缓存更新的套路
- - 酷 壳 – CoolShell.cn看到好些人在写更新缓存数据代码时, 先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中. 试想,两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库. 于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了.
There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
缓存失效问题被认为是计算机科学中最难的两件事之一,这篇文章来自翻译,内容主要包括缓存级别与缓存更新常见的几种模式。
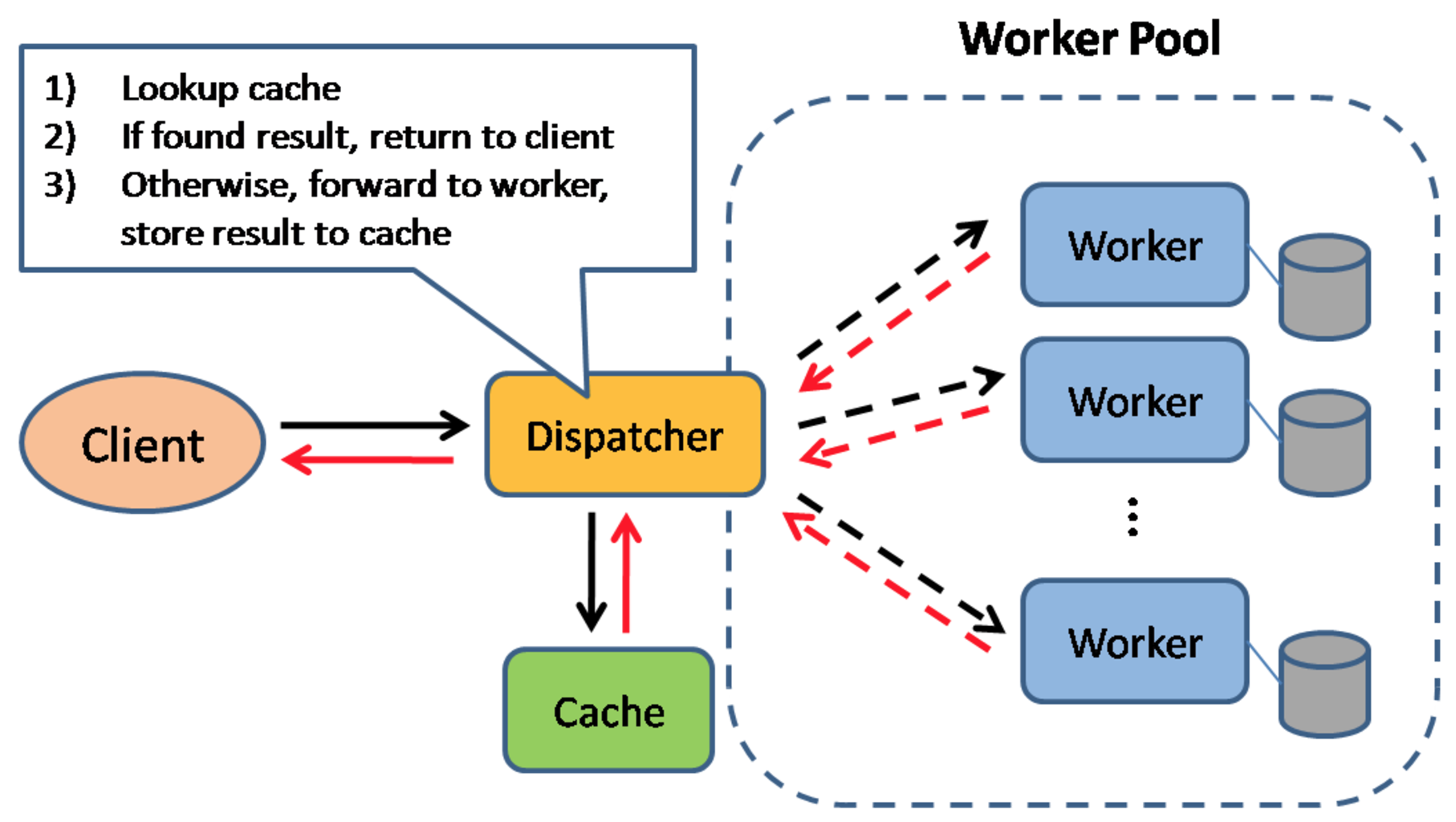
常见缓存应用模式
缓存常用来加快页面的加载速度,减少服务器或数据库服务的负载。缓存应用的常见模式如上图所示:
数据库常常得益于对均匀分布的数据的读写,但是热点数据使得这种均匀被打破,从而出现了系统瓶颈。通过数据库服务前置缓存服务,可以有效吸收不均匀的负载和抵挡流量高峰。
缓存级别关注的问题是 在 什么时候做缓存(When)以及 在 什么地方做缓存(Where),下面介绍几种常见的缓存级别。
缓存可以存储在客户端(操作系统或浏览器、服务端、或者是独立的缓存系统中。
CDN也可以被认为是一种缓存。
反向代理或者像Varnish这样的缓存服务可以直接保存静态的或动态的缓存内容。Web服务器也可以缓存请求直接响应客户端从而避免请求再次触达应用。
我们的数据库服务在默认的配置或者稍微针对通用场景进行优化的情况下通常包含不同级别的缓存,针对特定的使用场景进行适当的调整可以进一步提高性能。
像Memcached和Redis这种内存key-value缓存服务,通常是置于应用和数据库服务之间,因为数据存储在内存中,因此这要比将数据存储在磁盘的数据库要快的多。但是内存与磁盘相比往往受限于空间,因此类似LRU(Least Recently Used)这种缓存淘汰算法应运而生,他们将相对较少访问的"冷"数据从内存置换出来将访问频率较高的“热”数据放入内存(将内存的使用价值最大化,译者注)。
Redis还有很多其他的功能,包括:
下面是针对 数据库查询级别和 对象级别的一般缓存:
值得一提的是,我们通常要避免文件级别的缓存,因为基于文件的缓存常常难于扩展和维护。
查询级别缓存:
每当我们查询数据库的时候,将查询(比如SQL)进行hash并作为key和查询结果关联存储,这种方法会遇到 缓存过期的问题:
对象级别缓存:
对象级别缓存是将数据看做对象:
对象级别的缓存建议的使用场景:
因为内存受限于空间缓存只能存储有限的数据,因此我们需要决定在我们的应用场景中,使用何种 缓存更新策略,下面介绍几种常见的模式。
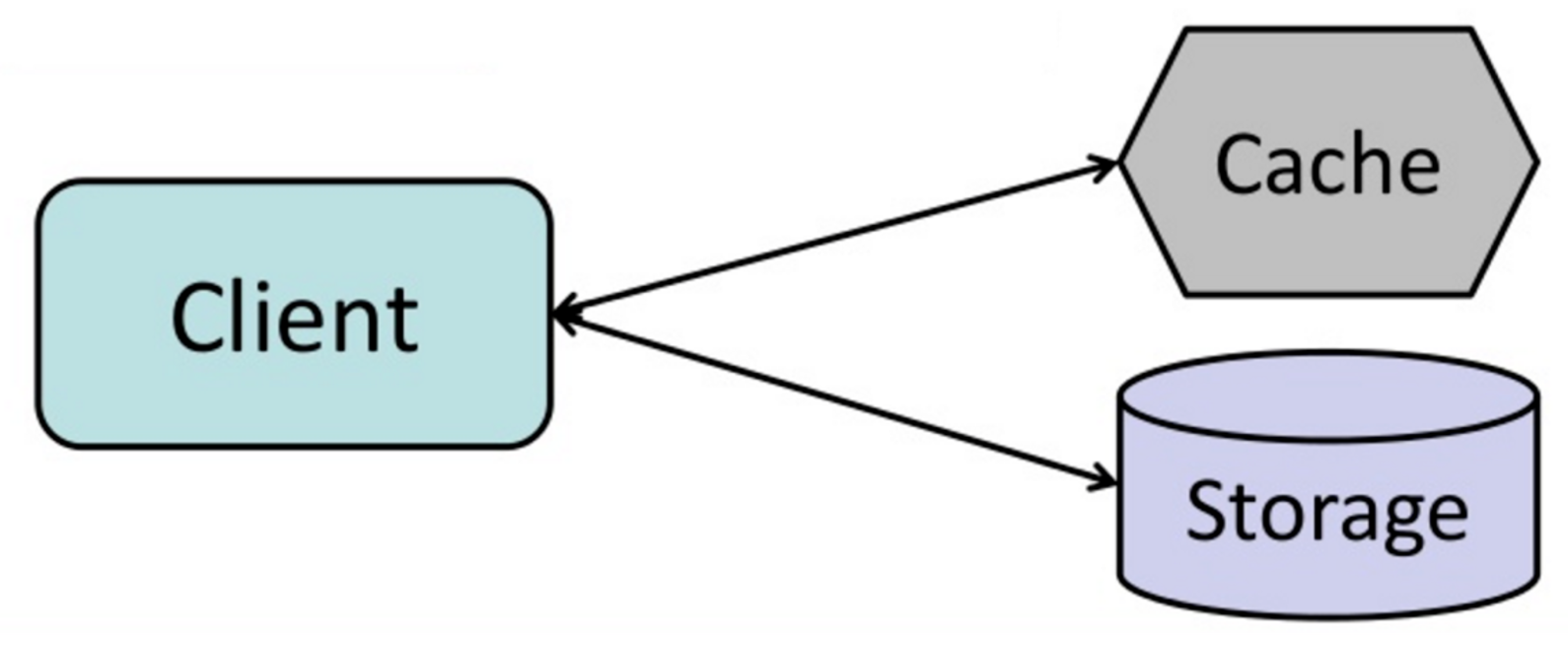
Cache-Aside模式
应用负责基于存储读写数据,缓存不直接和存储打交道,应用的行为如下:
代码示例如下:
|
|
Memcached通常被应用于这种方式,这种模式对于接下来的数据读取将非常快,Cache-Aside也叫做 延迟加载,只有需要的数据被缓存,避免不需要的数据占用缓存空间。
这种模式的缺点如下:
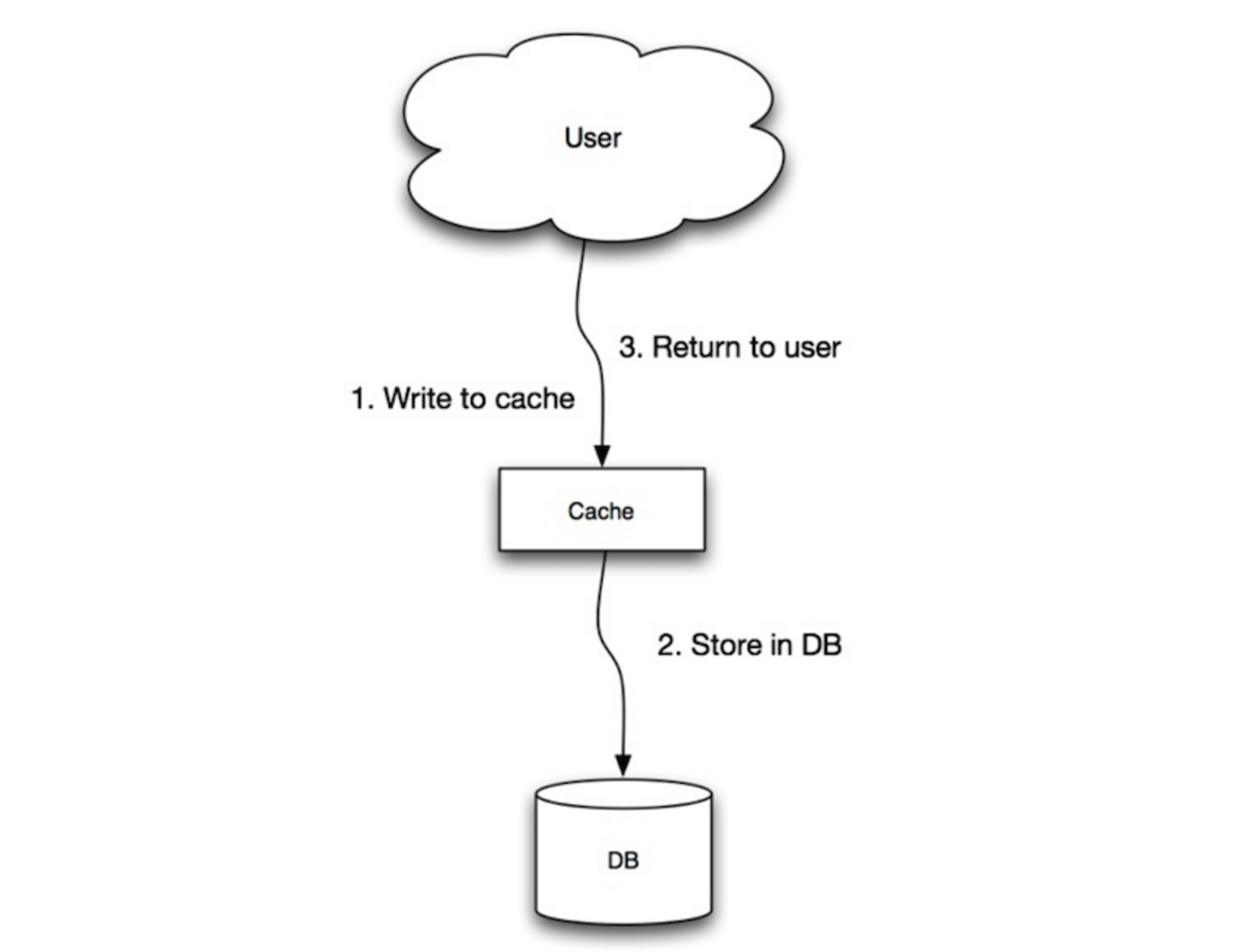
Write-Though模式
应用将缓存作为主要存储,读写都直接和缓存打交道,缓存负责基于存储进行读写:
应用代码示例:
| |
缓存代码如下:
| |
Write-Though对于所有的写操作都是比较慢的,但是对于读来说很快,用户通常需要容忍写延迟,但是不会出现脏数据。
这种模式的缺点如下:
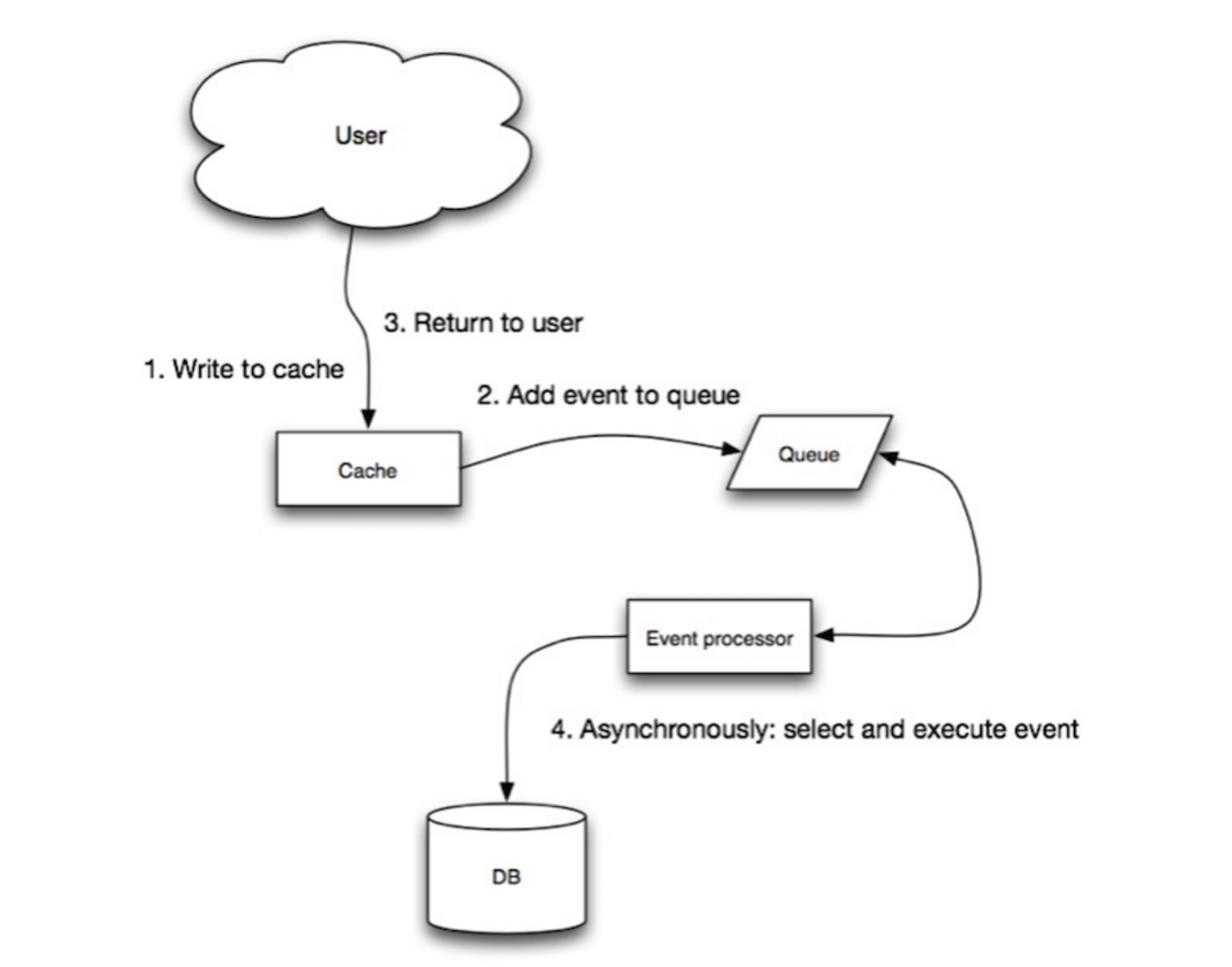
Write-Behind模式
在这种模式下,应用的行为如:
这种模式的缺点如下:
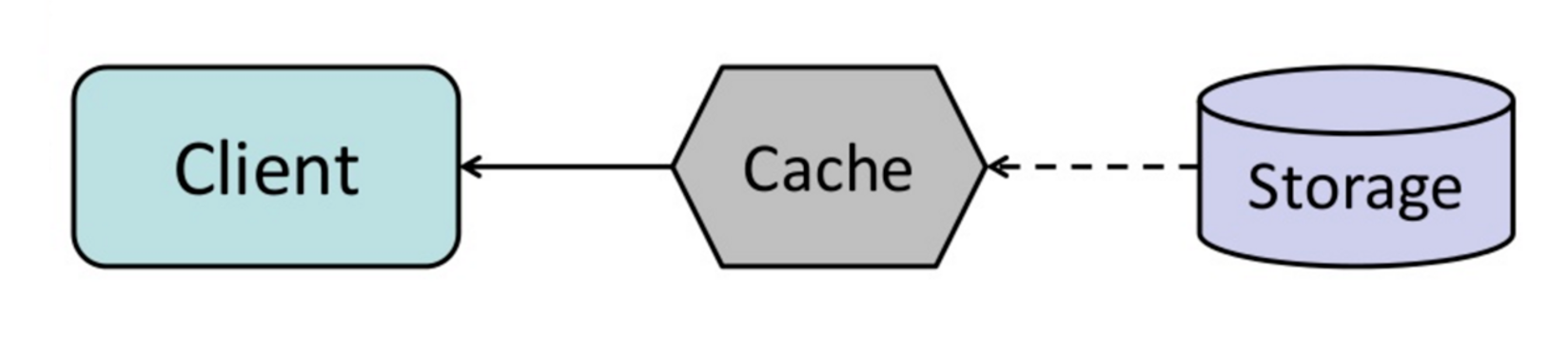
Refresh-Ahead模式
我们可以配置缓存自动在最近访问的数据过期之前更新它们,如果可以准确预测将要访问的数据,Refresh-Ahead模式可以有效地减少读写的延迟。
这种模式的缺点如下:
一种解决方案通常会带来一些问题,我们来看看引入缓存带来的问题:
注:文中翻译如有错误,请多多包涵。
另外我开公众号啦,欢迎订阅:
