始查询返回文档数小于预定义的阈值时,搜索引擎给出纠错后的词列表。
情况(1)相当于是对所有查询都进行纠错处理,发现那些搜索比较少的,就给出一个纠错提示,比如“天浴”搜索次数比较少,而“天娱”搜索次数比较多,那么在用户搜索“天浴”时就提示“天娱”,即使“天娱”也是一个正常的查询词。
情况(2)就是得到所以没有返回结果的查询列表。
情况(3)是一个查询它返回的文档数少于一个预定义阈值时,我认为这个是最合适的,因为文档中也可能有人把字写错,这样就有可能漏掉一些应该纠错的词,但这需要搜索引擎结合,看到底有多少返回了。
情况(4)就是我想应该用的表现形式。
4. 英文拼写错误
在lucene中已有贡献者实现了spellchecker模块,主要算法有:Jaro Winkler distance,Levenstein Distance(Edit Distance),NGram Distance。
但Lucene中的实现过于简单,使用两两比较,时间复杂性是O(n2),可以用Introduction to IR中的3.3.4节中介绍的,k-gram与编辑距离结合的方法算。
5. 形近字错误
形近字一般是用户记错了形声字,或是使用五笔的用户输入错误。在网上可以下载SunWb_mb文件,它里面包含五笔的编码和笔画的编码,但字根比如“马”比“口”笔画更多,也更有代表性,但在这种方法中却是相同的。
6. 方言纠错
可以用soudex进行纠错,Introduction to IR 3.4节。
使用lsof处理文件恢复、句柄以及空间释放问题 - SegmentFault
曾经在生产上遇到过一个df 和 du出现的结果不一致的问题,为了排查到底是哪个进程占用了文件句柄,导致空间未释放,首先在linux上面,一切皆文件,这个问题可以使用lsof这个BT的命令来处理(这个哈还可以来查询文件句柄泄露问题,应用程序的进程未关闭文件句柄)
1.文件句柄以及空间释放问题
- 注:在生产环境常见的问题就是,有维护人员或者开发同事使用tail命令实时查看日志。然后另外的人使用rm命令删除,这有就好导致磁盘空间不会真正的释放,因为你要删除的文件,还有进程在使用,文件句柄没有释放,即tail
模拟场景1:
你创建一个文件testfile
touch testfile 然后使用tail命令一直查看
tail testfile 这个时候另外一个同事使用rm命令来删除了该文件
rm testfile 正式使用lsof命令排查
如果你知道文件名,那就可以直接使用如下命令
lsof |grep testfile 但是如果你不知道是哪个文件,或者是很多文件都有这样的情况,那你需要使用如下命令
lsof |grep deleted 注:这个deleted表示该已经删除了的文件,但是文件句柄未释放,这个命令会把所有的未释放文件句柄的进程列出来 注:有些系统你没有配置环境变量的话,直接lsof是会报错没有该命令,你可以直接/usr/bin/lsof 或者是/usr/sbin/lsof,根据你的系统环境自己查看
然后上面命令出来的结果会出来如下结果
root 123 12244 0 14:47 pts/1 01:02:03 tail testfile 然后你可以使用kill 命令来释放文件句柄从而释放空间
kill 123 2. 文件恢复问题
在说明问题之前,先介绍下一些文件的基本概念:
- 文件实际上是一个指向inode的链接, inode链接包含了文件的所有属性, 比如权限和所有者, 数据块地址(文件存储在磁盘的这些数据块中). 当你删除(rm)一个文件, 实际删除了指向inode的链接, 并没有删除inode的内容. 进程可能还在使用. 只有当inode的所有链接完全移去, 然后这些数据块将可以写入新的数据.
- proc文件系统可以协助我们恢复数据. 每一个系统上的进程在/proc都有一个目录和自己的名字, 里面包含了一个fd(文件描述符)子目录(进程需要打开文件的所有链接). 如果从文件系统中删除一个文件, 此处还有一个inode的引用:
/proc/进程号/fd/文件描述符 - 你需要知道打开文件的进程号(pid)和文件描述符(fd). 这些都可以通过lsof工具方便获得, lsof的意思是”list open files, 列出(进程)打开的文件”. 然后你将可以从/proc拷贝出需要恢复的数据.
1.创建一个测试文件并且备份下,方面后续验证
touch testfile cp testfile testfile.backup.2014 2.查看文件的相关信息
stat testfile File: 'testfile' Size: 343545 Blocks: 241 IO Block: 4096 regular file Device: fd00h/64768d Inode: 361579 Links: 1 Access: (0664/-rw-rw-r–) Uid: ( 505/ zhaoke) Gid: ( 505/ zhaoke) Access: 2014-11-09 15:00:38.000000000 +0800 Modify: 2014-11-09 15:00:34.000000000 +0800 Change: 2014-04-09 15:00:34.000000000 +0800 没问题, 继续下面工作:
3.删除文件
rm testfile 4.查看文件
ls -l testfile ls: testfile: No such file or directory stat testfile stat: cannot stat 'testfile': No such file or directory testfile文件删除了,但不要终止仍在使用文件的进程, 因为一旦终止, 文件将很难恢复.
现在我们开始找回数据之旅,先使用lsof命令查看下
lsof | grep testfile tail 5317 root 4r REG 253,0 343545 361579 /root/testfile (deleted) -
第一个纵行是进程的名称(命令名), 第二纵行是进程号(PID), 第四纵行是文件描述符
-
现在你知道5317进程仍有打开文件, 文件描述符是4. 那我们开始从/proc里面拷贝出数据.
-
你可能会考虑使用cp -a, 但实际上没有作用, 你将拷贝的是一个指向被删除文件的符号链接:
ls -l /proc/5317/fd/4 lr-x—— 1 root root 64 09 15:00 /proc/5317/fd/4 -> /root/testfile (deleted) 使用cp -a命令测试恢复
cp -a /proc/5317/fd/4 testfile.backup 使用ls命令来查看
ls -l testfile.backup lrwxrwxrwx 1 root root 29 09 15:02 testfile.backup -> /roor/testfile (deleted) 通过上面的命令我们发现,使用cp -a命令,其恢复的是一个指向被删除文件的符号链接
使用file命令分别查看文件和文件描述符
- 1.查看文件
file testfile.backup testfile.backup: broken symbolic link to '/root/testfile (deleted)' - 2.查看文件描述符
file /proc/5317/fd/4 /proc/5317/fd/4: broken symbolic link to '/root/myfile (deleted)' 根据上面的file结果,可以使用cp拷贝出文件描述符数据到一个文件中,如下:
cp /proc/5317/fd/4 testfile.new 使用上面的命令恢复后,我们需要最终确认一下文件是否恢复,以及文件内容是否正确:
ls -l testfile.new 然后把新旧的两个文件对比
diff testfile.new myfile.backup