SQL Server--索引
- - CSDN博客推荐文章 1,概念: 数据库索引是对数据表中一个或多个列的值进行排序的结构,就像一本书的目录一样,索引提供了在行中快速查询特定行的能力.. 2.1优点: 1,大大加快搜索数据的速度,这是引入索引的主要原因.. 2,创建唯一性索引,保证数据库表中每一行数据的唯一性..
1,概念: 数据库索引是对数据表中一个或多个列的值进行排序的结构,就像一本书的目录一样,索引提供了在行中快速查询特定行的能力.
2,优缺点:
2.1优点: 1,大大加快搜索数据的速度,这是引入索引的主要原因.
2,创建唯一性索引,保证数据库表中每一行数据的唯一性.
3,加速表与表之间的连接,特别是在实现数据的参考完整性方面特别有意义.
4,在使用分组和排序子句进行数据检索时,同样可以减少其使用时间.
2,2缺点: 1,索引需要占用物理空间,聚集索引占的空间更大.
2,创建索引和维护索引需要耗费时间,这种时间会随着数据量的增加而增加.
3,当向一个包含索引的列的数据表中添加或者修改记录时,SQL server 会修改和维护相应的索引,这样增加系统的额外开销,降低处理速度。
3,索引的分类:
1,按存储结构可分为:
a,聚集索引:指物理存储顺序与索引顺序完全相同,它由上下两层组成,上层为索引页,下层为数据页,只有一种排序方式,因此每个表中只能创建一个聚集索引。
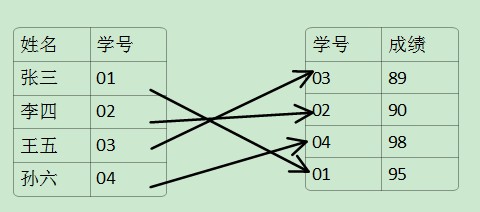
b,非聚集索引:指存储的数据顺序一般和表的物理数据的存储结构不同。通过下表我们可以分析出:(其中在学号上建立非聚集索引)
1,创建:(1),原则:a,只有表的所有者可以在同一个表中创建索引;
b,每个表中只可以创建一个聚集索引;
c,每个表中最多可以创建249个非聚集索引;
d,在经常查询的字段上建立索引;
e,定义text,image和bit数据类型的裂伤不能创建索引;
f,在外键列上可以创建索引,主键上一定要有索引;
g,在那些重复值比较多的,查询较少的列上不要建立索引。
(2),方法:a,使用SQL server Management Studio创建索引。
b,使用T-SQL语句中的create Index语句创建索引
c,使用Create table或者alter Table语句为表列定义主键约束或者唯一性约束时,会自动创建主键索引和惟一索引。
这里说说T-sql语句创建索引:
语法:
create relational index create[unique][clustered|nonclustered] index index_name on<object>(cloumn[asc|desc][,……n])
[include (column_name[,……n])]
[with(<relational_index_option>[,……n])]
[onfilegroup_name]
说明:1,include (column_name[,……n])指定要添加到非聚集索引的叶级别的非键列。
2,on filegroup_name,为指定文件组创建指定索引。
例如:在course表中,对“课程代号”列创建聚集索引zindex.
use db_student create clustered index zindex on course(课程代号)
2,查看索引:(1),使用SQL ServerManagement Studio查看索引信息
(2),使用系统存储过程查询索引信息,用SP_helpindex可以返回表中的所有索引信息
例如:查看course表的索引信息
use db_student execsp_helpindex course
3,修改索引:
(1),在SQL Server Management Studio 中修改索引
(2),使用Alter Index语句修改索引
在这里为大家举一个例子:
在course数据表中,修改所有的索引,并指定选项
use db_student
alterindex all on course rebuild with (fillfactor=80,sort_in_tempdb=on,statistics_norecompute=on)
4,删除索引:
(1),使用SQL Server Management Studio 删除索引
(2),使用Drop index语句删除索引
例如:在course表中,删除zindex索引
use db_student drop index course.zindex
分析:1,使用showplan 语句
语法:set showplan_all{on|off},set showplan_next{on|off}
例子:显示表course的课程代号,课程类型,课程内容,并显示查询过程
use db_student set showplan_all on select 课程代号,课程类型 课程内容 from course where 课程内容='loving'
2,使用statistics io语句
语法:statistics io{on|off} on和off分别为显示和不显示,使用方法和上一样。
维护: 1,使用dbcc showcontig语句,显示指定表的数据和索引的碎片信息。当对表中进行大量修改或添加数据后,应该执行此语句查看有无碎片。
语法:dbcc showcontig[{table_name|table_id|view_name|view_id},index_name|index_id] with fast
2,使用dbcc dbreindex语句,意思是重建数据库中表的一个或多个索引。
语法:
dbcc dbreindex (['database.owner.table_name'[,index_name[,fillfactor]]]) [withno_infomsgs]
说明: database.owner.table_name,重新建立索引的表名
index_name,是要重建的索引名
fillfactor,要创建索引时每个索引页上要用于存储数据的空间百分比。
with no_infomsgs,禁止显示所有信息性消息
3,使用dbcc indexdefrag,整理指定的表或视图的聚集索引和辅助索引碎片。
语法:
dbcc indexdefrag
({database_name|database_id|0},{table_name|table_id|'view_name'|view_id},{index_name|index_id})
with no_infomsgs
总结,只有我们对索引有了充分了熟悉;我们掌握了索引的增删改查四项基本操作,学会利用SQL Server Manager Sdudio去实现这些功能,和学会利用T-SQL语句去实现(自我感觉利用SQL Server Manager Sdudio 简单一些);当然还要懂得学会分析和维护索引,这样才会更好的让它为咱们服务!