Oracle sql语句执行顺序
- - 数据库 - ITeye博客sql语法的分析是从右到左. 一、sql语句的执行步骤:. 1)语法分析,分析语句的语法是否符合规范,衡量语句中各表达式的意义. 2)语义分析,检查语句中涉及的所有数据库对象是否存在,且用户有相应的权限. 3)视图转换,将涉及视图的查询语句转换为相应的对基表查询语句. 4)表达式转换, 将复杂的 SQL 表达式转换为较简单的等效连接表达式.
sql语法的分析是从右到左
一、sql语句的执行步骤:
1)语法分析,分析语句的语法是否符合规范,衡量语句中各表达式的意义。
2)语义分析,检查语句中涉及的所有数据库对象是否存在,且用户有相应的权限。
3)视图转换,将涉及视图的查询语句转换为相应的对基表查询语句。
4)表达式转换, 将复杂的 SQL 表达式转换为较简单的等效连接表达式。
5)选择优化器,不同的优化器一般产生不同的“执行计划”
6)选择连接方式, ORACLE 有三种连接方式,对多表连接 ORACLE 可选择适当的连接方式。
7)选择连接顺序, 对多表连接 ORACLE 选择哪一对表先连接,选择这两表中哪个表做为源数据表。
8)选择数据的搜索路径,根据以上条件选择合适的数据搜索路径,如是选用全表搜索还是利用索引或是其他的方式。
9)运行“执行计划”
二、oracle 共享原理:
ORACLE将执行过的SQL语句存放在内存的共享池(shared buffer pool)中,可以被所有的数据库用户共享。
当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路径.。这个功能大大地提高了SQL的执行性能并节省了内存的使用。
三、oracle 语句提高查询效率的方法:
1:where column in(select * from ... where ...);
2:... where exists (select 'X' from ...where ...);
第二种格式要远比第一种格式的效率高。
在Oracle中可以几乎将所有的IN操作符子查询改写为使用EXISTS的子查询。
使用EXIST,Oracle系统会首先检查主查询,然后运行子查询直到它找到第一个匹配项,
这就节省了时间Oracle系统在执行IN子查询时,首先执行子查询,并将获得的结果列表存放在在一个加了索引的临时表中。
避免使用having子句。HAVING 只会在检索出所有记录之后才对结果集进行过滤。
这个处理需要排序,总计等操作。如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销。
四、SQL Select语句完整的执行顺序:
1、from子句组装来自不同数据源的数据;
2、where子句基于指定的条件对记录行进行筛选;
3、group by子句将数据划分为多个分组;
4、使用聚集函数进行计算;
5、使用having子句筛选分组;
6、计算所有的表达式;
7、select 的字段;
8、使用order by对结果集进行排序。
SQL语言不同于其他编程语言的最明显特征是处理代码的顺序。在大多数据库语言中,代码按编码顺序被处理。但在SQL语句中,第一个被处理的子句式FROM,而不是第一出现的SELECT。SQL查询处理的步骤序号:
1 (8)SELECT (9) DISTINCT (11) <TOP_specification> <select_list>
2 (1) FROM <left_table>
3 (3) <join_type> JOIN <right_table>
4 (2) ON <join_condition>
5 (4) WHERE <where_condition>
6 (5) GROUP BY <group_by_list>
7 (6) WITH {CUBE | ROLLUP}
8 (7) HAVING <having_condition>
9 (10) ORDER BY <order_by_list>
以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只有最后一步生成的表才会会给调用者。如果没有在查询中指定某一个子句,将跳过相应的步骤。
逻辑查询处理阶段简介:
1、 FROM:对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1。
2、 ON:对VT1应用ON筛选器,只有那些使为真才被插入到TV2。
3、 OUTER (JOIN):如果指定了OUTER JOIN(相对于CROSS JOIN或INNER JOIN),保留表中未找到匹配的行将作为外部行添加到VT2,生成TV3。如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表位置。
4、 WHERE:对TV3应用WHERE筛选器,只有使为true的行才插入TV4。
5、 GROUP BY:按GROUP BY子句中的列列表对TV4中的行进行分组,生成TV5。
6、 CUTE|ROLLUP:把超组插入VT5,生成VT6。
7、 HAVING:对VT6应用HAVING筛选器,只有使为true的组插入到VT7。
8、 SELECT:处理SELECT列表,产生VT8。
9、 DISTINCT:将重复的行从VT8中删除,产品VT9。
10、ORDER BY:将VT9中的行按ORDER BY子句中的列列表顺序,生成一个游标(VC10)。
11、TOP:从VC10的开始处选择指定数量或比例的行,生成表TV11,并返回给调用者。
Oracle中SQL语句执行过程中,Oracle内部解析原理如下:
1、当一用户第一次提交一个SQL表达式时,Oracle会将这SQL进行Hard parse,这过程有点像程序编译,检查语法、表名、字段名等相关信息(如下图),这过程会花比较长的时间,因为它要分析语句的语法与语义。然后获得最优化后的执行计划(sql plan),并在内存中分配一定的空间保存该语句与对应的执行计划等信息。
2、当用户第二次请求或多次请求时,Oracle会自动找到先前的语句与执行计划,而不会进行Hard parse,而是直接进行Soft parse(把语句对应的执行计划调出,然后执行),从而减少数据库的分析时间。
注意的是:Oracle中只能完全相同的语句,包大小写、空格、换行都要求一样时,才会重复使用以前的分析结果与执行计划。
分析过程如下图:
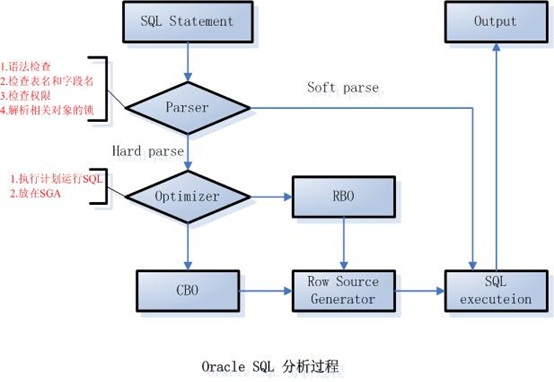
对于大量的、频繁访问的SQL语句,如果不采用Bind 变量的方式,哪Oracle会花费大量的Shared latch与CPU在做Hard parse处理,所以,要尽量提高语句的重用率,减少语句的分析时间,通过了解Oracle SQL语句的分析过程可以明白Oracle的内部处理逻辑,并在设计与实现上避免。
在用JDBC或其它持久化数据(如Hibernate,JDO等)操作时,尽量用占位符(?)
ORACLE sql 的处理过程大致如下:
1.运用HASH算法,得到一个HASH值,这个值可以通过V$SQLAREA.HASH_VALUE 查看
2.到shared pool 中的 library cache 中查找是否有相同的HASH值,如果存在,则无需硬解析,进行软解析
3.如果shared pool不存在此HASH值,则进行语法检查,查看是否有语法错误
4.如果没有语法错误,就进行语义检查,检查该SQL引用的对象是否存在,该用户是否具有访问该对象的权限
5.如果没有语义错误,对该SQL进行解析,生成解析树,执行计划
6.生成ORACLE能运行的二进制代码,运行该代码并且返回结果给用户
硬解析和软解析都在第5步进行
硬解析通常是昂贵的操作,大约占整个SQL执行的70%左右的时间,硬解析会生成执行树,执行计划,等等。
当再次执行同一条SQL语句的时候,由于发现library cache中有相同的HASH值,这个时候不会硬解析,而会软解析,
那么软解析究竟是干了什么呢?其实软解析就是跳过了生成解析树,生成执行计划这个耗时又耗CPU的操作,直接利用生成的执行计划运行
该SQL语句。
下面摘抄eygle深入解析ORACLE 中关于SQL执行过程的描述
1.首先获得library cache latch,根据SQL的HASH_VALUE在library cache中查找是否存在此HASH_VALUE,如果找到这个HASH_VALUE,称之为软解析,Server获得改SQL执行计划转向第4步,如果找不到共享代码就进行硬解析。
2.释放library pool cache,获得shared pool latch,查找并锁定自由空间(在bucket 中查找chunk)。如果找不到,报ORA-04031错误。
3.释放shared pool latch,重新获得library cache latch,将SQL执行计划放入library cache中。
4.释放library cache latch,保持null模式的library cache pin/lock。
5.开始执行。
Library cache latch可以理解为硬/软解析的时候发生的,因为解析的时候会搜索library cache,所以会产生library cache latch
Library cache pin 是在执行的阶段发生的。