
以下内容由
[五四陈科学院]提供

网站速度一直是互联网公司所关注的核心目标之一,作为SNS网站更是这样。来自世界第一大的打不开的SNS网站facebook的工程师日志中提到,BigPipe: Pipelining web pages for high performance。
原文在墙外,豆瓣有存根,地址为http://9.douban.com/site/entry/139173635/。
来自infoq的一篇资料报道:http://www.infoq.com/cn/news/2010/08/bigpipe-facebook-optimize
它本意是充分利用http,将用户感受到的延迟时间降低一半,是如何做到的呢,下面由54chen流水记账一篇解释实现原理。院内曾经由人人网架构师王志亮大侠发表过一篇文章,地址是http://www.54chen.com/architecture/rose-open-source-portal-framework.html,本文将以此例中的项目举例。
HTTP协议
HTTP是一个客户端和服务器端请求和应答的标准,尽管TCP/IP协议是互联网上最流行的应用,HTTP协议并没有规定必须使用它和(基于)它支持的层。 事实上,HTTP可以在任何其他互联网协议上,或者在其他网络上实现。HTTP只假定(其下层协议提供)可靠的传输,任何能够提供这种保证的协议都可以被其使用。
在这里重新解释HTTP是为了后面做铺垫,一次http访问的过程如下:
1.打开一个连接后,客户机把请求消息送到服务器的停留端口上,完成提出请求动作;
2.服务器在处理完客户的请求之后,要向客户机发送响应消息;
3.客户和服务器双方都可以通过关闭套接字来结束TCP/IP对话。
在使用java的ServletResponse的时候,往往都是如下的操作返回结果到用户:
out.write(sb.toString());
out.flush();
out.close();
传统的WEB请求
以图1为例,一个WEB项目往往由不同的部分组成,不同的格局里往往代表需要从不同的数据表里去取不同的数据。
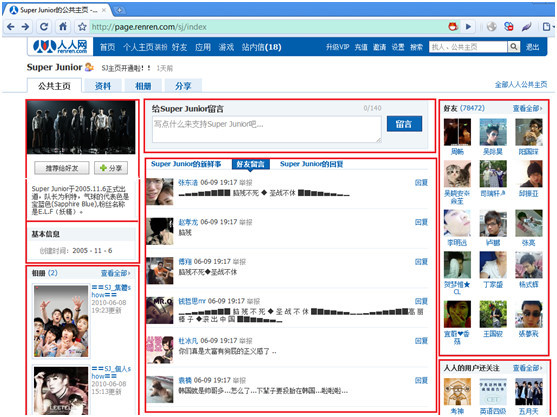
图1 人人网公共主页页面
一个用户来访问这个页面,按照传统的做法,其流程图可能是如图2这样的。
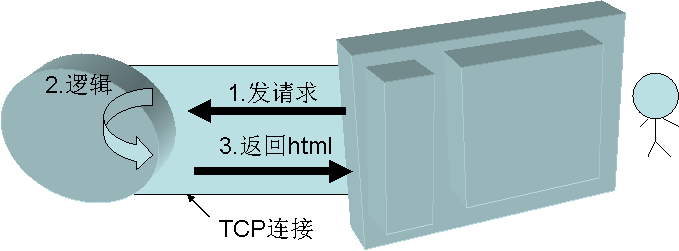
图2 一个传统的http请求过程
在图2中可以看到,一次打开网站页面的过程中,请求发到后端进行了处理(1和2步),只有当后端的取数据操作(2步)全部完成的时候,才可能进入第3步,向用户返回组装好的html页。如果说图1中一共有四个模块,对应后台有四条sql语句的话,那么,必须这四条sql语句全部返回了结果,才可能让用户看到页面。
pipe
pipe技术充分利用了前后端技术。将一个页面里的多个模块分成不同的window,多线程取数据的操作,然后再充分利用http请求的连接,将原来的输出,从一次flush变成多次flush:
out.write(“基础的dom”);
out.flush();
//数据一准备好时
out.write(“js带数据一”);
out.flush();
//数据十二准备好时
out.write(“js带数据二”);
out.flush();
out.close();
其过程如图3所示:
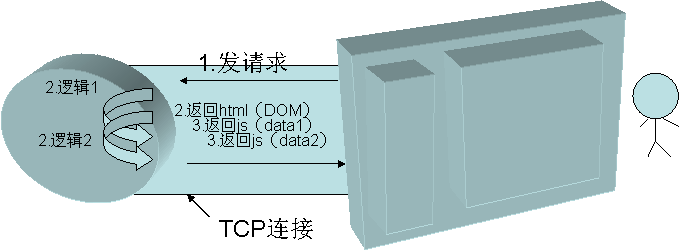
图3 pipe的请求过程
借用big pipe的代码,第一次是输出的:
<div>
<div id=”left_column”>
<div id=”pagelet_navigation”></div>
</div>
<div id=”middle_column”>
<div id=”pagelet_composer”></div>
<div id=”pagelet_stream”></div>
</div>
<div id=”right_column”>
<div id=”pagelet_pymk”></div>
<div id=”pagelet_ads”></div>
<div id=”pagelet_connect”></div>
</div>
</div>
当有了完整的dom结构时,浏览器就会开始显示没有数据的框架了。
后面的数据每次都以js继续发送到页面中,浏览器收到即开始写入:
<script type="text/javascript">
big_pipe.onPageletArrive({id: “pagelet_composer”, content=<HTML>, css=[..], js=[..], …})
</script>
性能
这种显示方式的性能,再借用facebook的图来表示之,如图4:
