nagios 监控redis
- - C1G军火库下载check_redis.pl. OK: REDIS 2.6.12 on 192.168.0.130:6379 has 1 databases (db0) with 49801 keys, up 3 days 14 hours - connected_clients is 1, blocked_clients is 0 | connected_clients=1 blocked_clients=0.
一、nagios配置过程详解
1、nagios默认配置文件介绍
nagios安装完毕后,默认的配置文件在/usr/local/nagios/etc目录下,每个文件或目录含义如下表所示:
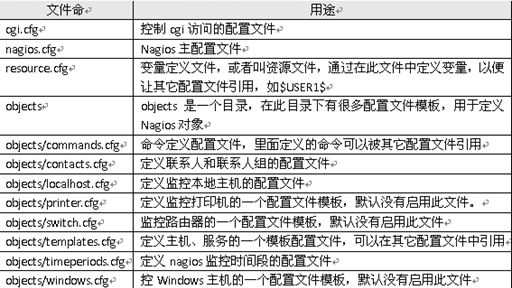
2、配置文件之间的关系
在nagios的配置过程中涉及到的几个定义有:主机、主机组,服务、服务组,联系人、联系人组,监控时间,监控命令等,从这些定义可以看出,nagios各个配置文件之间是互为关联,彼此引用的。
成功配置出一台nagios监控系统,必须要弄清楚每个配置文件之间依赖与被依赖的关系,最重要的有四点:
第一:定义监控哪些主机、主机组、服务和服务组
第二:定义这个监控要用什么命令实现,
第三:定义监控的时间段,
第四:定义主机或服务出现问题时要通知的联系人和联系人组。
3、开始配置nagios
为了能更清楚的说明问题,同时也为了维护方便,建议将nagios各个定义对象创建独立的配置文件:
即为:
创建hosts.cfg文件来定义主机和主机组
创建services.cfg文件来定义服务
用默认的contacts.cfg文件来定义联系人和联系人组
用默认的commands.cfg文件来定义命令
用默认的timeperiods.cfg来定义监控时间段
用默认的templates.cfg文件作为资源引用文件
(1)templates.cfg文件
nagios主要用于监控主机资源以及服务,在nagios配置中称为对象,为了不必重复定义一些监控对象,Nagios引入了一个模板配置文件,将一些共性的属性定义成模板,以便于多次引用。这就是templates.cfg的作用。
下面详细介绍下templates.cfg文件中每个参数的含义:
(2)resource.cfg文件
resource.cfg是nagios的变量定义文件,文件内容只有一行:
其中,变量$USER1$指定了安装nagios插件的路径,如果把插件安装在了其它路径,只需在这里进行修改即可。需要注意的是,变量必须先定义,然后才能在其它配置文件中进行引用。
(3)理解Nagios宏及其工作机制
Nagios配置非常灵活,继承和引用是一大特征,另一个重要特征就是可以在命令行的定义里使用宏,通过定义宏,nagios可以灵活的获取主机、服务和其它对象的信息。
宏的工作机制
在执行命令之前,nagios将对命令里的每个宏替换成它们应当取得的值。这种宏替换发生在Nagios执行各种类型的宏时候。例如主机和服务的检测、通知、事件处理等。
宏的分类:
默认宏、按需而成的宏、用户自定制宏等。
默认宏:
主机IP地址宏
当在命令定义中使用主机或服务宏时,宏将要执行所用的值指向主机或服务所带有值。看下面这个例子,假定在check_ping命令定义里使用了一个主机对象,例如这样:
那么执行这个主机检测命令时展开并最终执行的将是这样的:
命令参数宏
同样你可以向命令传递参数,这样可以保证命令定义更具通用性。参数指定在对象(象主机或服务)中定义,用一个“!”来分隔,例如这样:
在上例中,服务的检测命令中含有两个参数(请参考$ARGn$宏),而$ARG1$宏将是"200.0,80%",同时$ARG2$将是"400.0,40%"(都不带引号)。假定使用之前的主机定义并这样来定义你的check_ping命令:
那么对于服务的检测命令最终将是这样子的:
Nagios可用的全部的宏
主机宏
$HOSTNAME$ 主机简称(如"web"),取自于主机定义里的host_name域
$HOSTADDRESS$ 主机地址。取自于主机定义里的address域
服务宏
$SERVICESTATE$ 服务状态描述,有w,u,c
$SERVICEDESC$ 对当前服务的描述
联系人宏
$CONTACTNAME$ 表示联系人,在联系人文件中定义
通知宏
$NOTIFICATIONTYPE$ 返回下面信息:("PROBLEM", "RECOVERY", "ACKNOWLEDGEMENT", "FLAPPINGSTART", "FLAPPINGSTOP", "FLAPPINGDISABLED", "DOWNTIMESTART", "DOWNTIMEEND", or "DOWNTIMECANCELLED").
日期/时间宏
$LONGDATETIME$ 当前的日期/时间戳
文件宏
$LOGFILE$ 日志文件的保存位置。
$MAINCONFIGFILE$ 主配置文件的保存位置。
其他宏
$ADMINEMAIL$ 全局的管理员EMail地址
$ARGn$ 指向第n个命令传递参数(通知、事件处理、服务检测等)。Nagios支持最多32个参数宏
(4)commands.cfg文件
此文件默认是存在的,无需修改即可使用,当然如果有新的命令需要加入时,在此文件进行添加即可。这里并未列出文件的所有内容,仅仅介绍了配置中用到的一些命令。
(5) hosts.cfg文件
此文件默认不存在,需要手动创建,hosts.cfg主要用来指定被监控的主机地址以及相关属性信息,一个配置好的实例如下:
(6) services.cfg文件
此文件默认也不存在,需要手动创建,services.cfg文件主要用于定义监控的服务和主机资源,例如监控http服务、ftp服务、主机磁盘空间、主机系统负载等等。
(7) contacts.cfg文件
contacts.cfg是一个定义联系人和联系人组的配置文件,当监控的主机或者服务出现故障,nagios会通过指定的通知方式(邮件或者短信)将信息发给这里指定的联系人或者使用者。
(8) timeperiods.cfg文件
此文件只要用于定义监控的时间段,下面是一个配置好的实例:
(9) cgi.cfg文件
此文件用来控制相关cgi脚本,如果想在nagios的web监控界面执行cgi脚本,例如重启nagios进程、关闭nagios通知、停止nagios主机检测等,这时就需要配置cgi.cfg文件了。
由于nagios的web监控界面验证用户为ixdba,所以只需在cgi.cfg文件中添加此用户的执行权限就可以了,需要修改的配置信息如下:
(10) nagios.cfg文件
Nagios.cfg默认的路径为/usr/local/nagios/etc/nagios.cfg,是nagios的核心配置文件,所有的对象配置文件都必须在这个文件中进行定义才能发挥其作用,这里只需将对象配置文件在Nagios.cfg文件中进行引用即可。
==================================================================================================================================================================================
主配置文件 nagios.cfg 需要更改的地方:
#cfg_file=/usr/local/nagios/etc/objects/localhost.cfg
interval_length=1 ; 间隔时间基准由 60s 改为 1s
command_check_interval=10s ; 命令检查时间间隔,-1 表示尽可能频繁的进行检查
date_format=iso8601 ; 日期格式
objects/contacts.cfg 用来定义联系人:
define contact {
contact_name sa
alias System Administrator
service_notification_period 24×7
host_notification_period 24×7
service_notification_options w,u,c,r
host_notification_options d,u,r
service_notification_commands notify-service-by-email
host_notification_commands notify-host-by-email
email [email protected]
}
定义联系人组
define contactgroup {
contactgroup_name admins
alias Administrator Group
members sa ; 添加其它联系人用 “,” 分隔
}
主机监控的配置
define host {
host_name host_name ; 简短的主机名称。
alias alias ; 别名,可以更详细的说明主机。
address address ; IP 地址,也可以写主机名。如果不定义这个值, nagio 将会用 host_name 去寻找主机。
parents host_names ; 上一节点的名称,也就是指从 nagios 服务器到被监控主机之间经过的节点,可以是路由器、交换机、主机等等。
hostgroups hostgroup_names ; 简短的主机组名称。
check_command command_name ; 检查命令的简短名称,如果此项留空, nagios 将不会去判断主机是否 alive 。
max_check_attempts 整数 ; 当检查命令的返回值不是 “OK” 时,重试的次数。
check_interval 数字 ; 循环检查的间隔时间。
active_checks_enabled [0/1] ; 是否启用 “active_checks”
passive_checks_enabled [0/1] ; 是否启用 “passive_checks” ,及“被动检查”
check_period timeperiod_name ; 检测时间段简短名称,这只是个名称,具体的时间段要写在其他的配置文件中。
obsess_over_host [0/1] ; 是否启用主机操作系统探测。
check_freshness [0/1] ; 是否启用 freshness 检查。freshness 检查是对于启用被动检查模式的主机而言的,其作用是定期检查主机报告的状态信息,如果该状态信息已经过期,freshness 将会强制做主机检查。
freshness_threshold 数字 ; fressness 的临界值,单位为秒。 如果定义为 “0″ ,则为自动定义。
event_handler command_name ; 当主机发生状态改变时,采用的处理命令的简短的名字(可以在 commands.cfg 中对其定义)
event_handler_enabled [0/1] ; 是否启用 event_handler
low_flap_threshold 数字 ; 抖动的下限值。抖动,即在一段时间内,主机(或服务)的状态值频繁的发生变化。
high_flap_threshold 数字 ; 抖动的上限值。
flap_detection_enabled [0/1] ; 是否启用抖动检查。
process_perf_data [0/1] ; 是否启用 processing of performance data
retain_status_information [0/1] ; 程序重启时,是否保持主机状态相关的信息。
retain_nonstatus_information [0/1] ; 程序重启时,是否保持主机状态无关的信息。
contact_groups contact_groups ; 联系人组,在此组中的联系人都会收到主机的提醒信息。
notification_interval 整数 ; 重复发送提醒信息的最短间隔时间。默认间隔时间是 “60″ 分钟。如果这个值设置为 “0″ ,将不会发送重复提醒。
notification_period timeperiod_name ; 发送提醒的时间段。非常重要的主机(服务)定义为 24×7 ,一般的主机(服务)就定义为上班时间。如果不在定义的时间段内,无论发生什么问题,都不会发送提醒。
notification_options [d,u,r,f] ; 发送提醒包括的情况: d = 状态为 DOWN , u = 状态为 UNREACHABLE , r = 状态恢复为 OK , f = flapping
notifications_enabled [0/1] ; 是否开启提醒功能。”1″ 为开启,”0″ 为禁用。一般,这个选项会在主配置文件 (nagios.cfg) 中定义,效果相同。
stalking_options [o,d,u] ; 持续状态检测参数,o = 持续的 UP 状态 , d = 持续的 DOWN 状态 , u = 持续的 UNREACHABLE 状态
}
服务监控的配置
define service {
host_name host_name
service_description service_description
servicegroups servicegroup_names
is_volatile [0/1]
check_command command_name
max_check_attempts
normal_check_interval
retry_check_interval
active_checks_enabled [0/1]
passive_checks_enabled [0/1]
check_period timeperiod_name
parallelize_check [0/1]
obsess_over_service [0/1]
check_freshness [0/1]
freshness_threshold
event_handler command_name
event_handler_enabled [0/1]
low_flap_threshold
high_flap_threshold
flap_detection_enabled [0/1]
process_perf_data [0/1]
retain_status_information [0/1]
retain_nonstatus_information [0/1]
notification_interval
notification_period timeperiod_name n
otification_options [w,u,c,r,f]
notifications_enabled [0/1]
contact_groups contact_groups
stalking_options [o,w,u,c]
}
服务监控的配置和主机监控的配置较为相似,就不一一说明了。
间隔时间的计算方法为:
normal_check_interval x interval_length 秒
retry_check_interval x interval_length 秒
notification_interval x interval_length 秒
主机监控配置的例子
define host {
host_name web1
alias web1
address 192.168.0.101
contact_groups admins
check_command check-host-alive
max_check_attempts 5
notification_interval 0
notification_period 24×7
notification_options d,u,r
}
对主机 web1 进行 24×7 的监控,默认会每 10 秒检查一次状态,累计五次失败就发送提醒,并且不再重复发送提醒。
服务监控配置的例子
define service {
host_name web1
service_description check_http
check_period 24×7
max_check_attempts 3
normal_check_interval 30
contact_groups admins
retry_check_interval 15
notification_interval 3600
notification_period 24×7
notification_options w,u,c,r
check_command check_http
}
配置解释: 24×7 监控 web1 主机上的 HTTP 服务,检查间隔为 30 秒, 检查失败后每 15 秒再进行一次检查,累计三次失败就认定是故障并发送提醒。
联系人组是 admins 。提醒后恢复到 30 秒一次的 normal_check_interval 检查。如果服务仍然没有被恢复,每个小时发送一次提醒。
如果要检测其他服务,例如,要检查 ssh 服务是否开启,更改如下两行:
service_description check_ssh
check_command check_ssh
为方便管理,对配置文件的分布做了如下修改:
nagios.cfg 中增加了:
cfg_dir=/usr/local/nagios/etc/hosts
cfg_dir=/usr/local/nagios/etc/services
在 hosts 目录中,为不同类型的主机创建了配置文件,如: app.cfg cache.cfg mysql.cfg web.cfg
并创建了 hostgroup.cfg 文件对主机进行分组,如:
define hostgroup {
hostgroup_name app-hosts
alias APP Hosts
members app1,app2
}
在 services 目录中创建了各种服务的配置文件,如: disk.cfg http.cfg load.cfg mysql.cfg
并创建了 servicegroup.cfg 文件对服务进行分组,如:
define servicegroup {
servicegroup_name disk
alias DISK
members cache1,check_disk,cache2,check_disk
}