两种增量更新方案
标签:
技术文章
| 发表时间:2014-06-05 23:16 | 作者:bang
出处:http://blog.cnbang.net
在邮件/日历/SNS等客户端里,客户端数据要不断与服务端进行数据同步,在同步过程中,只拉取有修改的数据,称为增量更新,增量更新方案一般有两种,一是对比,二是日志。
对比
对比就是客户端请求服务端所有关键数据,跟本地已有的数据进行对比,筛选出增删改的数据进行更新。
用对比方法的好处是服务端什么都不用做,坏处是客户端逻辑复杂,耗网络流量。在这种方案里,数据的新增和删除很容易判断,根据客户端数据的id列表和服务端数据的id列表进行对比就行,若要判断哪个数据有修改则比较麻烦,需要取回数据进行对比,如果从服务端拉回所有对所有数据进行对比会很耗网络流量,有一个优化方式,就是对每个数据的修改进行标记。
以日历为例,一个日历可修改的字段很多,例如时间段,内容,邀请人等,全部拉回来对比不现实,对此可以在服务端给每个日历事件新增一个字段tag,表示这个日历事件的版本,服务端更新一个日历事件时会同时更新这个tag,客户端只需要取回每个id对应的tag,跟本地保存的tag对比,不一致表示这个日历事件已经更新,再去获取日历实体就完成更新了。
若服务端因为某些原因无法给每个数据保存一个版本标记,可以实时计算,在客户端和服务端约定一个算法,把所有可变参数拿出来,通过特定算法hash出一个值,对比这个hash值判断是否需要更新。
邮件协议IMAP,日历协议CalDAV就是用这种方式做增量更新,IMAP并没有做上述的优化,在判断邮件有没有更新时只能乖乖把所有数据请求回来对比,数据是XML,算是相当低效的协议。CalDAV给每个日历事件加了上述的tag,直接对比即可知道是否需要更新。
日志
日志指服务端记录数据的每一次增删改,用一个类似版本号的sync-key标记这次修改,客户端通过一个旧的sync-key向服务端请求,服务端返回这个sync-key与最新sync-key之间所有的修改给客户端,完成增量更新。
这个sync-key在服务端的实现上可以是时间,也可以是一个自增的id,sync-key之间有顺序关系就行。在一个数据集里,每次数据有更新,就新增一个sycn-key,并记录这次更新。图示这个过程:
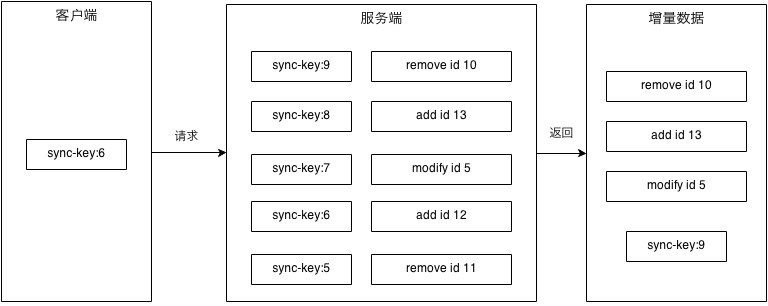
这个方案客户端逻辑很简单,但服务端负担较大,每次数据更新都要记录,客户端请求时需要查询给出相应的数据。这个方案在实际操作中还有两个问题:
一是时间长了服务端保存数据量过大。可以通过限制记录的条数解决,超过限制就删除最旧的记录。这样做会出现一个问题,若客户端带着在服务端已被删除的sync-key上来请求,该如何处理?一般做法是返回一个错误给客户端,让客户端重新拉取所有数据。
二是若客户端sync-key过旧,增量数据可能过大。客户端数据太老,有太多数据需要更新,若一次性返回所有增量数据,这个请求可能会很大,请求时间太长,成功率也会很低。解决方式是分多次请求,客户端和服务端可以约定一个字段作为阀值,服务端每次返回的增量数据量不超过这个阀值,若总数据超过这个阀值,则分多次请求,通过每次请求返回的sync-key定位下次请求该返回哪些数据。例如客户端sync-key是100,服务端最新sync-key是1000,阀值是50,客户端第一次带sync-key=100请求,服务端第一次返回sycn-key 100-150这一段增量数据,并返回sync-key=150,并有一个值告诉客户端这个sync-key还不是最新,客户端再带上sync-key=150请求,以此类推,直到sync-key=1000。
微软的Exchange/ActiveSync就是用这种方式实现增量更新,ActiveSync还用WBXML压缩了数据,更适用于移动端。此外日历协议CalDAV的也有一个扩展协议 RFC6578使用这种方式。ActiveSync和CalDAV扩展协议都有分多次请求增量数据的策略。
————
对于Timeline式的数据,增量更新方式多是以上两种,或者这两种的变体,可以根据业务特性修改或简化其中的逻辑,例如对于微博Timeline,它可以不考虑微博的修改,不考虑同步评论转发数的变化,不考虑同步删除的微博,并且每一条微博都有一个递增的id,那它的增量更新逻辑就很简单,只需要把客户端最新一条微博的id作为since_id传到服务端,返回比这个id更新的微博就行了,这里微博id相当于日志方式的sync-key,算是对日志方式的一种简化。
相关 [更新] 推荐:
Shareaza 2.7.8.0 更新
- - eMule Fans 电骡爱好者Shareaza 是一款著名的开源 P2P 文件共享客户端(P2P Filesharing Client),在著名开源项目网站 Sourceforge 下载量常年排名前十,支持多种文件共享和发布网络是它的特点,目前支持的有:Gnutella2、Gnutella、eDonkey2000(电驴)、HTTP、FTP、BitTorrent(BT)、DirectConnect(DC++).
Google Toolbar for Firefox停止更新
- ccyuling - SolidotGoogle多个Firefox扩展程序都没有随Firefox的更新而更新,如Google工具栏和最近才发布的按图搜索的扩展都不支持Firefox 5. Firefox 5实际上是Firefox 4的安全更新,兼容Firefox 5并不很难. Google官方博客解释说,Google Toolbar for Firefox提供的许多功能都已经内置在浏览器中.
apjp、goagent和ASProxyWing更新
- jason - iGFW上次提到PHP代理工具APJP把http和https代理端口分开很利于使用autoproxy,这次更新的APJP_LOCAL-0.8.3中,作者已经把http和https代理端口合二为一了,这下使用autoproxy就方便多了. 使用教程可以参考:http://code.google.com/p/apjp/wiki/InstallGuide 、 http://igfw.tk/archives/3758.
近期暂停更新
- colibidoyu - 时寒冰由于被临时抽调参与一项课题研究,本人博客和微博近期停止更新.
Linux基金会更新FAQ
- ArmadilloCommander - Solidot51开源社区 写道 "之前报道Linux.com、kernel.org等皆无法访问处于安全维护中,目前服务尚未恢复.不过Linux基金会已更新官方公告,发布FAQ:“为了尽快恢复服务,我们的团队正在日夜不停地工作. 服务会在未来几天恢复,我们将第一时间通知大家每一步的进度. 虽然Linux基金会存储的密码是加密的,但攻击者会尝试暴力破解,如果你使用该帐号用于其他网站,建议立即更改您的密码.
Linux.com 遭受入侵(更新)
- leafduo - LinuxTOYLinux 基金会旗下的 Linux.com 和 LinuxFoundation.org 网站,由于发现安全漏洞,进入离线维护状态. 感谢 gbraad 提供消息. Linux Foundation infrastructure including LinuxFoundation.org, Linux.com, and their subdomains are down for maintenance due to a security breach that was discovered on September 8, 2011.
【更新】NVIDIA Tegra 3 详解
- clowwindy - 爱范儿 · Beats of Bits随着华硕(ASUS) Transformer Prime 的发布,“理论上最快”的四核心 ARM 处理器 NVIDIA Tegra 3 终于登场了. 回望一年以前,我们还处于对双核 Cortex-A9 的极度渴望中,而现在四核心的 SoC 即将量产,它会为手持数码设备带来怎样的革新. 巧妙的架构:4 + 1 核心.
Android handler异步更新
- - 博客园_首页private static final int MSG_SUCCESS = 0;// 获取图片成功的标识. private static final int MSG_FAILURE = 1;// 获取图片失败的标识. mImageView.setImageBitmap((Bitmap) msg.obj);// imageview显示从网络获取到的logo.
Apple 发布 iOS 8.0.2 更新
- - 果迷网在昨天 Apple 闹出 iOS 8.0.1 的”乌龙”事件之后,今天 Apple 上线了 iOS 8.0.2 的更新,修正了 iOS 8.0.1 导致的 Touch ID 和 蜂窝数据网络不能在 iPhone 6 机型上工作的问题,同时还修复了其他一系列 Bug. 修正了 iOS 8.0.1 在 iPhone 6 和 iPhone 6 Plus 上蜂窝数据和 Touch ID 不工作的问题;.