
Dropbox可伸缩性设计最佳实践分享
- - InfoQ cn Dropbox的运维工程师 Rajiv,跟大家分享了可伸缩性设计的 最佳实践第一讲. 众所周知, Dropbox是一款非常易用的网络存储云端产品,现已达到40,000,000的用户. 令人惊奇的是, Dropbox公司对于服务器集群的运维人员投入在一到三个人. Rajiv就系统的可伸缩性设计,尤其在资源有限、流量快速增长的情况下,将最佳实践分享给大家.
Dropbox的运维工程师 Rajiv,跟大家分享了可伸缩性设计的 最佳实践第一讲。众所周知, Dropbox是一款非常易用的网络存储云端产品,现已达到40,000,000的用户。令人惊奇的是, Dropbox公司对于服务器集群的运维人员投入在一到三个人。 Rajiv就系统的可伸缩性设计,尤其在资源有限、流量快速增长的情况下,将最佳实践分享给大家。
在生产环境最常用的一个技巧就是,人为制造一些额外的数据进行加载。举个例子,生产环境常常针对缓存服务器进行额外的数据读取加载(Memcached Read),如果缓存服务器down机,运维工程师就可以马上切断流量进行故障排查。为什么不能事先计划好,而是采用一种”通过加流量试错”的方式发现系统的问题呢?答案是:从长时间积累的运维经验来看,引起系统故障的原因范围太大,而且常常是突发性的,无法通过监控实时捕获。另一点需要注意的是,尽量不要模拟数据写入加载,这会破坏生产环境的数据一致性以及导致无法控制的锁竞争。
针对特定应用,汇总不同类目集群所定制的数据统计图表变得越来越重要。一般现有的图表监控都是针对具体某一类数据(CPU, Mem, IO等),将各个维度的统计数据汇总到一个图表的需求很迫切。 Dropbox的解决方案是充分利用 memcached(缓存服务器), cron(后台计划任务管理)以及 ganglia(集群监控管理)三方的功能:每当有统计数据是我们想要的,会将该数据存到线程安全的内存块里面,每秒钟内存块里面的数据都会发送到缓存服务器,以时间戳作为Key存储。每分钟,缓存服务器的统计数据会被清除、汇总、发送到集群监控服务器。举个实际的例子,下面是生产环境中最好用的图表:
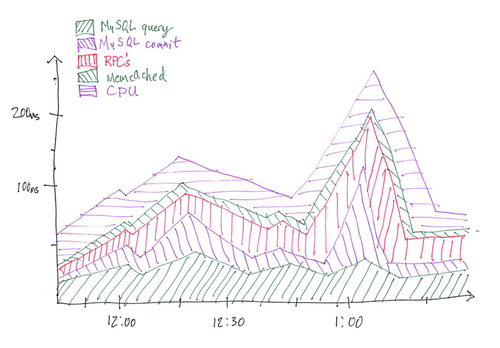
图1:系统响应时间度量图表
横轴是时间段,纵轴是站点服务器响应时间,响应时间分五段(MySQL Query, MySQL Commit, RPC’s, Memcaced, CPU),我们很容易看出在1:00左右,有根很长的刺,由MySQL Commit所导致。实际图表响应时间不仅仅只有五段,很多因素被剔除了,都包含在”CPU”里面。
熟练运用bash shell可以很大程度提高工作效率,举个例子,现有服务器端的日志,想从中提取最近某个时间段内流量的波峰是否超过阈值,当然现有的服务器图表可以满足大部分的需求,但很多系统的数据实时性不高(一到五分钟更新一次数据)。面对ad hoc需求,可以使用如下脚本:
Apr 8 2012 14:33:59 POST ...
Apr 8 2012 14:34:00 GET ...
Apr 8 2012 14:34:00 GET ...
Apr 8 2012 14:34:01 POST ...cut -d’ ’ -f1-4 log.txt | xargs -L1 -I_ date +%s -d_ | uniq -c | (echo “plot ‘-’ using 2:1 with lines”; cat) | gnuplot
上述命令会将现在的系统状况以图形化的形式表现出来。
垃圾日志并不是说一无是处,很多时候,它帮了我们大忙。垃圾日志其实可以作为跟踪代码的一种方式,举个例子,一段代码逻辑如果在正常情况下会打印”FUUUCCKKKKKasdjkfnff”的字符串,那么在出问题的时候我们可以根据日志找到问题的源头。日常的运维工作常常会维护两份日志文件,一份干净的日志文件,一份填充着垃圾日志的文件,它常常会不经意的帮到我们。
记录故障日志是一个很好的习惯,记录故障的开始、结束时间以及故障的原因,过后通过分析故障日志我们可以很客观的判断如何最小化故障发生的时间。每个故障发生的原因不尽相同,而每个故障的解决方案也不一样,将故障详情记录下来确实是一个明智之举。
一定要使用世界表尊时间,不管是服务器时间还是数据库时间。很多系统对于非UTC时间的处理很不好,这会带来很多问题,切记在呈现给用户数据之前做时区转换。
很多朋友对于 Dropbox使用什么技术非常感兴趣,我们来列举下我们使用的技术:
1) 开发语言使用 Python
2) 数据库 MySQL
3) Web框架 Paster/ Pylons/ Cheetah
5) memcached用来减小数据库的压力,以及用来处理内部系统的协作
6) ganglia做集群监视管理以及生成定制化监控报表
7) nginx做前端服务器
8) haproxy做web服务器负载均衡
9) nagios做内部服务器的健康检查
10) Pingdom做外部服务的监控
11) GeoIP 用来将IP转化为地理位置
上述选择的技术是业界标准,没有什么新奇,最大的原因是可靠、风险低。即便是 memcached这么通用的技术,都存在一些令人头痛的bug,选择太新的技术会让事情变得复杂。我们对于技术选型的建议是,尽量选择轻量级的、业界知名公司都在使用的技术,当然也可以花时间成为该项目的”技术先驱”。
为了保护用户文件信息,系统安全对于 Dropbox非常重要。但增加安全性,不管对于用户还是程序员,都会造成不方便,举个例子:很多网站在用户输入错误的用户名或者密码的时候,提示说您有一项输入错误,但不会告诉你具体是哪个。这种安全性策略,大大减小了破解用户名、密码的概率,但对于那些在不同网站都使用不同用户名的用户,会带来一些麻烦。
在内部服务器集群设置防火墙,是一个很棒的想法,但在实践中,对于互相没有通信的服务器集群可以省略此步骤。最常用的隔离,一般针对的是搭建在内部网络的第三方论坛,它更容易遭到攻击。
我们的安全策略可能有些争议,但系统安全都是对用户行为的假想和抽象,很多系统甚至是银行系统,都存在很大的安全隐患,所以在对系统做安全性投入的时候,先想一想这些工作是不是那么的必要。
对于运维技术感兴趣的读者朋友,可以关注 Rajiv的 博客,或者通过邮箱 [email protected]与作者联系。