PostgreSQL Cluster系列教程
- - 数据库 - ITeye博客PostgreSQL9.1 PITR示例. 本教程是PostgreSQL Cluster系列教程的一部分,该系列包括:. PostgreSQL9.1 PITR示例 (该教程主要阐述DBA如何基于WAL日志做备份恢复). PostgreSQL9.1 Warm-Standby ---之基于拷贝WAL文件的方法 (file-based log shipping).
本教程是PostgreSQL Cluster系列教程的一部分,该系列包括:
本教程尽量写的简单,以让初学者可以很轻松的理解和动手实验,而尽量不出错。
关于Continuous Archiving,先说原理,咱看图说话:
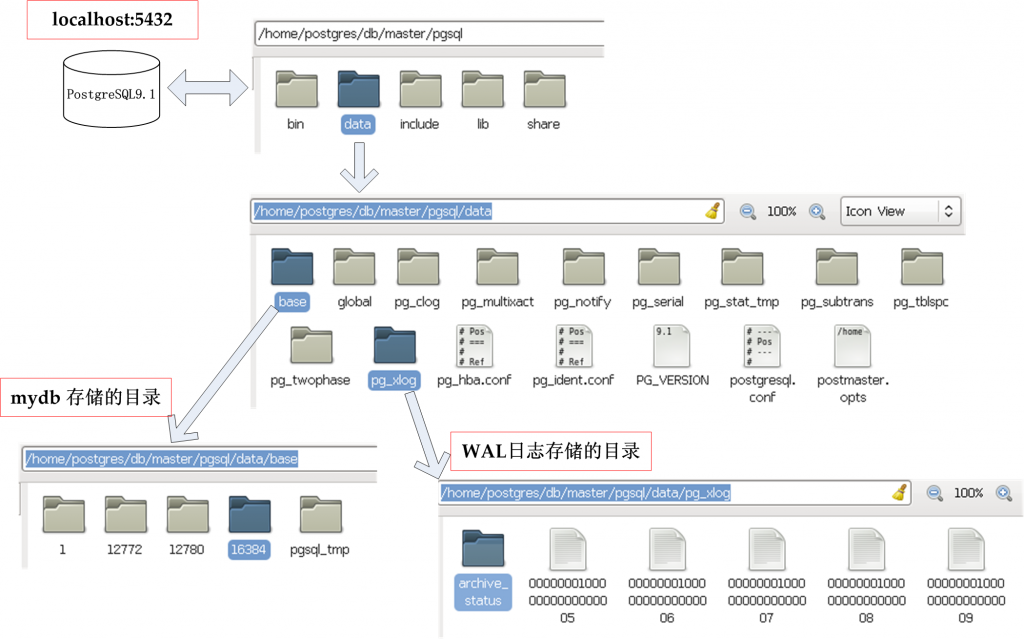
从该图中,我们看到PostgreSQL会不断的更新WAL日志所在的目录,并最终写到数据库存储文件中(如上图中的mydb数据库所在的/home/postgres/db/master/pgsql/data/base/16384目录中)。故我们可以会得出这么一个结论:
WAL目录,即图中的/home/postgres/db/master/pgsql/data/pg_xlog目录,其下的每个文件(即WAL段)大小为16MB,那么总共有多少个16M的文件呢?(参阅 这里:There will always be at least one WAL segment file, and will normally not be more than (2 + checkpoint_completion_target) * checkpoint_segments + 1 or checkpoint_segments + wal_keep_segments + 1 files. ..., Ordinarily, when old log segment files are no longer needed, they are recycled),从上面这段话还可以看出,当到达极限时,会循环利用,所以pg_xlog目录不会无限增大。
我们还会得出另外一个结论:
也有朋友会提问了,既然WAL日志会不断的存起来,干嘛还要备份最初的数据库呀,这是因为WAL日志并不会永远保存,还记得WAL目录下的各个16M文件会循环利用吗,这可能会把最开始的WAL日志丢掉,故还得备份原始的data目录。
关于WAL目录中的各个16M文件,我们再多说一下,并不是写一下这个文件就备份一次,而是等写满了16M的时候才备份,这说明了什么,这说明如果还没到16M的时候,这个WAL是还没备份的,这也就是下面这段话( 参考自)中所解释的:
If you are concerned about being able to recover right up to the current instant, you may want to take additional steps to ensure that the current, partially-filled WAL segment is also copied someplace. This is particularly important if your server generates only little WAL traffic (or has slack periods where it does so), since it could take a long time before a WAL segment file is completely filled and ready to archive.
即:部分填充的WAL段(partially-filled WAL segment),你得自己想办法备份,这也是下面所说明的这句话(摘自 这里)的意思:
3.7 定期备份WAL新生成日志
如果单独通过archive_command来备份WAL的话, 能根本就做不到PITR, 因为pg_xlog/下面可能还有数据没有备份到archive_command指定的目录里;所以需要另外写脚本把/data/pg_xlog/下的 WAL日志文件备份到预设的归档目录下,保证产生的WAL日志都已归档, 这里写了个脚本,每五分钟执行一次
一个更好的示意图如下(摘自 Getting ready for PostgreSQL 9.1,第25页):

更加清楚的表明了备份的内容,即data和wal日志,好了,唠叨了这么多,我们开工:
实验环境:
下面是各步骤:
1.安装PostgreSQL9.1,创建示例数据库mydb,和表foo
为了后续教程系列warm-standby和hot-standby示例的方便,此处把PostgreSQL安装在:/home/postgres/db/master里,即您首先需建立/home/postgres/db/master/psql/data目录。
[postgres@localhost ~]cd/home/postgres/develop/[postgres@localhostdevelop] tar zxf postgresql-9.1.2.tar.gz
[postgres@localhost develop]cdpostgresql−9.1.2[postgres@localhostdevelop] ./configure --prefix=/home/postgres/db/master/pgsql --with-includes=/usr/local/readline/include --with-libraries=/usr/local/readline/lib
注意上面的readline库路径,请用whereis命令查看readline在哪,并做相应修改,如果没有,请放入RHEL6光盘,在System->Administration->Add/Remove Software 安装. 如果您对安装PostgreSQL不熟悉,请参考: rhel6+postgresql8.4+postgis1.4+eclipse CDT3.6 调试环境搭建
[postgres@localhost develop]make[postgres@localhostdevelop] make install
好,接下来初始化数据库:
[postgres@localhost postgresql-9.1.2]/home/postgres/db/master/pgsql/bin/initdb−D/home/postgres/db/master/pgsql/data然后,启动数据库服务器,并创建示例数据库mydb[postgres@localhostpostgresql−9.1.2]/home/postgres/db/master/pgsql/bin/postmaster -D /home/postgres/db/master/pgsql/data
LOG: database system was shut down at 2012-02-16 10:07:15 CST
LOG: database system is ready to accept connections
LOG: autovacuum launcher started
[postgres@localhost ~]/home/postgres/db/master/pgsql/bin/createdbmydb执行下面,如果出现如下内容,则成功:[postgres@localhost ]/home/postgres/db/master/pgsql/bin/psql mydb
psql (9.1.2)
Type "help" for help.
mydb=#
然后创建示例表foo,为了简单,咱就只生成100万条记录(若您想生成更加复杂的测试数据,请参阅 Postgresql生成大量测试数据 ):
mydb=# create table foo(id bigint);
mydb=# insert into foo select * from generate_series(1,1000000);
好,我们看一下到底这100万条占多大硬盘空间:
mydb=# SELECT oid from pg_database where datname='mydb';
oid
-------
16384
(1 row)
然后开CMD:
[postgres@localhost ~]cd/home/postgres/db/master/pgsql/data/base/16384[postgres@localhost16384] du -sh
41M
40多M,不大不小,满足我们笔记本上测试的需要。
2.设置postgresql.conf
先关闭数据库,创建WAL日志将被备份的目录/home/postgres/archive。
既然上面配置好了一台普通的PostgreSQL服务器,那我们就来配置一下服务器了,以让其支持不断的对外输出WAL日志。那配置什么呢,根据9.1手册里 24.3.1. Setting Up WAL Archiving知道,要配置:
To enable WAL archiving, set the wal_level configuration parameter to archive (or hot_standby), archive_mode to on, and specify the shell command to use in the archive_command configuration parameter.
即postgresql.conf文件中的三个参数:
- wal_level = archive
- archive_mode = on
- archive_command = 'cp %p /home/postgres/archive/%f'
其中archive_command中%p会自动识别为WAL目录,你不用管,%f你也不用管。这个archive_command在什么时候执行呢,即PostgreSQL在每次WAL日志16MB段满的时候才执行,即把其拷贝到/home/postgres/archive中,那么为了想在不满的时候也备份,怎么办?也即可采用Linux中定时任务的方式来实现,即文《 Postgesql数据库备份与恢复实验 (PITR) 》中的“--每5分钟备份 (通过Crontab执行)....“,此处为简化本教程,不再说明,感兴趣的朋友可自行学习。
好了,配置完,重启服务器,看看有没异常,若没异常,则成功了一半,先别高兴。
3.做一次基础备份
先建立存储基础备份的目录:/home/postgres/base。
参考 24.3.2. Making a Base Backup,执行:
mydb=# SELECT pg_start_backup('bak20120216');
pg_start_backup
-----------------
0/6000020
(1 row)
其中bak20120216是标签,你可以随便改成自己可识别的,然后备份整个data目录,即把/home/postgres/db/master/psql/data/ 目录全部拷贝一份,并压缩,存储在/home/postgres/base中:
[postgres@localhost pgsql]cd/home/postgres/db/master/pgsql/[postgres@localhostpgsql] tar czvf /home/postgres/base/base_data.tar.gz data/
接下来:
mydb=# SELECT pg_stop_backup();
NOTICE: pg_stop_backup complete, all required WAL segments have been archived
pg_stop_backup
----------------
0/6000094
(1 row)
切换日志 postgres=# pg_switch_xlog();
此时表示备份成功,你可以查看/home/postgres/archive目录中是否有了备份的wal日志段了。
4.恢复
既然备份成功了,我们就得尝试尝试是不是可以恢复。
确保已经启动开数据库,打开psql,我们再在foo表中插入100万条新记录,使得foo的总记录数为200万条:
mydb=# insert into foo select * from generate_series(1,1000000);
假定此时由于某种原因我们新的插入100万条记录的数据库出问题了,我们的疑问是可否利用前面的“基础备份库”+“新插入100万条记录所产生的WAL备份日志”恢复呢?让我们看看如何一步步恢复:
首先关闭数据库。
接着把data目录改名:
[postgres@localhost pgsql]cd/home/postgres/db/master/pgsql/[postgres@localhostpgsql] mv data data_bk
然后把压缩备份的目录/home/postgres/base里的基础库解压缩到这里:
[postgres@localhost pgsql]tar−xzvf/home/postgres/base/basedata.tar.gz清空pgxlog,并创建pgxlog/archivestatus目录,删除postmaster.pid文件:[postgres@localhostpgsql] rm -r data/pg_xlog/
[postgres@localhost pgsql]mkdir−pdata/pgxlog/archivestatus[postgres@localhostpgsql] rm data/postmaster.pid
从share目录,拷贝一份recovery.conf:
[postgres@localhost pgsql]cp/home/postgres/db/master/pgsql/share/recovery.conf.sample/home/postgres/db/master/pgsql/data/recovery.conf编辑recovery.conf:restorecommand=′cp/home/postgres/archive//home/postgres/db/master/pgsql/bin/postmaster -D /home/postgres/db/master/pgsql/data
LOG: database system was interrupted; last known up at 2012-02-16 22:29:41 CST
LOG: starting archive recovery
LOG: restored log file "00000001000000000000000A" from archive
LOG: consistent recovery state reached at 0/AD37404
LOG: redo starts at 0/AD37404
cp: cannot stat `/home/postgres/archive/00000001000000000000000B': No such file or directory
LOG: could not open file "pg_xlog/00000001000000000000000B" (log file 0, segment 11): No such file or directory
LOG: redo done at 0/AD37404
LOG: restored log file "00000001000000000000000A" from archive
cp: cannot stat `/home/postgres/archive/00000002.history': No such file or directory
LOG: selected new timeline ID: 2
cp: cannot stat `/home/postgres/archive/00000001.history': No such file or directory
LOG: archive recovery complete
LOG: database system is ready to accept connections
LOG: autovacuum launcher started
打开psql:
[postgres@localhost ~]$ /home/postgres/db/master/pgsql/bin/psql mydb
psql (9.1.2)
Type "help" for help.
mydb=# select count(*) from foo;
count
---------
2000000
(1 row)
至此,恢复成功。
当然你也可以清除刚才没有删除而只重命名的data目录。
当然如何恢复到某一个时间点的transaction,即PITR,您可以再继续学习 24.3.4. Timelines。此教程不再讲述。
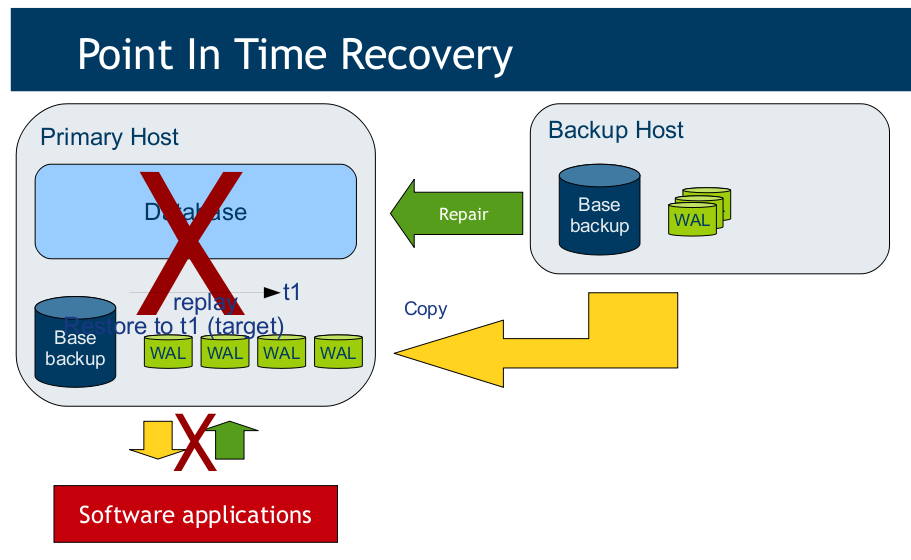
另外, Getting ready for PostgreSQL 9.1,第26页的PITR的示意图我没看明白,如下(研究过PITR的朋友请给我说):
参考:
[1] Postgesql数据库备份与恢复实验 (PITR) , http://francs3.blog.163.com/blog/static/405767272010729528450/
[2] Continuous Archiving and Point-in-Time Recovery (PITR), http://www.postgresql.org/docs/9.1/static/continuous-archiving.html
[3] Simple HA with PostgreSQL Point-In-Time Recovery
[4] How To Set Up An Active/Passive PostgreSQL Cluster With Pacemaker, Corosync, And DRBD (CentOS 5.5)
[5] PostgreSQL warm standby on ZFS crack
[6] HA+DRBD+Postgres - PostgresWest '08
[7] Replication in PostgreSQL (II) – Hot Standby/Streaming Replication
[8] postgres数据备份及恢复终结版