安全日志系统数据网关实现
- - FreeBuf.COM | 关注黑客与极客日志分析的前期工作的是日志的收集与日志的存储. 数据的收集客户端程序有很多logstash、nxlog、filebeat等. 数据存储比较流行的就是ElasticSearch, 当数据的采集与存储阶段完成后,我们要做的是使用这些数据,ES提供数据检索功能,但这只最核心的检索API,从API到用户使用的交互界面之间,是数据检索的软件实现部分,将不同业务的数据分成不同的索引和不同的接口,或是有抽象出更高级一些的概念:流.
日志分析的前期工作的是日志的收集与日志的存储。数据的收集客户端程序有很多logstash、nxlog、filebeat等。数据存储比较流行的就是ElasticSearch, 当数据的采集与存储阶段完成后,我们要做的是使用这些数据,ES提供数据检索功能,但这只最核心的检索API,从API到用户使用的交互界面之间,是数据检索的软件实现部分,将不同业务的数据分成不同的索引和不同的接口,或是有抽象出更高级一些的概念:流。
回顾一下上篇的整体服务部署的结构。
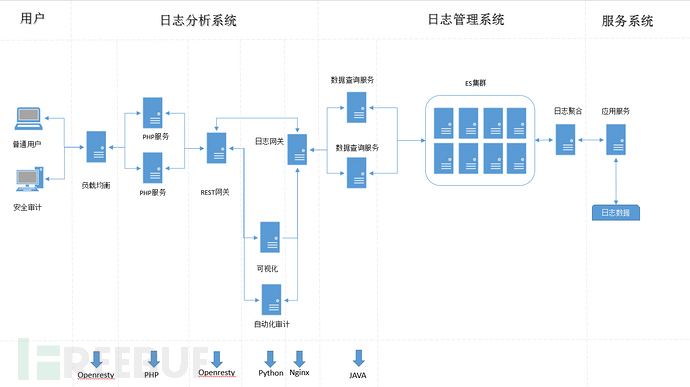
上图中REST网关的实现方案,是这次我们讨论的重点。网关左侧是数据服务的使用者,图上指的就是PHP服务,通过PHP服务来实现的界面查询,数据可视化展示。REST网关的右侧是多层的数据检索服务提供者,不同的检索数据,我们可以创建不同的服务来实现,保持彼此之间的独立。如果为了方便简单,就不需要分太多的层次,如果数据没有那么复杂。可能考虑的防异常情况越多,系统设计的可能越复杂,下面就针对不同的应用场景,介绍一下数据中心网关的实现方案。
有时我们的需求可能不复杂,就是将日志都存放ES里,然后提供一个REST API给外界使用就好,也不用任何的认证协议,传一个认证KEY就好,对一个人的安全团队来说,这种方式是最快速的,对外的接口,是直接对ES接口的按业务封装。这种情况,采用一种高抽象的语言和框架实现起来就更方便。这个就给出一人Python的实现方案。 直接用Python Django的 REST框架来实现各种日志数据的REST接口实现。
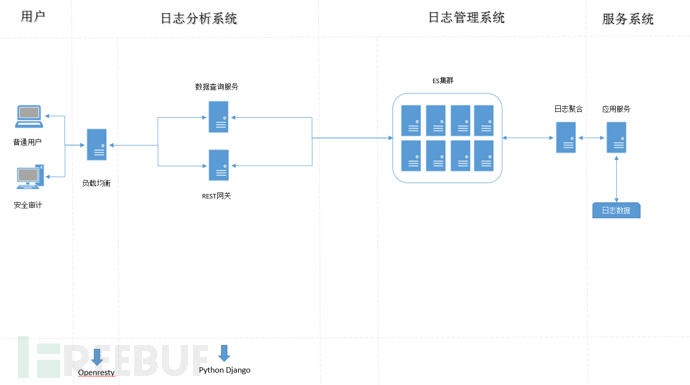
Python语言的抽象度非常的高,Django框架随处可见,Django-REST作为一个典型的Django中间件,用起来简单方便。给出一个实例工程,来说明用Python实现是多么的便捷。Django REST这个中间最主要的用处就是提供了用户请求中的JSON解析和JSON响应的类,还提供数据模型等更高级的部件,对于封装ES查询来说,基本的这些可以完成基本的工作,下面我们给出具体的代码片段。
import json
import pyes
from django.shortcuts import render
from datetime import datetime
from elasticsearch import Elasticsearch
from django.contrib.auth.models import User, Group
from bone.models import Testcase
from rest_framework import viewsets
from xwing.serializers import UserSerializer, GroupSerializer,TestcaseSerializer
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
from rest_framework.renderers import JSONRenderer
from rest_framework.parsers import JSONParser
from xwing.models import Snippet
from xwing.serializers import SnippetSerializer
es = Elasticsearch('127.0.0.1:9201')
class JSONResponse(HttpResponse):
"""
An HttpResponse that renders it's content into JSON.
"""
def __init__(self, data, **kwargs):
content = JSONRenderer().render(data)
kwargs['content_type'] = 'application/json'
super(JSONResponse, self).__init__(content, **kwargs)
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
class GroupViewSet(viewsets.ModelViewSet):
queryset = Group.objects.all()
serializer_class = GroupSerializer
class TestcaseViewSet(viewsets.ModelViewSet):
queryset = Testcase.objects.all()
serializer_class = TestcaseSerializer
@csrf_exempt
def get_phone_num(request, ver):
if request.method == 'GET':
return JSONResponse("GET_PHONE")
elif request.method == 'POST':
data = JSONParser().parse(request)
flg_identity = data.has_key('identity')
flg_token = data.has_key('token')
flg_phone = data.has_key('phone')
if not flg_token:
return JSONResponse('Token is empty!')
if not data['token'] == 'testkey123123123':
return JSONResponse('Token is invalid!')
if not flg_phone:
return JSONResponse('Phone is empty!')
phone_num = data['phone']
tmp_data = { 'query': { 'match': { 'phone': phone_num }}}
res = es.search( index='data', body = tmp_data )
ret_cnt = res['hits']['total']
return JSONResponse(ret_cnt)
python的一个抽象度很高的语言,大部分和HTTP协议,与ES查询的操作都被封装成了库,使用都只关心库的使用,集中精力实现具体的业务就好了。这个示例工程的代码不是很多,但也不能全贴上来,有些是Django框架内容,略过不贴了,给出github地址。
https://github.com/shengnoah/xwing
在上一个方案我们使用的是用Python直接与ES交互,来完成业务数据结构的方案,这种方案的好处就是写起来快,确定是后期维护新增加的数据,要自己复制管理ES的索引,如果你有非常具体的定制ES结构需求可以自己管理,如果说没有太多的精力想去进行ES数据库结构的相关管理,而且还是硬代码级别的维护修改,那就可以基于某种现成的方案,拿来注义的使用开源新产品提供的数据网关,比如说:Graylog。Graylog把日志处理流程中的操作过程抽象出了类似Stream和Input、Dashboard这种业务上的逻辑概念, 支持这些功能实现的关键是Graylog基于Java和NodeJS的Feature,这些都可以不关心,直接使用现成数据网关再做业务相关的封装就好。
上一个例子中,我们使用Python的库完成数据网关的实现, 而这个方案中,我们是基于Moonscript和Openresty的实现的网关方案,这种方案的抽象度要低,要和HTTP直接打交道,好处就是基于Openresty的网关性能要比Python高,特别是在以后,如果数据访问规模特别大时, 基于Openresty的服务,天然的性能就要好,下面我们给出基于Openresty+Moonscript的代码实现:
在ES存储中是没有什么Input和Stream的概念,这些都是 Graylog这种服务抽象出来的,如果我们想使用这种服务,就要基于Graylog提供的接口,实现和自己业务相关的SDK。
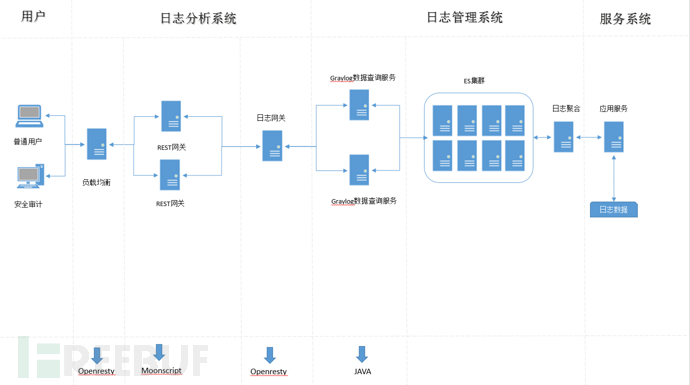
因为使用了开源中间件软件,层次结构上就多出一层,复杂度高了,下面我们给出了基于Graylog的SDK。
class App extends lapis.Application
"/testcase": =>
--准备对应REST的输入参数,如果相应该有的项目没有设定会输出NG原因。
param_data= {
fields:'username',
limit:3,
query:'*',
from: '2017-01-05 00:00:00',
to:'2017-01-06 00:00:00',
filter:'streams'..':'..'673b1666ca624a6231a460fa'
}
--进行鉴权信息设定
url = GMoonSDK\auth 'supervisor', 'password', '127.0.0.1', '12600'
--调用对应'TYPE'相对应的REST服务,返回结果。
ret = GMoonSDK\dealStream 's_ua', param_data
ret
这样一来,上面用的PyES这次,用Moonscript自己实现了一次,而对REST请求的解析和响应靠的是Moonscript的Lapis框架,具体位置看下面的代码。
https://github.com/shengnoah/fortress
有人习惯命令行的方式来对日志文件进行查询,不想通过WEB页面进行查询也可以实现,不想自己实现SDK也可以,用Python版的Graylog的SDK也可以实现。
代码如下:
import sys
import json
import time
import logging
import optparse
import datetime
import string
from pygraylog.graylogapi import GraylogAPI
import base64
import requests
graylog_server_auth = {
"url" : "http://127.0.0.1:12900",
"username" : "graylog",
"password" : "graylogpassword"
}
FIELDS_LIST = {
"IPS" : ",src_ip,src_ip_geolocation,src_port,type,target_ip,target_ip_geolocation,target_port,time,username", #IPS Fileds
}
STREAMS_LIST = {
"IPS" : "abc09bfeb62567184383123", #IPS
}
def search_ips_stream(stream_name, info_map):
api = GraylogAPI(graylog_server_auth['url'],
graylog_server_auth['username'],
graylog_server_auth['password'])
filter_values = "streams:" + STREAMS_LIST[stream_name]
fileds_values = FIELDS_LIST[stream_name]
ret = api.search.universal.absolute.get(fields = fileds_values,
query=info_map["query"],
from_ = info_map["from"],
to = info_map["to"],
filter=filter_values,
limit=info_map["limit"])
return ret
def opts():
usage = "usage: %prog -q ip -f fromdate -t todate -l limit -n username"
parser = optparse.OptionParser(usage=usage)
parser.add_option("-q", "--query",
action="append", dest='query', nargs=1, type='string',
help="query")
parser.add_option("-f", "--fromdate",
action="append", dest='fromdate', nargs=1, type='string',
help="fromdate.")
parser.add_option("-t", "--todate",
action="append", dest='todate', nargs=1, type='string',
help="todate.")
parser.add_option("-l", "--limit",
action="append", dest='limit', nargs=1, type='string',
help="limit.")
parser.add_option("-n", "--filename",
action="append", dest='filename', nargs=1, type='string',
help="filename.")
parser.add_option("--debug",
action="store_const", dest='debug',
help="enable debug log output", default=False, const=True)
options, args = parser.parse_args()
if len(args) < 1:
parser.error('You need to give "subscribe" or "publish" as <action>.')
if args[0] not in ['subscribe', 'publish', 'sendfile']:
parser.error('You need to give "subscribe" or "publish" as <action>.')
if options.debug:
logging.basicConfig(level=logging.DEBUG)
else:
logging.basicConfig(level=logging.CRITICAL)
action = args[0]
data = None
if action == 'publish':
data = ' '.join(args[1:])
elif action == 'sendfile':
data = ' '.join(args[1:])
return options, action, data
def main(opts, action, pubdata=None):
query = options.query[0]
fromdate = options.fromdate[0]
todate = options.todate[0]
limit = options.limit[0]
filename = options.filename[0]
info_map = {}
info_map["type"] = "vpn"
info_map["from"] = fromdate
info_map["to"] = todate
info_map["query"] = query
info_map["limit"] = limit
info_map["filename"] = filename
ret = search_ips_stream("IPS",info_map)
receive_data = json.loads(ret)
ret_filename = './data/' + 'total' + '.csv'
out_filename = './data/' + filename + '.csv'
ret_object = open(ret_filename,'a')
total = receive_data['total_results']
if total > 0:
uname = ""
for item in receive_data['messages']:
username = str(item['message']['username'])
uname = uname + username + " "
meta_data = "YES"+ "," + fromdate + "," + todate + "," +filename + "," + uname + "\n"
ret_object.write(meta_data)
else:
meta_info = "NO"+ "," + fromdate + "," + todate + "," + filename + "\n"
ret_object.write(meta_info)
ret_object.close()
output_object=open(out_filename,'w')
for item in receive_data['messages']:
username = str(item['message']['username'])
estime=""
timestamp = str(item['message']['timestamp'])
meta_info = username + ',' + timestamp + ',' + '\n'
output_object.write(meta_info)
output_object.close()
if __name__ == '__main__':
options, action, data = opts()
try:
sys.exit(main(options, action, pubdata=data))
except KeyboardInterrupt:
sys.exit(0)
这样我们就创建了一个命令行方式的查询工具,可以实现多条和业务相关的命令集,用这些命令完成复杂的自动化检索任务。
项目代码的位置在: https://github.com/shengnoah/graylog-console
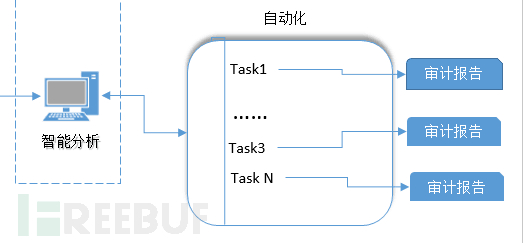
命令行的意义就在于构建这部分的功能。
日志数据网关是我们对收集来的的日志数据操作的一个核心部件,相当于一个基于REST API的日志数据驱动引擎,我们会围绕一套简单的定制SDK和命令行工具,发展出更多的功能,之后我们就会基于这套数据网关来实现更高级一些的数据审计任务,可视化任务,自动分析任务。