Pivotal开源基于PostgreSQL的数据库Greenplum
- - 博客园_新闻近日,Pivotal 宣布开源大规模并行处理(MPP)数据库 Greenplum,其架构是针对大型分析型数据仓库和商业智能工作负载专门设计的. 借助 MPP 这种高性能的系统架构,Greenplum 可以将 TB 级的数据仓库负载分解,并使用所有的系统资源并行处理单个查询. Greenplum 数据库基于 PostgreSQL 开源技术.
近日,Pivotal 宣布开源大规模并行处理(MPP)数据库 Greenplum,其架构是针对大型分析型数据仓库和商业智能工作负载专门设计的。借助 MPP 这种高性能的系统架构,Greenplum 可以将 TB 级的数据仓库负载分解,并使用所有的系统资源并行处理单个查询。
Greenplum 数据库基于 PostgreSQL 开源技术。本质上讲,它是多个 PostgreSQL 实例一起充当一个数据库管理系统。Greenplum 以 PostgreSQL 8.2.15 为基础构建,在 SQL 支持、特性、配置选项和终端用户功能方面非常像 PostgreSQL,用户操作 Greenplum 就跟平常操作 PostgreSQL 一样。不过,为了支持 Greenplum 数据库的并发结构,PostgreSQL 的内部构件经过了修补。例如,为了在所有并行的 PostgreSQL 数据实例上并发执行查询,系统目录、优化器、查询执行器以及事务管理器组件都经过了修改和增强。此外,Greenplum 还引入了针对商业智能工作负载优化 PostgreSQL 的特性。例如,增加了并行数据加载、资源管理、查询优化、存储增强。这些功能是标准 PostgreSQL 所不具备的。
Greenplum 数据库的架构如下:
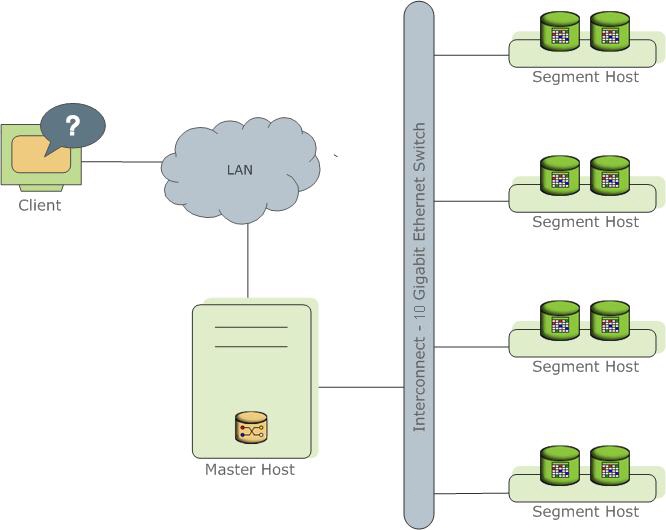
Greenplum master 是 Greenplum 数据库系统的入口,接受客户端连接及提交的 SQL 语句,将工作负载分发给其它数据库实例(segment 实例),由它们存储和处理数据。Greenplum interconnect 负责不同 PostgreSQL 实例之间的通信。Greenplum segment 是独立的 PostgreSQL 数据库,每个 segment 存储一部分数据。大部分查询处理都由 segment 完成。
根据 Pivotal 的开源公告,他们希望 Greenplum 会成为一个重大的里程碑,永久改变数据仓库这个行业。Greenplum 数据库与其它开源数据处理系统(如 Apache Hadoop、MySQL 甚或 PostgreSQL)的差别在架构和功能上都有体现。借助 MPP,Greenplum 在大型数据集上执行复杂 SQL 分析的速度比他们测试过的任何一个方案都要快。而借助 下一代查询优化技术,Greenplum 带来了其它开源方案中没有的数据管理质量特性、升级和扩展能力。他们相信,这样一款经过证明的、广泛采用的数据仓库开源将会在整个业界引发巨大的连锁反应。最重要的是,这降低了大规模实时数据分析的门槛,更多的公司可以参与到大数据所带来的挑战中来。
另据 InfoWorld 报道,数据库行业分析师 Curt Monash 将 Greenplum 视为分析型 RDBMS 的真正竞争者。而且,相比现有的产品(如 Teradata、 HP Vertica、 IBM Netezza 和 Oracle Exadata),其引入成本更低。Greenplum 作为一项服务似乎是个再简单不过的选择。它有一个为人熟知的名字和广泛的用户基础。MySQL 或 PostgreSQL 也通过类似的技术提供云端服务。但是,Greenplum 真要展现出其优势,需要做好两个方面的工作:一是从现有的 Greenplum 部署移植要简单;二是有一个可行的发展路线,要么可以通过其它云托管产品富集数据,要么集成新兴的分析技术,如 Spark。
在 Hacker News 上,Pivotal Labs 成员 jacques_chester 回答了多名网友的问题。网友 tlrobinson 提出:
为什么 Greenplum 以 PostgreSQL 8.2 为基础,而不是更新的版本?
对此,jacques_chester 解释说,“那是因为 Greenplum 最初从该版本派生。”网友 djokkataja 的问题也是围绕这一点:
现在有计划吗?Greenplum 最终是否会与现行的 PostgreSQL 开发有同等的特性,或者 Greenplum 主要还是遵循自己的发展路线?
jacques_chester 并没有明确回答这个问题,只是说,这取决于许多因素。同时,他还指出:
Greenplum 采用 PostgreSQL Wire Protocol。所有可以同 PostgreSQL 交互的工具都可以顺畅地同 Greenplum 交互。
还有网友担心 Greenplum 的单 master 会成为写入瓶颈,jacques_chester 答复说,这是 gpfdist 要解决的问题,只要正确使用,就可以实现批量并行加载,而且 master 不会成为瓶颈。
网友们还讨论了 Greenplum 与 ElasticSearch 的差别,感兴趣的读者可以进一步阅读。