

[原]程序员编程艺术第二十三~四章:杨氏矩阵查找,倒排索引提取关键词
- - 结构之法 算法之道 第二十三、四章:杨氏矩阵查找,倒排索引提取关键词. 本文先来回答一个何谓编程,何谓算法的问题(同时,本文会少许论述编程与算法的关系). 所谓编程,就是把心中的想法用程序实现;所谓算法,就是思考如何把心中的想法更好地实现. 只有先把心中的想法实现了以后,才会去考虑如何更好地实现,才会去考虑效率,改进,优化.
第二十三、四章:杨氏矩阵查找,倒排索引提取关键词
作者:July。
出处:结构之法算法之道。
编程是个细活儿,是个经验活,非一朝一夕所能炼成,不得有半点马虎,半点浮躁,半点急功近利。OK,有任何问题,也欢迎随时交流或批评指正。谢谢。
有一些朋友是由于要进大公司准备面试而学的算法,那么面试考察的算法难么?或者是否有必要因要准备大公司的面试而大张旗鼓的去学算法呢?OK,举个简单的例子:
先看一个来自剑指offer一书的编程(面试)题:
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
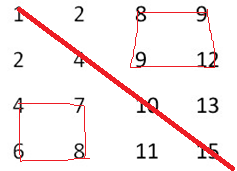
例如下面的二维数组就是每行、每列都递增排序。如果在这个数组中查找数字6,则返回true;如果查找数字5,由于数组不含有该数字,则返回false。
前面说了,学算法就是多思考,下面,解法有二(如查找数字6):
1、分治法,分为四个矩形,配以二分查找,如果要找的数是6介于对角线上相邻的两个数4、10,可以排除掉左上和右下的两个矩形,而递归在左下和右上的两个矩形继续找,如下图所示:
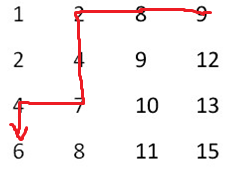
2、首先直接定位到最右上角的元素,再配以二分查找,比要找的数(6)大就往左走,比要找数(6)的小就往下走,直到找到要找的数字(6)为止,如下图所示:
试问,上述算法复杂么?不复杂,只要稍微动点脑筋便能想到(何海涛先生一书剑指offer中收集了此题,感兴趣的朋友也可以去看看)。
而后,你也自会意识到,完全没有必要因为要准备大公司的面试而大张旗鼓的去学算法,算法只能作为一种工作需求,一种兴趣,而非助你取得offer的功利性工具。
本章咱们来看一个可能实际工作中会遇的从索引中提取关键词的问题,我会摒弃其中复杂的原理与步骤,尽量用最简单易懂的语言阐述:
我们知道,搜索引擎的关键步骤就是建立倒排索引,所谓倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关的章节,直接根据目录即可找到相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
接下来,再次阐述下正排索引与倒排索引的区别:
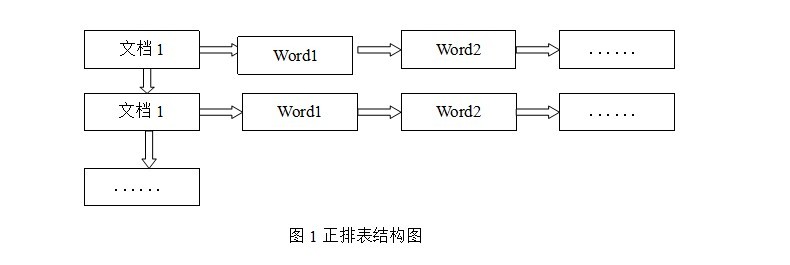
正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。正排表结构如图1所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档假如,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对因的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,几乎没有什么实用价值。
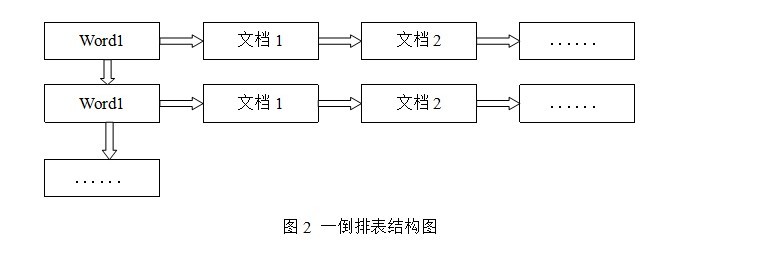
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排表的结构图如图2:
倒排表的索引信息保存的是字或词后继数组模型、互关联后继数组模型条在文档内的位置,在同一篇文档内相邻的字或词条的前后关系没有被保存到索引文件内。
倒排索引是搜索引擎之基石。建成了倒排索引后,用户要查找某个query,如在搜索框输入某个关键词:“结构之法”后,搜索引擎不会再次使用爬虫又一个一个去抓取每一个网页,从上到下扫描网页,看这个网页有没有出现这个关键词,而是会在它预先生成的倒排索引文件中查找和匹配包含这个关键词“结构之法”的所有网页。找到了之后,再按相关性度排序,最终把排序后的结果显示给用户。
如下,即是一个倒排索引文件(不全),每一较短的,不包含有“#####”符号的便是某个关键词,及这个关键词的出现次数。我现在要你从这个大索引文件中提取出这些关键词,--Firelf--,-Winter-,007,007:天降杀机,02Chan..如何做到呢?一行一行的扫描整个索引文件么?当然不是,请读者自行思考。
--Firelf--(关键词) 8(出现次数)
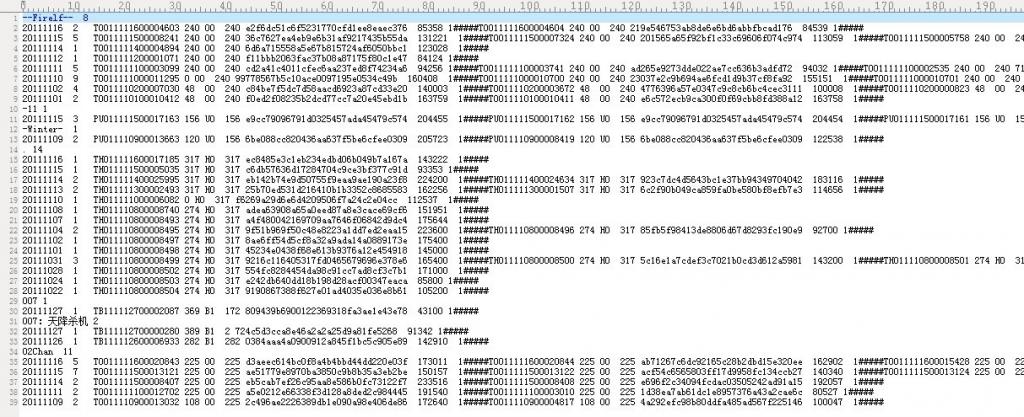
提示一下:通过查找#####便可判断某一行出现的词是不是关键词,但如果这样做的话,便要扫描整个索引文件的每一行,代价实在巨大。如何提高速度呢?对了,关键词后面的那个出现次数为我们问题的解决起到了很好的作用,如下注释所示:
// 本身没有##### 的行判定为关键词行,后跟这个关键词的行数N
// 接下来,截取关键词--Firelf--,然后读取后面关键词的行数N
// 再跳过N行(滤过和避免扫描中间无用信息)
// 读取下一个关键词..
读者是否有更好地办法?欢迎随时交流。