百万用户时尚分享网站feed系统扩展实践-CSDN.NET
Fashiolista是一个在线的时尚交流网站,用户可以在上面建立自己的档案,和他人分享自己的以及在浏览网页时看到的时尚物品。目前,Fashiolista的用户来自于全球100多个国家,用户达百万级,每日分享的时尚物品超过500万。作为一个以社交、分享的网站,feed系统占据了网站的核心架构,Fashiolista的创始人兼CTO Thierry Schellenbach撰写了一篇博客,分享了自家网站feed系统建设的经验,译文如下:
Fashiolista最初是我们作为兴趣在业余时间开发的一个项目,当初完全没有想到它会成长为规模如此大的在线时尚交流网站。最早的版本开发用了大概两周的时间,当时feed信息流推送系统相当简单。在这里分享一些我们扩展feed系统的经验。

对于许多大型的创业公司,如Pinterest、Instagram、Wanelo和Fashiolista来说,feed是一个核心组件。在Fashiolista网上的 flat feed、aggregated feed和notification系统功能都是靠feed系统来支撑的。本文中将介绍我们在扩展feed系统中遇到的问题,以及你自己方案中的设计决策。随着越来越多的应用依赖于feed系统,理解feed系统的基本工作原理变得至关重要了。
另外,Fashiolista的feed系统Python版本——Feedly已经开源了。
Feed简介
feed系统的扩展问题曾引起过广泛关注,这个解决方案是为了在网络拥挤的情况下,构建一个类似于Facebook新鲜事feed、Twitter流或Fashiolista的feed页面。这些系统的共同点在于向用户展示其关注的人的动态,我们就是基于这个标准来构建动态数据流的,诸如“Thierry在Fashiolista列表中添加了一件服饰”或“Tommaso发布了一条twitter”。
构建这个feed系统用到了两个策略:
- 拉取(Pull),读取的过程中收集feed。
-
推送(Push),写的过程中提前计算好feed。
大多数实时在线应用程序会使用这两种方法的组合,将动态推送给你的粉丝的过程被称为消息分发(fanout)。
历史和背景
Fashiolista的feed系统经过了三次重大改进。第一个版本基于PostgreSQL数据库,第二个版本使用Redis数据库,目前的版本采用Cassandra数据库。为了便于读者更好的理解这些版本更替的时间和原因,笔者会首先介绍一些背景知识。
第一部分——数据库
 第一版本的数据库查询语句很简单,类似于这种:
第一版本的数据库查询语句很简单,类似于这种:
select * from love where user_id in (...)
令人惊讶的是这个系统的强健性还不错。当love(类似于“赞”了某件服饰)的数量达到百万时,它运行得很好,超过500万时,依然没有问题。我们还打赌说这个系统不能支持千万的数量级,但是当love到达千万时,它依然运行得很好。这个简单的系统支撑着我们的系统达到了百万的用户和过亿的love,期间只进行了一些小改动。之后随着用户的增多,这个系统开始出现波动,部分用户的延时长达数秒,在参考了很多关于feed系统的架构设计之后,我们开发了第一个基于Redis的Feedly。
第二阶段——Redis和Feedly
我们为每个用户建立一个用Redis存储的feed,当你love了一件服饰时,这个动态会分发给你所有的粉丝。我们尝试了一些小技巧来减少内存的消耗(笔者会在下面具体介绍),Redis的启动和保持确实比较简单。我们使用Twemproxy在几台Redis机器上进行共享,使用Sentinel做自动备份。
Redis是一个好的解决方案,但是几个原因迫使我们不得不寻找新的方案。首先,我们希望支持多文档类型,而Redis返回数据库查询更困难,并且提高了存储需求。另外,随着业务的增大,数据库回滚也变得越来越慢。这些问题只能靠在Redis上存储更多的数据来解决,但是这样做的成本太高了。
第三阶段——Cassandra和Feedly
通过比较HBase、DynamoDB和Cassandra2.0,我们最终选择了Cassandra,因为它拥有几个移动部件,Instagram使用的数据库就是Cassandra,并且Datastax为它提供支持。Fashiolista目前在flat feed中完全采取推送流,聚合feed采用推送和拉取混合的技术。我们在每个用户的feed中最多保存3600条动态,目前占用了2.12TB的存储空间。由明星用户带来的系统波动我们也采取了一些方式进行缓解,包括:优先队列、扩大容量和自动扩展等。

Feed设计
笔者认为Fashiolista设计的改进过程非常有代表性,在构建一个feed系统时(尤其是使用Feedly)有几个重要的设计问题需要考虑。
1.非规范化Vs规范化
规范化的方法是,你关注的人的feed列表中是每条动态的ID,非规范的存储是动态的所有信息。
仅存储ID可以大幅度减少内存消耗,然而这意味着每次加载feed都要重新访问数据库。如何选择取决于你在进行非规范化存储时,复制数据的频率。比如构建一个消息通知系统和一个feed系统有很大的区别:通知系统中每个动作的发生只需要被发送给几个用户,而feed系统中每个动态的数据可能要被复制给成千上万的粉丝。
另外,如何选择取决于你的存储架构,使用Redis时,内存是需要特别注意的问题;而使用Cassandra要占用大量的存储空间,但是对于规范化数据来说使用并不简单。
对于feed通知和基于Cassandra构建的feed,笔者建议将你的数据非规范化。而基于Redis的feed你需要最小化内存消耗,并保持数据规范化。采用Feedly可以轻松实现两种方案。
2.基于生产者的选择性分发
Yahoo的Adam Silberstein等人所著的论文中,提出了一种选择性推送用户feed的方法,Twitter目前也在使用类似的方法。明星用户的消息分发会给系统带来突然和巨大的负载压力,这意味着必须要预留出额外的空间来保持实时性。这篇论文中建议通过选择性地分发消息,来减少这些明星用户带来的负载。Twitter采用了这个方法后,在用户读取时才加载这些明星用户的tweet,性能得到了大幅度提升。
3.基于消费者的选择性分发
另外一种选择性分发方式是指对那些活跃用户(比如过去一周登录过的用户)分发消息。我们对这个方法进行了修改,为活跃用户存储最近的3600条动态,为非活跃用户存储180条,读取180条之后的数据需要重新访问数据库,这种方式对于非活跃用户的体验不太好,但是能有效降低内存消耗。
Silberstein等人认为最适合选择性推送模式的情境是:
- 生产者偶尔生产动态信息
- 消费者经常请求feed
遗憾的是Fashiolista还不需要如此复杂的系统,很好奇业务要达到多少数量级才会需要这种解决方案。
4.优先级
一个替代的策略是在分发任务时采取不同的优先级,将给活跃用户的分发任务设为高优先级,向非活跃用户的分发任务设为低优先级。Fashiolista为高优先级的用户预留了一个较大的缓存空间,来处理随时的峰值。对于低优先级用户,我们靠自动扩展和点实例。在实践中,这意味着非活跃用户的feed会有一定的延时。使用优先级降低了明星用户对系统的负载压力,虽然没有解决根本问题,但大幅度降低了系统负载峰值的量级。
5.Redis Vs Cassandra
Fashiolista和Instagram都经历了从Redis开始,然后转战Cassandra的过程。笔者之所以会推荐从Redis开始是因为Redis更容易启动和维持。
然而Redis存在一定的限制,所有的数据需要被存储在RAM中,成本很高。另外,Redis不支持分片,这意味着你必须在结点间分片(Twemproxy是一个不错的选择),这种分片很容易,但是添加和删除节点时的数据处理很复杂。当然你可以将Redis作为缓存,然后重新访问数据库,来克服这个限制。但是随着访问数据库的成本越来越高,笔者建议还是用Cassandra代替Redis。
Cassandra Python的生态系统正在发生巨变,CQLEngine和Python-Driver都是很优秀的项目,但是它们需要投入一定的时间去学习。
结论
在构建自己的feed解决方案时,有很多因素需要在节点分片时考虑:选择何种存储架构?如何处理明星用户带来的负载峰值?非规范化数据到何种程度?笔者希望借助这篇文章能够为你提供一些建议。
Feedly不会为你做任何选择,这仅是一个构建feed系统的框架,你可以自己决定内部的技术细节。可以看Feedly的介绍进行了解或参看操作手册构建一个Pinterestsque应用程序。
请注意只有数据库中的用户达到百万时,你才会需要解决这个问题。在Fashiolista简单的数据库解决方案就支撑我们达到了百万用户和过亿的love。
更多关于feed系统的设计,笔者强烈建议看一下这些文章:
- Yahoo Research Paper
- Twitter 2013 Redis based, with fallback
- Cassandra at Instagram
- Etsy feed scaling
- Facebook history
- Django project, with good naming conventions. (But database only)
- http://activitystrea.ms/specs/atom/1.0/ (actor, verb, object, target)
- Quora post on best practises
- Quora scaling a social network feed
- Redis ruby example
- FriendFeed approach
- Thoonk setup
- Twitter's Approach
原文链接:Design Decisions For Scaling Your High Traffic Feeds(编译/周小璐 审校/仲浩)
完全用nosql轻松打造千万级数据量的微博系统 - 开源中国社区
其实微博是一个结构相对简单,但数据量却是很庞大的一种产品.标题所说的是千万级数据量也并不是一千万条微博信息而已,而是千万级订阅关系之间发布。在看 我这篇文章之前,大多数人都看过sina的杨卫华大牛的微博开发大会上的演讲.我这也不当复读机了,挑重点跟大家说一下。
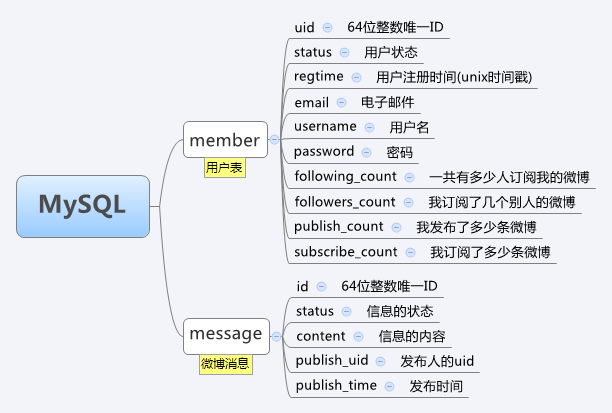
大家都知道微博的难点在于明星会员问题,什么是明星会员问题了,就是刘德华来咱这开了微博,他有几百万的粉丝订阅者,他发一条微博信息,那得一下子把微博 信息发布到几百万的粉丝里去,如果黎明、郭富城等四大天王都来咱来开微博,那咱小站不是死翘翘了.所以这时消息队列上场了。在我的架构里 有一个异步publish集群,publish的任务都去zeromq队列读取队列.zeromq是目前已知开源的消息传递最快的一个。具体关于 zeromq可以自己google。zeromq有一个问题是不能持久化数据,这个自己做持久化存储.回过刚才那个话题, 把明星会员的粉丝按照"活跃度"进行分级。"活跃度"是根据登陆频度,时间,发布微博等因素大致分为铁杆粉丝、爱理不理、半死不活三大类分到不同的发布集 群中去. 铁杆粉丝类型的异步发布集群,发布速度肯定是最快的.微博的信息是用handler socket保存到mysql。这个信息ID,是用rdtsc+2位随机整数拼接而成的 64位整数唯一ID,防止出现自增ID出现的多服务器 id一致性的问题. 在publish的时候,集群只是把微博信息的ID发送给redis的订阅者。所以这个数据是很快的。而且订阅者的list里只保存的是ID.在内存的占 用率上也不是很高.
下面我给大家看一下我的mysql和redis数据结构

在我的结构中还有一个重要角色就是"Key GPS Server"(简称:KGS)简单来说,这个是分布式数据存储的中心索引服务器.一切数据的存储和获取,都通过KGS来定位. KGS支持多个服务器,多个机房多重备份存储。KGS是以Tokyo Cabinet的hash db为存储的socket server。记录key跟服务器之间的对应关系. KGS的任务就是告知key该存储在哪几台服务器上,或者告知该key存储在哪几台服务器上,并不做其他的服务.这样大大的减轻KGS的压力.
再说一下Redis集群,redis是以纯内存形式模式运行,关闭了热备的功能(redis的热备并不是那么好). 自己写了个backend server.在每台运行redis的机子上都运行着backend socket 进程, backend进程也是以tc的hash db为存储。备份着当前服务器的redis数据。当redis重启的时候,从本机的bakcend db 加载所有数据. Redis的集群是以用户水平切分法来分布的
现在该轮到mysql里, 在这个架构中,基本消除了这边缓存 那边缓存的问题。因为在这个集群中的每个服务都是高速运行的.唯一的一处的cache 就是在php端的eAccelerator local cache. eAccelerator是基于共享内存的,所有速度比基于socket类型的cache快多了. eAccelerator 缓存了用户top N条的微博信息还有从KGS查询的结果。 看到这里有人问了,你把用户信息和微博信息都放在mysql里,怎么能不用cache了.嘿嘿,因为我用了 handler socket。HS 是小日本写的一款mysql插件.HS避开了MySQL通讯协议,直接读取MySQL引擎。在多核、大内存、 InnoDB引擎环境,性能直超memcached.HS能以Key-Value方式直接读写mysql引擎
总结
Google首席科学家讲过一句话,就是一个大的复杂的系统,应该要分解成很多小的服务. 我的这个架构也是由一个个小的集群来共同处理大数据量发布数据。有的人为什么不用mongodb了,因为mongodb是一款大众性的分布式nosql db,我们有自己的key分布策略,不太适合用mongodb. 不理解redis的存储关系的同学,可以先参考一下 Retwis, Retwis是用纯redis实现的简单微博.
具体的架构图、流程图、ppt文件。请下载附件来阅读. http://code.google.com/p/php-tokyocabinet/downloads/detail?name=micro-blog-qiye.tar.bz2&can=2&q=#makechanges
我的QQ: 531020471 mail: lijinxing#gmail.com
Synchronous Request Response with ActiveMQ and Spring | CodeDependents
Request Response with JMS
ActiveMQ documentation actually has a pretty good overview of how request-response semantics work in JMS.
You might think at first that to implement request-response type operations in JMS that you should create a new consumer with a selector per request; or maybe create a new temporary queue per request.
Creating temporary destinations, consumers, producers and connections are all synchronous request-response operations with the broker and so should be avoided for processing each request as it results in lots of chat with the JMS broker.
The best way to implement request-response over JMS is to create a temporary queue and consumer per client on startup, set JMSReplyTo property on each message to the temporary queue and then use a correlationID on each message to correlate request messages to response messages. This avoids the overhead of creating and closing a consumer for each request (which is expensive). It also means you can share the same producer & consumer across many threads if you want (or pool them maybe).
This is a pretty good start but it requires some tweaking to work best in Spring. It also should be noted that Lingoand Camel are also suggested as options when using ActiveMQ. In my previous post I addressed why I don’t use either of these options. In short Camel is more power than is needed for basic messaging and Lingo is built onJencks, neither of which have been updated in years.
Request Response in Spring
The first thing to notice is that its infeasible to create a consumer and temporary queue per client in Spring since pooling resources is required overcome the JmsTemplate gotchas. To get around this, I suggest using predefined request and response queues, removing the overhead of creating a temporary queue for each request/response. To allow for multiple consumers and producers on the same queue the JMSCorrelationId is used to correlated the request with its response message.
At this point I implemented the following naive solution:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
@Componentpublic class Requestor { private static final class CorrelationIdPostProcessor implements MessagePostProcessor { private final String correlationId; public CorrelationIdPostProcessor( final String correlationId ) { this.correlationId = correlationId; } @Override public Message postProcessMessage( final Message msg ) throws JMSException { msg.setJMSCorrelationID( correlationId ); return msg; } } private final JmsTemplate jmsTemplate; @Autowired public RequestGateway( JmsTemplate jmsTemplate ) { this.jmsTemplate = jmsTemplate; } public String request( final String request, String queue ) throws IOException { final String correlationId = UUID.randomUUID().toString(); jmsTemplate.convertAndSend( queue+".request", request, new CorrelationIdPostProcessor( correlationId ) ); return (String) jmsTemplate.receiveSelectedAndConvert( queue+".response", "JMSCorrelationID='" + correlationId + "'" ); }} |
This worked for a while until the system started occasionally timing out when making a request against a particularly fast responding service. After some debugging it became apparent that the service was responding so quickly that the receive() call was not fully initialized, causing it to miss the message. Once it finished initializing, it would wait until the timeout and fail. Unfortunately, there is very little in the way of documentation for this and the best suggestion I could find still seemed to leave open the possibility for the race condition by creating the consumer after sending the message. Luckily, according to the JMS spec, a consumer becomes active as soon as it is created and, assuming the connection has been started, it will start consuming messages. This allows for the reordering of the method calls leading to the slightly more verbose but also more correct solution. (NOTE: Thanks to Aaron Korver for pointing out that ProducerConsumer needs to implement SessionCallback and that true needs to be passed to the JmsTemplate.execute() for the connection to be started.)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
@Componentpublic class Requestor { private static final class ProducerConsumer implements SessionCallback<Message> { private static final int TIMEOUT = 5000; private final String msg; private final DestinationResolver destinationResolver; private final String queue; public ProducerConsumer( final String msg, String queue, final DestinationResolver destinationResolver ) { this.msg = msg; this.queue = queue; this.destinationResolver = destinationResolver; } public Message doInJms( final Session session ) throws JMSException { MessageConsumer consumer = null; MessageProducer producer = null; try { final String correlationId = UUID.randomUUID().toString(); final Destination requestQueue = destinationResolver.resolveDestinationName( session, queue+".request", false ); final Destination replyQueue = destinationResolver.resolveDestinationName( session, queue+".response", false ); // Create the consumer first! consumer = session.createConsumer( replyQueue, "JMSCorrelationID = '" + correlationId + "'" ); final TextMessage textMessage = session.createTextMessage( msg ); textMessage.setJMSCorrelationID( correlationId ); textMessage.setJMSReplyTo( replyQueue ); // Send the request second! producer = session.createProducer( requestQueue ); producer.send( requestQueue, textMessage ); // Block on receiving the response with a timeout return consumer.receive( TIMEOUT ); } finally { // Don't forget to close your resources JmsUtils.closeMessageConsumer( consumer ); JmsUtils.closeMessageProducer( producer ); } } } private final JmsTemplate jmsTemplate; @Autowired public Requestor( final JmsTemplate jmsTemplate ) { this.jmsTemplate = jmsTemplate; } public String request( final String request, String queue ) { // Must pass true as the second param to start the connection return (String) jmsTemplate.execute( new ProducerConsumer( msg, queue, jmsTemplate.getDestinationResolver() ), true ); }} |
About Pooling
Once the request/response logic was correct it was time to load test. Almost instantly, memory usage exploded and the garbage collector started thrashing. Inspecting ActiveMQ with the Web Console showed that MessageConsumers were hanging around even though they were being explicitly closed using Spring’s own JmsUtils. Turns out, the CachingConnectionFactory‘s JavaDoc held the key to what was going on: “Note also that MessageConsumers obtained from a cached Session won’t get closed until the Session will eventually be removed from the pool.” However, if the MessageConsumers could be reused this wouldn’t be an issue. Unfortunately, CachingConnectionFactory caches MessageConsumers based on a hash key which contains the selector among other values. Obviously each request/response call, with its necessarily unique selector, was creating a new consumer that could never be reused. Luckily ActiveMQ provides a PooledConnectionFactory which does not cache MessageConsumers and switching to it fixed the problem instantly. However, this means that each request/response requires a new MessageConsumer to be created. This is adds overhead but its the price that must be payed to do synchronous request/response.