开源ETL工具kettle系列之增量更新设计技巧 - 技术门户 | ITPUB |
ETL中增量更新是一个比较依赖与工具和设计方法的过程,Kettle中主要提供Insert / Update 步骤,Delete 步骤和Database Lookup 步骤来支持增量更新,增量更新的设计方法也是根据应用场景来选取的,虽然本文讨论的是Kettle的实现方式,但也许对其他工具也有一些帮助。本文不可能涵盖所有的情况,欢迎大家讨论。
应用场景
增量更新按照数据种类的不同大概可以分成:
1. 只增加,不更新,
2. 只更新,不增加
3. 即增加也更新
4. 有删除,有增加,有更新
其中1 ,2, 3种大概都是相同的思路,使用的步骤可能略有不同,通用的方法是在原数据库增加一个时间戳,然后在转换之后的对应表保留这个时间戳,然后每次抽取数据的时候,先读取这个目标数据库表的时间戳的最大值,把这个值当作参数传给原数据库的相应表,根据这个时间戳来做限定条件来抽取数据,抽取之后同样要保留这个时间戳,并且原数据库的时间戳一定是指定默认值为sysdate当前时间(以原数据库的时间为标准),抽取之后的目标数据库的时间戳要保留原来的时间戳,而不是抽取时候的时间。
对于第一种情况,可以使用Kettle的Insert / Update 步骤,只是可以勾选Don’t perform any update选项,这个选项可以告诉Kettle你只会执行Insert 步骤。
对于第二种情况可能比较用在数据出现错误然后原数据库有一些更新,相应的目标数据库也要更新,这时可能不是更新所有的数据,而是有一些限定条件的数据,你可以使用Kettle的Update 步骤来只执行更新。关于如何动态的执行限定条件,可以参考前一篇文章。
第三种情况是最为常见的一种情况,使用的同样是 Kettle的Insert / Update 步骤,只是不要勾选Don’t perform any update 选项。
第四种情况有些复杂,后面专门讨论。
对于第1,2,3种情况,可以参考下面的例子。
这个例子假设原数据库表为customers , 含有一个id , firstname , lastname , age 字段,主键为id , 然后还加上一个默认值为sysdate的时间戳字段。转换之后的结果类似:id , firstname , lastname , age , updatedate . 整个设计流程大概如下:
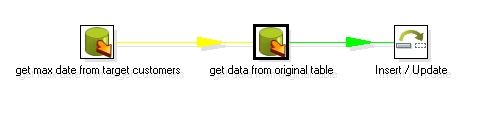
图1
其中第一个步骤的sql 大概如下模式:
Select max(updatedate) from target_customer ;
你会注意到第二个步骤和第一个步骤的连接是黄色的线,这是因为第二个table input 步骤把前面一个步骤的输出当作一个参数来用,所有Kettle用黄色的线来表示,第二个table input 的sql 模式大概如下:
Select field1 , field2 , field3 from customers where updatedate > ?
后面的一个问号就是表示它需要接受一个参数,你在这个table input 下面需要指定replace variable in script 选项和execute for each row 为选中状态,这样,Kettle就会循环执行这个sql , 执行的次数为前面参数步骤传入的数据集的大小。
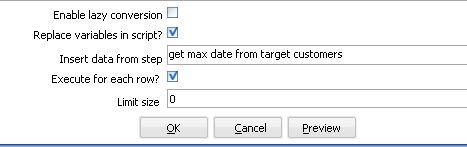
图2
关于第三个步骤执行insert / update 步骤需要特别解释一下,
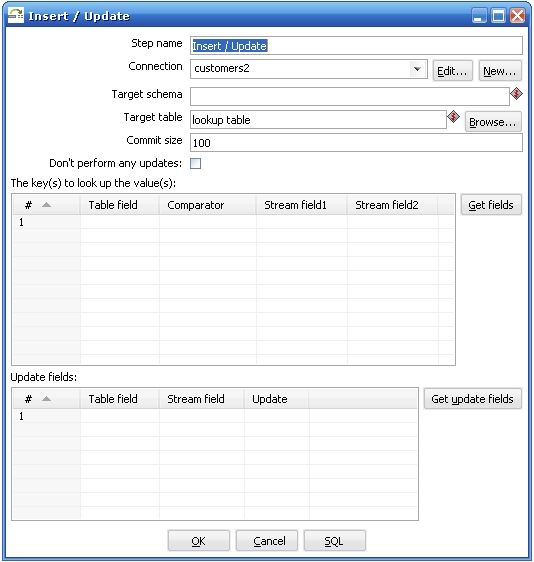
图3
Kettle执行这个步骤是需要两个数据流对比,其中一个是目标数据库,你在Target table 里面指定的,它放在The keys to look up the values(s) 左边的Table field 里面的,另外一个数据流就是你在前一个步骤传进来的,它放在The keys to look up the value(s) 的右边,Kettle首先用你传进来的key 在数据库中查询这些记录,如果没有找到,它就插入一条记录,所有的值都跟你原来的值相同,如果根据这个key找到了这条记录,kettle会比较这两条记录,根据你指定update field 来比较,如果数据完全一样,kettle就什么都不做,如果记录不完全一样,kettle就执行一个update 步骤。所以首先你要确保你指定的key字段能够唯一确定一条记录,这个时候会有两种情况:
1.维表
2.事实表
维表大都是通过一个主键字段来判断两条记录是否匹配,可能我们的原数据库的主键记录不一定对应目标数据库中相应的表的主键,这个时候原数据库的主键就变成了业务主键,你需要根据某种条件判断这个业务主键是否相等,想象一下如果是多个数据源的话,业务主键可能会有重复,这个时候你需要比较的是根据你自定义生成的新的实际的主键,这种主键可能是根据某种类似与sequence 的生成方式生成的,
事实表在经过转换之后,进目标数据库之前往往都是通过多个外键约束来确定唯一一条记录的,这个时候比较两条记录是否相等都是通过所有的维表的外键决定的,你在比较了记录相等或不等之后,还要自己判断是否需要添加一个新的主键给这个新记录。
上面两种情况都是针对特定的应用的,如果你的转换过程比较简单,只是一个原数据库对应一个目标数据库,业务主键跟代理主键完全相同的时候完全可以不用考虑这么多。
有删除,有增加,有更新
首先你需要判断你是否在处理一个维表,如果是一个维表的话,那么这可能是一个SCD情况,可以使用Kettle的Dimension Lookup 步骤来解决这个问题,如果你要处理的是事实表,方法就可能有所不同,它们之间的主要区别是主键的判断方式不一样。
事实表一般都数据量很大,需要先确定是否有变动的数据处在某一个明确的限定条件之下,比如时间上处在某个特定区间,或者某些字段有某种限定条件,尽量最大程度的先限定要处理的结果集,然后需要注意的是要先根据id 来判断记录的状态,是不存在要插入新纪录,还是已存在要更新,还是记录不存在要删除,分别对于id 的状态来进行不同的操作。
处理删除的情况使用Delete步骤,它的原理跟Insert / Update 步骤一样,只不过在找到了匹配的id之后执行的是删除操作而不是更新操作,然后处理Insert / Update 操作,你可能需要重新创建一个转换过程,然后在一个Job 里面定义这两个转换之间的执行顺序。
如果你的数据变动量比较大的话,比如超过了一定的百分比,如果执行效率比较低下,可以适当考虑重新建表。
另外需要考虑的是维表的数据删除了,对应的事实表或其他依赖于此维表的表的数据如何处理,外键约束可能不太容易去掉,或者说一旦去掉了就可能再加上去了,这可能需要先处理好事实表的依赖数据,主要是看你如何应用,如果只是简单的删除事实表数据的话还比较简单,但是如果需要保留事实表相应记录,可以在维表中增加一条记录,这条记录只有一个主键,其他字段为空,当我们删除了维表数据后,事实表的数据就更新指向这条空的维表记录。
定时执行增量更新
可能有时候我们就是定时执行更新操作,比如每天或者一个星期一次,这个时候可以不需要在目标表中增加一个时间戳字段来判断ETL进行的最大时间,直接在取得原数据库的时间加上限定条件比如:
Startdate > ? and enddate < ?
或者只有一个startdate
Startdate > ? (昨天的时间或者上个星期的时间)
这个时候需要传一个参数,用get System Info 步骤来取得,而且你还可以控制时间的精度,比如到天而不是到秒的时间。
当然,你也需要考虑一下如果更新失败了怎么处理,比如某一天因为某种原因没有更新,这样可能这一天的记录需要手工处理回来,如果失败的情况经常可能发生,那还是使用在目标数据库中增加一个时间字段取最大时间戳的方式比较通用,虽然它多了一个很少用的字段。
执行效率和复杂度
删除和更新都是一项比较耗费时间的操作,它们都需要不断的在数据库中查询记录,执行删除操作或更新操作,而且都是一条一条的执行,执行效率低下也是可以预见的,尽量可能的缩小原数据集大小。减少传输的数据集大小,降低ETL的复杂程度
时间戳方法的一些优点和缺点
优点: 实现方式简单,很容易就跨数据库实现了,运行起来也容易设计
缺点: 浪费大量的储存空间,时间戳字段除ETL过程之外都不被使用,如果是定时运行的,某一次运行失败了,就有可能造成数据有部分丢失.
其他的增量更新办法:
增量更新的核心问题在与如何找出自上次更新以后的数据,其实大多数数据库都能够有办法捕捉这种数据的变化,比较常见的方式是数据库的增量备份和数据复制,利用数据库的管理方式来处理增量更新就是需要有比较好的数据库管理能力,大多数成熟的数据库都提供了增量备份和数据复制的方法,虽然实现上各不一样,不过由于ETL的增量更新对数据库的要求是只要数据,其他的数据库对象不关心,也不需要完全的备份和完全的stand by 数据库,所以实现方式还是比较简单的.,只要你创建一个与原表结构类似的表结构,然后创建一个三种类型的触发器,分别对应insert , update , delete 操作,然后维护这个新表,在你进行ETL的过程的时候,将增量备份或者数据复制停止,然后开始读这个新表,在读完之后将这个表里面的数据删除掉就可以了,不过这种方式不太容易定时执行,需要一定的数据库特定的知识。如果你对数据的实时性要求比较高可以实现一个数据库的数据复制方案,如果对实时性的要求比较低,用增量备份会比较简单一点。
几点需要注意的地方:
1.触发器
无论是增量备份还是数据复制,如果原表中有触发器,在备份的数据库上都不要保留触发器,因为我们需要的不是一个备份库,只是需要里面的数据,最好所有不需要的数据库对象和一些比较小的表都不用处理。
2.逻辑一致和物理一致
数据库在数据库备份和同步上有所谓逻辑一致和物理一致的区别,简单来说就是同一个查询在备份数据库上和主数据库上得到的总的数据是一样的,但是里面每一条的数据排列方式可能不一样,只要没有明显的排序查询都可能有这种情况(包括group by , distinct , union等 ),而这可能会影响到生成主键的方式,需要注意在设计主键生成方式的时候最好考虑这一点,比如显式的增加order 排序. 避免在数据出错的时候,如果需要重新读一遍数据的时候主键有问题.
总结
增量更新是ETL中一个常见任务,对于不同的应用环境可能采用不同的策略,本文不可能覆盖所有的应用场景,像是多个数据源汇到一个目标数据库,id生成策略,业务主键和代理主键不统一等等,只是希望能给出一些思路处理比较常见的情况,希望能对大家有所帮助。
相关文章:
开源ETL工具kettle系列之建立缓慢增长维
http://tech.cms.it168.com/db/2008-03-21/200803211716994.shtml
开源ETL工具kettle系列之动态转换
http://tech.cms.it168.com/o/2008-03-17/200803171550713.shtml
开源ETL工具kettle系列之在应用程序中集成
http://tech.it168.com/db/2008-03-19/200803191510476.shtml
开源ETL工具kettle系列之常见问题
http://tech.it168.com/db/2008-03-19/200803191501671.shtml
Web services performance tuning - jboss web services - JBoss application server tutorials
web service performance tip #1
Use coarse grained web services
One of the biggest mistakes that many developers make when approaching web services is defining operations and messages that are too fine-grained. By doing so, developers usually define more than they really need. You need to ensure that your web service is coarse-grained and that the messages being defined are business oriented and not programmer's oriented.
The reason why top-down webservices are the pure web services is really this: you define at first the business and then the programming interface.
Don't define a web service operation for every Java method you want to expose. Rather, you should define an operation for each action you need to expose.
and this is a coarse grained web service:
for the sake of simplicity we don't have added any transaction commit/rollback however what we want to stress is that the first kind of web service is a bad design practice at first and then also will yield poor performance because of 3 round trips to the server carrying SOAP packets.
web service performance tip #2
Use primitive types, String or simple POJO as parameters and return type
Web services have been defined from the grounds up to be interoperable components. That is you can return both primitive types and Objects. How do a C# client is able to retrieve a Java type returned by a Web Service or viceversa ? that's possible because the Objects moving from/to the Webservices are flattened into XML.
As you can imagine the size of the Object which is the parameter or the returntype has a huge impact on the performance. Be careful with Objects which contain large Collections as fields- they are usually responsible of web services bad performance. If you have collections or fields which are not useful in your response mark them as transient fields.
webservice performance tip #3
Evaluate carefully how much data your need to return
Consider returning only subsets of data if the Database queries are fast but the graph of Object is fairly complex. Example:
On the other hand if your bottleneck is the Database Connectivity reduce the trips to the Service and try to return as much data as possible.
web service performance tip #4
Examine the SOAP packet
This tip is the logic continuation of the previous one: if you are dealing with complex Object types always check what is actually moving around the network. There are many ways to sniff a SOAP packet, from a tcp-proxy software which analyze the packets between two destinations. For example Apache delivers a simple tcp-monitoring utility which can be used for this purpose :
http://ws.apache.org/commons/tcpmon/
Here's how to debug SOAP messages with jboss:
http://www.mastertheboss.com/en/jboss-howto/49-jboss-http/178-how-to-monitor-webservices-soap-messages-.html
web service performance tip #5
Cache on the client when possible
If your client application requests the same information repeatedly from the server, you'll eventually realize the server's performance, and consequently your application's response time, is not fast enough.
Depending on the frequency of the messaging and the type of data, it could be necessary to cache data on the client.
This approach however needs to address one important issue: how do we know that the data we are requesting is consistent ? the technical solution to this is inverting the order of elements: when the Data in our RDBMS has become inconsistent a Notification needs to be issued so that the Client cache is refreshed. In this article you'll find an elegant approach to this topic.
http://www.javaworld.com/javaworld/jw-03-2002/jw-0308-soap.html?page=2
web service performance tip #6
Evaluate asynchronous messaging model
In some situations, responses to Web service requests are not provided immediately, but rather sometime after the initial request transactions complete. This might be due to the fact that the transport is slow and/or unreliable, or the processing is complex and/or long-running. In this situation you should consider an asynchronous messaging model.
The new WebService framework, JAX-WS, supports two models for asynchronous request-response messaging: polling and callback. Polling enables client code to repeatedly check a response object to determine whether a response has been received. Alternatively, the callback approach defines a handler that processes the response asynchronously when it is available.
Consider using asynchronous Web methods is particularly useful if you perform I/O-bound operations such as:
- Accessing streams
- File I/O operations
- Calling another Web service
In the this article I showed how to achieve asynchronous web services using JAX-WS 2.0
http://www.mastertheboss.com/en/web-interfaces/111-asynchronous-web-services-with-jboss-ws.html
web service performance tip #6
Use JAX-WS web services
The Webservices based on JAX-WS perform much better then JAX-RPC earlier Web services.
This is due to the fact that JAX-WS use JAXB for data type marshalling/unmarshalling which has a significant performance advantage over DOM based parsers.
For a detailed comparison benchmark check here:
http://java.sun.com/developer/technicalArticles/WebServices/high_performance/
webservice performance tip #7
Do you need RESTful web services ?
RESTful web services are stateless client-server architecture in which the web services are viewed as resources and can be identified by their URLs.
REST as a protocol does not define any form of message envelope, while SOAP does have this standard. So at first you don't have the overhead of headers and additional layers of SOAP elements on the XML payload. That's not a big thing, even if for limited-profile devices such as PDAs and mobile phones it can make a difference.
However the real performance difference does not rely on wire speed but with cachability. REST suggests using the web's semantics instead of trying to tunnel over it via XML, so RESTful web services are generally designed to correctly use cache headers, so they work well with the web's standard infrastructure like caching proxies and even local browser caches.
RESTFUL web services are not a silver bullet, they are adviced in these kind of scenarios:
REST web services are a good choices when your web services are completely stateless.Since there is no formal way to describe the web services interface, it's required that the service producer and service consumer have a mutual understanding of the context and content being passed along.
On the other hand a SOAP-based design may be appropriate when a formal contract must be established to describe the interface that the web service offers. The Web Services Description Language (WSDL) describes the details such as messages, operations, bindings, and location of the web service. Another scenario where it's mandatory to use SOAP based web services is an architecture that needs to handle asynchronous processing and invocation.
web service performance tip #8
Eager initialization
JBossWS may perform differently during the first method invocation of each service and the following ones when huge wsdl contracts (with hundreds of imported xml schemas) are referenced. This is due to a bunch of operations performed internally during the first invocation whose resulting data is then cached and reused during the following ones. While this is usually not a problem, you might be interested in having almost the same performance on each invocation. This can be achieved setting the org.jboss.ws.eagerInitializeJAXBContextCache system property to true, both on server side (in the JBoss start script) and on client side (a convenient constant is available in org.jboss.ws.Constants). The JAXBContext creation is usually responsible for most of the time required by the stack during the first invocation; this feature makes JBossWS try to eagerly create and cache the JAXB contexts before the first invocation is handled.
web service performance tip #9
Use Literal Message Encoding for Parameter Formatting
The encoded formatting of the parameters in messages creates larger messages than literal message encoding (literal message encoding is the default). In general, you should use literal format unless you are forced to switch to SOAP encoding for interoperability with a Web services platform that does not support the literal format. Here's an example of an RPC/encoded SOAP message for helloWorld
Here the operation name appears in the message, so the receiver has an easy time dispatching this message to the implementation of the operation.The type encoding info (such as xsi:type="xsd:int") is usually just overhead which degrades throughput performance. And this is the equivalent Document/literal wrapped SOAP message :
Analyzing Thread Dumps in Middleware - Part 2
This posting is the second section in the series Analyzing Thread Dumps in Middleware
This section details with when, how to capture and analyze thread dumps with special focus on WebLogic Application Server related thread dumps. Subsequent sections will deal with more real-world samples and tools for automatic analysis of Thread Dumps.
The Diagnosis
Everyone must have gone through periodic health checkups. As a starting point, Doctors always order for a blood test. Why this emphasis on blood test? Can't they just go by the patient's feedback or concerns? What is special about blood test?
Blood Test help via:
- Capturing a snapshot of the overall health of the body (cells/antibodies/...)
- Detecting Abnormalities (low/high hormones, elevated blood sugar levels)
- Identifying and start focusing on the problem areas with prevention and treatment.
The Thread Dump is the equivalent of a blood test for a JVM. It is a state dump of the running JVM and all its parts that are executing at that moment in time.
- It can help identify current execution patterns and help focus attention on relevant parts
- There might be 100s of components and layers but difficult to identify what is getting invoked the most and where to focus attention. A thread dump taken during load will highlight the most executed code paths.
- Dependencies and bottlenecks in code and application design
- Show pointers for enhancements and optimizations
When to capture Thread Dumps
Under what conditions should we capture thread dumps? Anytime or specific times? Capturing thread dumps are ideal for following conditions:
- To understand what is actively executed in the system when under load
- When system is sluggish or slow or hangs
- Java Virtual Process running but Server or App itself not responding
- Pages take forever to load
- Response time increases
- Application and or Server behavior erratic
- Just to observe hot spots (frequently executed code) under load
- For Performance tuning
- For Dependency analysis
- For bottleneck identification and resolution
- To capture snapshot of running state in server
The cost associated with capturing thread dumps is close to near zero; Java Profilers and other tools can consume anywhere from 5 to 20% overhead while a thread dump is more of a snapshot of threads which requires no real heavy weight processing on part of the JVM. There can be some cost only if there are too many interrupts to the JVM within real short intervals (like dumps forever every second or so).
How to capture Thread Dumps
There are various options to capture thread dumps. JVM vendor tools allow capture and gather of thread dumps. Operating System interrupt signals to the process can also be used in generating thread dumps.
Sun Hotspot's jstack tool (under JAVA_HOME or JRE Home/bin) can generate thread dumps given the jvm process id. Similarly, jrcmd (from JRockit Mission Control) can generate thread dumps given a jvm process id and using the print_threads command. Both require to be run on the same operating system as the jvm process and both dump the output to the user shell.
In Unix, kill -3 <PID> or kill -SIGQUIT<PID> will generate thread dumps on the JVM process. But the output of the thread dump will go to the STDERR. Unless the STDERR was redirected to a log file, the thread dump cannot be saved when issued via kill signals. Ensure the process is always started and STDERR is redirected to a log (best practice to also have STDOUT redirected to same log file as STDERR).
In Windows, Ctrl-Break to the JVM process running in foreground can generate thread dumps. The primary limitation is the process needs to be running in the shell. Process Explorer in windows can also help in generating thread dumps but its much more problematic to get all the thread stacks in one shot. One has to wade through each thread and gets its stack. Another thing to keep in mind is, JVM might ignore interrupts if they were started with -Xrs flag.
WebLogic Application Server allows capture of thread dumps via additional options:
- WLS Admin Console can generate thread dumps. Go to the Server Instance -> Monitoring -> Threads -> Dump Threads option.
- Using weblogic's WLST (WebLogic Scripting Tool) to issue Thread dumps.
- weblogic.Admin THREAD_DUMP command option
But generating thread dumps via Weblogic specific commands is not recommended as the JVM itself might be sluggish or hung and never respond to higher app level commands (including weblogic). Issuing thread dumps via the WLS Admin Console requires the Admin server to be first up and healthy and also in communication with the target server.
Sometimes, even the OS level or JVM vendor specific tools might not be able to generate thread dumps. The causes can include memory thrashing (Out Of Memory - OOM) and thread deaths in the JVM, the system itself under tough constraints (memory/cpu) or the process is unhealthy and cannot really respond to anything in predictable way.
What to Observe
Now that we can capture thread dumps, what to observe? Its always recommended to take multiple thread dumps at close intervals (5 or 6 dumps at 10-15 seconds intervals). Why? A thread dump is a snapshot of threads in execution or various states. Taking multiple thread dumps allows us to peek into the threads as they continue execution.
Compare threads based on thread id or name across successive thread dumps to check for change in execution. Observe change in thread execution across thread dumps. Change in the thread state and or stack content for a given thread across successive thread dumps implies there is progress while no change or absence of progress indicates either a warning condition or something benign.
So, what if a given thread is not showing progress between thread dumps? Its possible the thread is doing nothing and so has no change between dumps. Or its possible its waiting for an event to happen and continues in same state and stack appearance. These might be benign. Or it might be blocked for a lock and continues to languish in the same state as the owner of the lock is still holding on the same lock or someone else got the lock ahead of our target thread. Its good to figure out which of the conditions applies and rule out benign cases.
Identifying Idle or Benign threads
One can use the following as rule of thumb while analyzing Application Server side thread dumps. Some additional pointers for WebLogic Specific threads.
- If the thread stack depth is lesser than 5 or 6, treat it as an idle or benign thread. Why? By default, application server thread will itself take away 2-3 thread stack depths (like someRunnable or Executor.run) and if there is not much stack depth remaining, then its more likely sitting there for some job or condition.
"schedulerFactoryBean_Worker-48" id=105 idx=0x1e4 tid=7392 prio=5 alive, waiting, native_blocked
-- Waiting for notification on: org/quartz/simpl/SimpleThreadPool$WorkerThread@0xd5ddc168[fat lock]
at jrockit/vm/Threads.waitForNotifySignal(JLjava/lang/Object;)Z(Native Method)
at java/lang/Object.wait(J)V(Native Method)
at org/quartz/simpl/SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:519)
^-- Lock released while waiting: org/quartz/simpl/SimpleThreadPool$WorkerThread@0xd5ddc168[fat lock]
at jrockit/vm/RNI.c2java(JJJJJ)V(Native Method)
-- end of trace
"Agent ServerConnection" id=17 idx=0xa0 tid=7154 prio=5 alive, sleeping, native_waiting, daemon
at java/lang/Thread.sleep(J)V(Native Method)
at com/wily/introscope/agent/connection/ConnectionThread.sendData(ConnectionThread.java:312)
at com/wily/introscope/agent/connection/ConnectionThread.run(ConnectionThread.java:65)
at java/lang/Thread.run(Thread.java:662)
at jrockit/vm/RNI.c2java(JJJJJ)V(Native Method)
-- end of trace
"DynamicListenThread[Default]" id=119 idx=0x218 tid=7465 prio=9 alive, in native, daemon
at sun/nio/ch/ServerSocketChannelImpl.accept0(Ljava/io/FileDescriptor;Ljava/io/FileDescriptor;[Ljava/net/InetSocketAddress;)I(Native Method)
at sun/nio/ch/ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:145)
^-- Holding lock: java/lang/Object@0xbdc08428[thin lock]
at weblogic/socket/WeblogicServerSocket.accept(WeblogicServerSocket.java:30)
at weblogic/server/channels/DynamicListenThread$SocketAccepter.accept(DynamicListenThread.java:535)
at weblogic/server/channels/DynamicListenThread$SocketAccepter.access$200(DynamicListenThread.java:417)
at weblogic/server/channels/DynamicListenThread.run(DynamicListenThread.java:173)
at java/lang/Thread.run(Thread.java:662)
If its WebLogic specific thread dump,
- Ignore those threads in ExecuteThread.waitForRequest() method call.
"[ACTIVE] ExecuteThread: '3' for queue: 'weblogic.kernel.Default (self-tuning)'" id=71 idx=0x15c tid=10158 prio=9 alive, waiting, native_blocked, daemon
-- Waiting for notification on: weblogic/work/ExecuteThread@0x1755df6d8[fat lock]
at jrockit/vm/Threads.waitForNotifySignal(JLjava/lang/Object;)Z(Native Method)
at jrockit/vm/Locks.wait(Locks.java:1973)[inlined]
at java/lang/Object.wait(Object.java:485)[inlined]
at weblogic/work/ExecuteThread.waitForRequest(ExecuteThread.java:160)[optimized]
^-- Lock released while waiting: weblogic/work/ExecuteThread@0x1755df6d8[fat lock]
at weblogic/work/ExecuteThread.run(ExecuteThread.java:181)
at jrockit/vm/RNI.c2java(JJJJJ)V(Native Method)
-- end of trace
- Ensure the thread that is blocked is waiting for a lock held by another Muxer thread and not a non-Muxer Thread.
"ExecuteThread: '4' for queue: 'weblogic.socket.Muxer'" id=31 idx=0xc8 tid=8777 prio=5 alive, blocked, native_blocked, daemon
-- Blocked trying to get lock: java/lang/String@0x17674d0c8[fat lock]
at jrockit/vm/Threads.waitForUnblockSignal()V(Native Method)
at jrockit/vm/Locks.fatLockBlockOrSpin(Locks.java:1411)[optimized]
at jrockit/vm/Locks.lockFat(Locks.java:1512)[optimized]
at jrockit/vm/Locks.monitorEnterSecondStageHard(Locks.java:1054)[optimized]
at jrockit/vm/Locks.monitorEnterSecondStage(Locks.java:1005)[optimized]
at jrockit/vm/Locks.monitorEnter(Locks.java:2179)[optimized]
at weblogic/socket/EPollSocketMuxer.processSockets(EPollSocketMuxer.java:153)
at weblogic/socket/SocketReaderRequest.run(SocketReaderRequest.java:29)
at weblogic/socket/SocketReaderRequest.execute(SocketReaderRequest.java:42)
at weblogic/kernel/ExecuteThread.execute(ExecuteThread.java:145)
at weblogic/kernel/ExecuteThread.run(ExecuteThread.java:117)
at jrockit/vm/RNI.c2java(JJJJJ)V(Native Method)
-- end of trace
"ExecuteThread: '5' for queue: 'weblogic.socket.Muxer'" id=32 idx=0xcc tid=8778 prio=5 alive, native_blocked, daemon
at jrockit/ext/epoll/EPoll.epollWait0(ILjava/nio/ByteBuffer;II)I(Native Method)
at jrockit/ext/epoll/EPoll.epollWait(EPoll.java:115)[optimized]
at weblogic/socket/EPollSocketMuxer.processSockets(EPollSocketMuxer.java:156)
^-- Holding lock: java/lang/String@0x17674d0c8[fat lock]
at weblogic/socket/SocketReaderRequest.run(SocketReaderRequest.java:29)
at weblogic/socket/SocketReaderRequest.execute(SocketReaderRequest.java:42)
at weblogic/kernel/ExecuteThread.execute(ExecuteThread.java:145)
at weblogic/kernel/ExecuteThread.run(ExecuteThread.java:117)
at jrockit/vm/RNI.c2java(JJJJJ)V(Native Method)
-- end of trace
WebLogic Specific Thread Tagging
WebLogic tags threads internally as Active and Standby based on its internal workmanager and thread pooling implementation. There is another level of tagging based on a thread getting returned to the thread pool or not within a defined time period. If the thread does not get returned within a specified duration its tagged as Hogging and if it exceeds even higher limits (default of 10 minutes), its termed as STUCK. It means the thread is involved in a very long activity which requires some manual inspection.
- Its possible for pollers to get kicked off but never return as they just keep polling in an infinite loop. Examples are the AQ Adapter Poller threads which might wrongly get tagged as STUCK.These are benign in nature.
- Thread is doing a database read or remote invocation due to some user request execution and is tagged STUCK. This implies the thread has never really completed the request for more than 10 minutes and is definitely hung - its possibly doing a socket read on an endpoint that is bad or non-responsive or doing real big remote or local execution which should not be synchronous to begin with. Or it might be blocked for a resource which is part of a deadlocked chain and that might be the reason for the non-progress.
Analyzing a Thread Stack
The java thread stack content in a thread dump are always in text/ascii format enabling a quick read without any tools. Almost invariably, the thread stack is in English which lets the user read the package, classname and method call. These three apsects help us understand the general overview of the call the thread is executing, who invoked it and what it is invoking next thereby establishing the caller-callee chain as well as what is getting invoked. The method name gives us a general idea of what the invocation is about. All of these data points can show what is getting executed by the thread even if we haven't written the code or truly understand the implementation.
"[ExecuteThread: '4' for queue: 'weblogic.kernel.Default (self-tuning)'" waiting for lock weblogic.rjvm.ResponseImpl@1b1d86 WAITING
java.lang.Object.wait(Native Method)
weblogic.rjvm.ResponseImpl.waitForData(ResponseImpl.java:84)
weblogic.rjvm.ResponseImpl.getTxContext(ResponseImpl.java:115)
weblogic.rjvm.BasicOutboundRequest.sendReceive(BasicOutboundRequest.java:109)
weblogic.rmi.internal.BasicRemoteRef.invoke(BasicRemoteRef.java:223)
javax.management.remote.rmi.RMIConnectionImpl_1001_WLStub.getAttribute(Unknown Source)
weblogic.management.remote.common.RMIConnectionWrapper$11.run(ClientProviderBase.java:531)
……
weblogic.management.remote.common.RMIConnectionWrapper.getAttribute(ClientProviderBase.java:529)
javax.management.remote.rmi.RMIConnector$RemoteMBeanServerConnection.getAttribute(RMIConnector.java:857)
weblogic.management.mbeanservers.domainruntime.internal.ManagedMBeanServerConnection.getAttribute(ManagedMBeanServerConnection.java:281)
weblogic.management.mbeanservers.domainruntime.internal.FederatedMBeanServerInterceptor.getAttribute(FederatedMBeanServerInterceptor.java:227)
weblogic.management.jmx.mbeanserver.WLSMBeanServerInterceptorBase.getAttribute(WLSMBeanServerInterceptorBase.java:116)
weblogic.management.jmx.mbeanserver.WLSMBeanServerInterceptorBase.getAttribute(WLSMBeanServerInterceptorBase.java:116)
….
weblogic.management.jmx.mbeanserver.WLSMBeanServer.getAttribute(WLSMBeanServer.java:269)
javax.management.remote.rmi.RMIConnectionImpl.doOperation(RMIConnectionImpl.java:1387)
javax.management.remote.rmi.RMIConnectionImpl.access$100(RMIConnectionImpl.java:81)
……
weblogic.rmi.internal.ServerRequest.sendReceive(ServerRequest.java:174)
weblogic.rmi.internal.BasicRemoteRef.invoke(BasicRemoteRef.java:223)
javax.management.remote.rmi.RMIConnectionImpl_1001_WLStub.getAttribute(Unknown Source)
javax.management.remote.rmi.RMIConnector$RemoteMBeanServerConnection.getAttribute(RMIConnector.java:857)
javax.management.MBeanServerInvocationHandler.invoke(MBeanServerInvocationHandler.java:175)
weblogic.management.jmx.MBeanServerInvocationHandler.doInvoke(MBeanServerInvocationHandler.java:504)
weblogic.management.jmx.MBeanServerInvocationHandler.invoke(MBeanServerInvocationHandler.java:380)
$Proxy61.getName(Unknown Source)
com.bea.console.utils.DeploymentUtils.getAggregatedState(DeploymentUtils.java:507)
com.bea.console.utils.DeploymentUtils.getApplicationStatusString(DeploymentUtils.java:2042)
com.bea.console.actions.app.DeploymentsControlTableAction.getCollection(DeploymentsControlTableAction.java:181)
In the above stack trace, we can see the thread belong to the "weblogic.kernel.Default (self-tuning)" group with Thread Name as "ExecuteThread: '4'" and is waiting for a notification on a lock. Some WLS Specific observations based on the stack:
- WLS Admin Console Application attempts to get ApplicationStatus of the Deployments on the remote server.
- MBeanServer.getAttribute() implies it was call to get some attributes (in this case, the application status of deployments) from the MBean Server of a Remote WLS Server instance.
- weblogic.rjvm.ResponseImpl.waitForData() signifies the thread is waiting for a weblogic RMI response from a remote WLS server for the remote MBean Server query call.
"ACTIVE ExecuteThread: '0' for queue: 'weblogic.kernel.Default (self-tuning)'" daemon prio=10 tid=0x00002aabc9820800 nid=0x7a7d runnable 0x000000004290d000 java.lang.Thread.State: RUNNABLE at java.io.FileInputStream.readBytes(Native Method) at java.io.FileInputStream.read(FileInputStream.java:199) at sun.security.provider.NativePRNG$RandomIO.readFully(NativePRNG.java:185) at sun.security.provider.NativePRNG$RandomIO.implGenerateSeed(NativePRNG.java:202) - locked <0x00002aab7b441ee0> (a java.lang.Object) at sun.security.provider.NativePRNG$RandomIO.access$300(NativePRNG.java:108) at sun.security.provider.NativePRNG.engineGenerateSeed(NativePRNG.java:102) at java.security.SecureRandom.generateSeed(SecureRandom.java:495) at com.bea.security.utils.random.AbstractRandomData.ensureInittedAndSeeded(AbstractRandomData.java:83) - locked <0x00002aab6da12720> (a com.bea.security.utils.random.SecureRandomData) at com.bea.security.utils.random.AbstractRandomData.getRandomBytes(AbstractRandomData.java:97) - locked <0x00002aab6da12720> (a com.bea.security.utils.random.SecureRandomData) at com.bea.security.utils.random.AbstractRandomData.getRandomBytes(AbstractRandomData.java:92) at weblogic.management.servlet.ConnectionSigner.signConnection(ConnectionSigner.java:132) - locked <0x00002aaab0611688> (a java.lang.Class for weblogic.management.servlet.ConnectionSigner) at weblogic.ldap.EmbeddedLDAP.getInitialReplicaFromAdminServer(EmbeddedLDAP.java:1268) at weblogic.ldap.EmbeddedLDAP.start(EmbeddedLDAP.java:221) at weblogic.t3.srvr.SubsystemRequest.run(SubsystemRequest.java:64) at weblogic.work.ExecuteThread.execute(ExecuteThread.java:201) at weblogic.work.ExecuteThread.run(ExecuteThread.java:173)
In the above thread stack, it shows WebLogic LDAP is just starting up and is attempting to generate a Random Seed Number using the entropy of the file system. This thread can stay in the same state if there is not much activity in the file system and the server might appear hung at startup.• Solution would be to add -Djava.security.egd=file:/dev/./urandom to java command line arguments to choose a urandom entropy scheme for random number generation for Linux.
Note: this is not advisable to be used for Production systems as the random number is not that truly random.
"[ACTIVE] ExecuteThread: '32' for queue: 'weblogic.kernel.Default (self-tuning)'" daemon prio=10 tid=0x0000002c5ede5000 nid=0x2ca6 waiting for monitor entry [0x000000006a6cc000]
java.lang.Thread.State: BLOCKED (on object monitor)
at weblogic.messaging.kernel.internal.QueueImpl.addReader(QueueImpl.java:1082)
- waiting to lock <0x0000002ac75d1b80> (a weblogic.messaging.kernel.internal.QueueImpl)
at weblogic.messaging.kernel.internal.ReceiveRequestImpl.start(ReceiveRequestImpl.java:178)
at weblogic.messaging.kernel.internal.ReceiveRequestImpl.<init>(ReceiveRequestImpl.java:86)
at weblogic.messaging.kernel.internal.QueueImpl.receive(QueueImpl.java:841)
at weblogic.jms.backend.BEConsumerImpl.blockingReceiveStart(BEConsumerImpl.java:1308)
at weblogic.jms.backend.BEConsumerImpl.receive(BEConsumerImpl.java:1514)
at weblogic.jms.backend.BEConsumerImpl.invoke(BEConsumerImpl.java:1224)
at weblogic.messaging.dispatcher.Request.wrappedFiniteStateMachine(Request.java:961)
at weblogic.messaging.dispatcher.DispatcherServerRef.invoke(DispatcherServerRef.java:276)
at weblogic.messaging.dispatcher.DispatcherServerRef.handleRequest(DispatcherServerRef.java:141)
at weblogic.messaging.dispatcher.DispatcherServerRef.access$000(DispatcherServerRef.java:34)
at weblogic.messaging.dispatcher.DispatcherServerRef$2.run(DispatcherServerRef.java:111)
at weblogic.work.ExecuteThread.execute(ExecuteThread.java:201)
at weblogic.work.ExecuteThread.run(ExecuteThread.java:173)
This thread stack shows WLS adding a JMS Receiver to a Queue.
Following thread stack shows Oracle Service Bus (OSB) Http Proxy service blocked for response from an outbound web service callout and got tagged as STUCK as there was no progress for more than 10 minutes.
[STUCK] ExecuteThread: '53' for queue: 'weblogic.kernel.Default (self-tuning)'" <alive, in native, suspended, waiting, priority=1, DAEMON>
-- Waiting for notification on: java.lang.Object@7ec6c98[fat lock]
java.lang.Object.wait(Object.java:485)
com.bea.wli.sb.pipeline.PipelineContextImpl$SynchronousListener.waitForResponse()
com.bea.wli.sb.pipeline.PipelineContextImpl.dispatchSync()
stages.transform.runtime.WsCalloutRuntimeStep$WsCalloutDispatcher.dispatch()
stages.transform.runtime.WsCalloutRuntimeStep.processMessage()
com.bea.wli.sb.pipeline.StatisticUpdaterRuntimeStep.processMessage()
com.bea.wli.sb.stages.StageMetadataImpl$WrapperRuntimeStep.processMessage()
com.bea.wli.sb.stages.impl.SequenceRuntimeStep.processMessage()
com.bea.wli.sb.pipeline.PipelineStage.processMessage()
com.bea.wli.sb.pipeline.PipelineContextImpl.execute()
com.bea.wli.sb.pipeline.Pipeline.processMessage()
com.bea.wli.sb.pipeline.PipelineContextImpl.execute()
com.bea.wli.sb.pipeline.PipelineNode.doRequest()
com.bea.wli.sb.pipeline.Node.processMessage()
com.bea.wli.sb.pipeline.PipelineContextImpl.execute()
com.bea.wli.sb.pipeline.Router.processMessage()
com.bea.wli.sb.pipeline.MessageProcessor.processRequest()
com.bea.wli.sb.pipeline.RouterManager$1.run()
com.bea.wli.sb.pipeline.RouterManager$1.run()
weblogic.security.acl.internal.AuthenticatedSubject.doAs()
weblogic.security.service.SecurityManager.runAs()
com.bea.wli.sb.security.WLSSecurityContextService.runAs()
com.bea.wli.sb.pipeline.RouterManager.processMessage()
com.bea.wli.sb.transports.TransportManagerImpl.receiveMessage()
com.bea.wli.sb.transports.http.HttpTransportServlet$RequestHelper$1.run()
Identify Hot Spots
What constitutes a Hot Spot? Hot spot is a set of method calls that gets repeatedly invoked by busy running threads (not idle or dormant threads). It can be as simple healthy pattern like multiple threads executing requests to the same set of servlet or application layer or it can be a symptom of bottleneck if multiple threads are blocked waiting for the same lock.
Attempt to capture thread dumps and identify hot spots only after the server has been subjected to some decent loads by which time most of the code have been initialized and executed a few times.
For normal hot spots, try to identify possible optimizations in the code execution.
It might be that the thread is attempting to do a repeat look of JNDI resources or recreation of a resource like JMS Producer/consumer or InitialContext to a remote server.
Cache the JNDI resources, Context and producer/consumer objects. Pool the producers/consumers if possible, reuse the jms connections. Avoid repeated lookups. It can be as simple as resolving an address by doing InetAddress.getAllByName(), cache the results instead of repeat resolutions. Same way, cache XML Parsers or handlers to avoid repeat classloading of xml parsers/factories/handlers/implementations. While caching, ensure to avoid memory leaks if the instances can grow continuously.
Identify Bottlenecks
As Goldfinger says to James Bond in "Goldfinger", Once is happenstance, Twice is coincidence and the third time is enemy action when it comes to threads blocked for same lock. Start navigating the chain of the locks, and try to identify the dependencies between the threads and the nature of locking and try to resolve them as suggested in Reducing Locks Section 1 of this series.
- Identify blocked threads and dependency between the locks and the threads
- Start analyzing dependencies and try to reduce locking
- Resolve the bottlenecks.
This entire exercise can be a bit like pealing onions as one layer of bottleneck might be masking or temporarily resolving a different bottleneck. It requires repetition of analyzing, fixing, testing and analyzing.
Following the chain
Sometimes a thread blocking others from obtaining a lock might itself be on blocked list for yet another lock. In those cases, one should navigate the chain to identify who and what is blocking it. If there are deadlocks (circular dependency of locks), the JVM might report the deadlock automatically. But its best practice to navigate and understand the chains as that will help in resolving and optimizing the behavior for the better.
Let take the following thread stack. The ExecuteThread: '58' is waiting to obtain lock on the
"[STUCK] ExecuteThread: '58' for queue: 'weblogic.kernel.Default (self-tuning)'" id=131807 idx=0x90 tid=927 prio=1 alive, blocked, native_blocked, daemon
-- Blocked trying to get lock: java/util/TreeSet@0x4bba82c0[thin lock]
at jrockit/vm/Locks.monitorEnter(Locks.java:2170)[optimized]
at weblogic/common/resourcepool/ResourcePoolImpl$Group.getCheckRecord(ResourcePoolImpl.java:2369)
at weblogic/common/resourcepool/ResourcePoolImpl$Group.checkHang(ResourcePoolImpl.java:2463)
at weblogic/common/resourcepool/ResourcePoolImpl$Group.access$100(ResourcePoolImpl.java:2210)
...........
at weblogic/common/resourcepool/ResourcePoolImpl.reserveResourceInternal(ResourcePoolImpl.java:450)
at weblogic/common/resourcepool/ResourcePoolImpl.reserveResource(ResourcePoolImpl.java:329)
at weblogic/jdbc/common/internal/ConnectionPool.reserve(ConnectionPool.java:417)
at weblogic/jdbc/common/internal/ConnectionPool.reserve(ConnectionPool.java:324)
at weblogic/jdbc/common/internal/MultiPool.searchLoadBalance(MultiPool.java:312)
at weblogic/jdbc/common/internal/MultiPool.findPool(MultiPool.java:180)
at weblogic/jdbc/common/internal/ConnectionPoolManager.reserve(ConnectionPoolManager.java:89)
Search for the matching lock id among the rest of the threads. The lock is held by ExecuteThread '26' which itself is blocked fororacle/jdbc/driver/T4CConnection@0xf71f6938
...
"[STUCK] ExecuteThread: '26' for queue: 'weblogic.kernel.Default (self-tuning)'" id=1495 idx=0x354 tid=7858 prio=1 alive, blocked, native_blocked, daemon
-- Blocked trying to get lock: oracle/jdbc/driver/T4CConnection@0xf71f6938[thin lock]
at jrockit/vm/Locks.monitorEnter(Locks.java:2170)[optimized]
at oracle/jdbc/driver/OracleStatement.close(OracleStatement.java:1785)
at oracle/jdbc/driver/OracleStatementWrapper.close(OracleStatementWrapper.java:83)
at oracle/jdbc/driver/OraclePreparedStatementWrapper.close(OraclePreparedStatementWrapper.java:80)
at weblogic/jdbc/common/internal/ConnectionEnv.initializeTest(ConnectionEnv.java:940)
at weblogic/jdbc/common/internal/ConnectionEnv.destroyForFlush(ConnectionEnv.java:529)
^-- Holding lock: weblogic/jdbc/common/internal/ConnectionEnv@0xf71f6798[recursive]
at weblogic/jdbc/common/internal/ConnectionEnv.destroy(ConnectionEnv.java:507)
^-- Holding lock: weblogic/jdbc/common/internal/ConnectionEnv@0xf71f6798[biased lock]
at weblogic/common/resourcepool/ResourcePoolImpl.destroyResource(ResourcePoolImpl.java:1802)
at weblogic/common/resourcepool/ResourcePoolImpl.access$500(ResourcePoolImpl.java:41)
at weblogic/common/resourcepool/ResourcePoolImpl$Group.killAllConnectionsBeingTested(ResourcePoolImpl.java:2399)
^-- Holding lock: java/util/TreeSet@0x4bba82c0[thin lock]
at weblogic/common/resourcepool/ResourcePoolImpl$Group.destroyIdleResources(ResourcePoolImpl.java:2267)
^-- Holding lock: weblogic/jdbc/common/internal/GenericConnectionPool@0x5da625a8[thin lock]
at weblogic/common/resourcepool/ResourcePoolImpl$Group.checkHang(ResourcePoolImpl.java:2475)
at weblogic/common/resourcepool/ResourcePoolImpl$Group.access$100(ResourcePoolImpl.java:2210)
at weblogic/common/resourcepool/ResourcePoolImpl.checkResource(ResourcePoolImpl.java:1677)
at weblogic/common/resourcepool/ResourcePoolImpl.checkResource(ResourcePoolImpl.java:1662)
at weblogic/common/resourcepool/ResourcePoolImpl.makeResources(ResourcePoolImpl.java:1268)
at weblogic/common/resourcepool/ResourcePoolImpl.makeResources(ResourcePoolImpl.java:1166)
The oracle/jdbc/driver/T4CConnection@0xf71f6938 lock is held by yet another thread MDSPollingThread-owsm which is attempting to test the health of its jdbc connection (that it reserved from the datasource connection pool) by invoking some basic test on the database. The socket read from the DB appears to the one is either slow or every other thread kept getting the lock except for ExecuteThread 58 & 26 as both appear STUCK in the same position for 10 minutes or longer. Having multiple thread dumps will help confirm if the same threads are stuck in the same position or there was change in ownership of locks and these threads were just so unlucky in getting ownership of the locks.
"MDSPollingThread-[owsm, jdbc/mds/owsm]" id=94 idx=0x150 tid=2993 prio=5 alive, in native, daemon
at jrockit/net/SocketNativeIO.readBytesPinned(Ljava/io/FileDescriptor;[BIII)I(Native Method)
at jrockit/net/SocketNativeIO.socketRead(SocketNativeIO.java:32)
at java/net/SocketInputStream.socketRead0(Ljava/io/FileDescriptor;[BIII)I(SocketInputStream.java)
at java/net/SocketInputStream.read(SocketInputStream.java:129)
at oracle/net/nt/MetricsEnabledInputStream.read(TcpNTAdapter.java:718)
at oracle/net/ns/Packet.receive(Packet.java:295)
at oracle/net/ns/DataPacket.receive(DataPacket.java:106)
at oracle/net/ns/NetInputStream.getNextPacket(NetInputStream.java:317)
at oracle/net/ns/NetInputStream.read(NetInputStream.java:104)
at oracle/jdbc/driver/T4CSocketInputStreamWrapper.readNextPacket(T4CSocketInputStreamWrapper.java:126)
at oracle/jdbc/driver/T4CSocketInputStreamWrapper.read(T4CSocketInputStreamWrapper.java:82)
at oracle/jdbc/driver/T4CMAREngine.unmarshalUB1(T4CMAREngine.java:1177)
at oracle/jdbc/driver/T4CTTIfun.receive(T4CTTIfun.java:312)
at oracle/jdbc/driver/T4CTTIfun.doRPC(T4CTTIfun.java:204)
at oracle/jdbc/driver/T4C8Oall.doOALL(T4C8Oall.java:540)
at oracle/jdbc/driver/T4CPreparedStatement.executeForRows(T4CPreparedStatement.java:1079)
at oracle/jdbc/driver/OracleStatement.doExecuteWithTimeout(OracleStatement.java:1419)
at oracle/jdbc/driver/OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3752)
at oracle/jdbc/driver/OraclePreparedStatement.execute(OraclePreparedStatement.java:3937)
^-- Holding lock: oracle/jdbc/driver/T4CConnection@0xf71f6938[thin lock]
at oracle/jdbc/driver/OraclePreparedStatementWrapper.execute(OraclePreparedStatementWrapper.java:1535)
at weblogic/jdbc/common/internal/ConnectionEnv.testInternal(ConnectionEnv.java:873)
at weblogic/jdbc/common/internal/ConnectionEnv.test(ConnectionEnv.java:541)
at weblogic/common/resourcepool/ResourcePoolImpl.testResource(ResourcePoolImpl.java:2198)
The underlying cause for the whole hang was due to firewall dropping the socket connections between the server and database and leading to hung socket reads.
If the application uses java Concurrent Locks, it might be harder to identify who is holding a lock as there can be multiple threads waiting for notification on the lock but no obvious holder of lock. Sometimes the JVM itself report the lock chain. If not, enable -XX:+PrintConcurrentLocks in the java command line to get details on Concurrent Locks.
What to observe
The overall health of JVM is based on the interaction of threads, resources, partners/systems/actors along with the OS, GC policy and hardware.
- Ensure the system has been subjected to some good loads and everything has initialized/stabilized before starting the thread capture cycle.
- Ensure no deadlock exists in the JVM. If there are deadlocks, restart is the only option to kill the deadlock. Analyze the locking and try to establish a order of locking or to avoid the locks entirely.
- Verify GC or Memory is not a bottleneck
- Check that Finalizer thread is not blocked. Its possible for the Finalizer thread to be blocked for a lock held by a user thread leading to accumulation in finale objects and more frequent GCs.
- Threads requesting for new memory too frequently. These can be detected in JRockit VM by the threads executing jrockit.vm.Allocator.getNewTLA()
- Use Blocked Lock Chain information if available
- Identified by JVM as dependent chains or blocked threads. Use this to navigate the chain and reduce the locking.
- Search and Identify reason for STUCK threads
- Are they harmless or bad
- Are external systems (Database/services/backends) cause of slowness ??
- Based on hot spots/blocked call patterns.
- Sometimes the health of one server might be really linked to other servers its interacting with, especially in a clustered environment. In those cases, it might require gathering and analyzing thread dumps from multiple servers. For instance in WLS: deployment troubleshooting will require thread dump analysis of Admin Server along with Managed server where the application is getting deployed or Oracle Service Bus (OSB) along with SOA Server instance.
- Parallel capture from all linked pieces simultaneously and analyze.
- Look for excess threads. These can be for GC (a 12 core hyperthreaded box might lead to 24 Parallel GC threads) or WLS can be running with large number of Muxer threads. Try to trim number of threads as these can only lead to excess thread switching and degraded performance.
- Parallel GC threads can be controlled by using the jvm vendor specific flags.
- For WLS, best to have the number of Native Muxer threads to 4. Use -Dweblogic.SocketReaders=4 to tweak the number of Muxer threads.
- Ensure the WLS Server is using the Native Muxer and not the JavaSocketMuxer. Possible reasons might include not setting the LD_LIBRARY_PATH or SHLIB_PATH to include the directory containing the native libraries. Native Muxer delivers best performance compared to Java Socket Muxer as it uses native poll to read sockets that have readily available data instead of doing a blocking read from the socket.
What Next?
- Analyze the dependencies between code and locks
- Might require subject expert (field or customer) who can understand, identify and implement optimizations
- Resolving bottlenecks due to Locking
- Identify reason for locks and call invocations
- Avoid call patterns
- Code change to avoid locks - use finer grained locking instead of method/coarser locking
- Increase resources that are under contention or used in hot spots
- Increase size of connection pools
- Increase memory
- Cache judiciously (remote stubs, resources, handlers...)
- Separate work managers in WLS for dedicated execution threads (use wl-dispatch-policy). Useful if an application always requires dedicated threads to avoid thread starvation or delay in execution
- Avoid extraneous invocations/interruptions - like debug logging, excessive caching, frequent GCs, too many exceptions to handle logic
- Repeat the cycle - capture, analyze, optimize and fine tune ...
Summary
This section of the series discussed how to analyze thread dumps and navigate lock chains as well as some tips and pointers on what to look for and optimize. The next section will go into tools that can help automate thread dump analysis, some real world examples and limitations of thread dumps.