Spark2.x学习笔记:11、RDD依赖关系与stage划分 - CSDN博客
- -11、 RDD依赖关系与stage划分. Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系. 针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency).
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系。
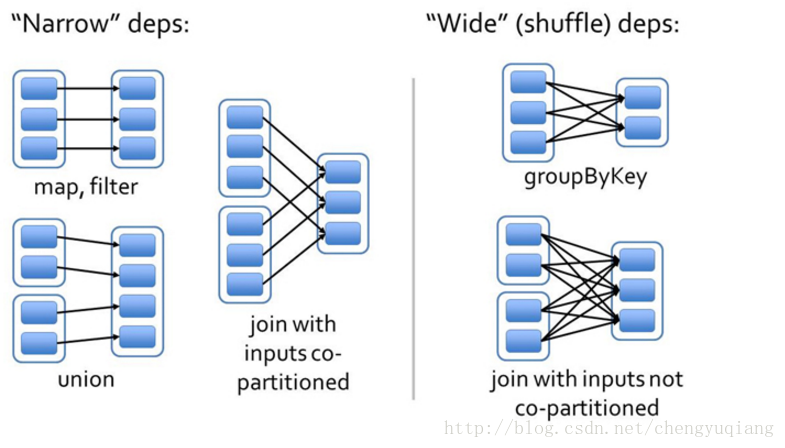
针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency)。
(1)窄依赖
窄依赖是指 1个父RDD分区对应1个子RDD的分区。换句话说,一个父RDD的分区对应于一个子RDD的分区,或者多个父RDD的分区对应于一个子RDD的分区。
所以窄依赖又可以分为两种情况,
(2)宽依赖
宽依赖是指 1个父RDD分区对应多个子RDD分区。宽依赖又分为两种情况
总结: 如果父RDD分区对应1个子RDD的分区就是窄依赖,否则就是宽依赖。
(1) 窄依赖(narrow dependencies)可以支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败恢复也更有效,因为它只需要重新计算丢失的parent partition即可
(2)宽依赖(shuffle dependencies) 则需要所有的父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能开始计算,可能还需要调用类似MapReduce之类的操作进行跨节点传递。从失败恢复的角度看,shuffle dependencies 牵涉RDD各级的多个parent partition。
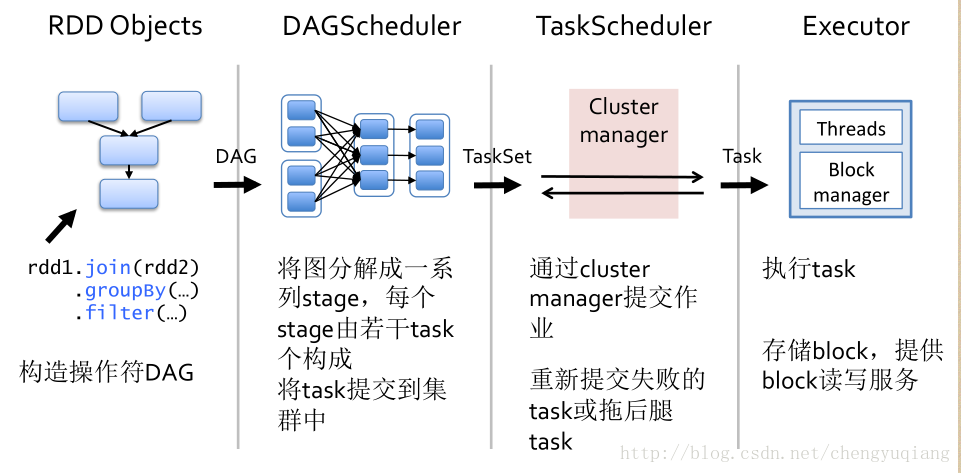
RDD之间的依赖关系就形成了DAG(有向无环图)
在Spark作业调度系统中,调度的前提是判断多个作业任务的依赖关系,这些作业任务之间可能存在因果的依赖关系,也就是说有些任务必须先获得执行,然后相关的依赖任务才能执行,但是任务之间显然不应出现任何直接或间接的循环依赖关系,所以本质上这种关系适合用DAG表示
由于shuffle依赖必须等RDD的父RDD分区数据全部可读之后才能开始计算,因此spark的设计是让父 RDD将结果写在本地,完全写完之后,通知后面的RDD。后面的RDD则首先去读之前RDD的本地数据作为输入,然后进行运算。
由于上述特性,将shuffle依赖就必须分为两个阶段(stage)去做:
为什么要写在本地?
后面的RDD多个分区都要去读这个信息,如果放到内存,如果出现数据丢失,后面的所有步骤全部不能进行,违背了之前所说的需要父RDD分区数据全部ready的原则。
同一个stage里面的task是可以并发执行的,下一个stage要等前一个stage ready(和mapreduce的reduce需要等map过程ready 一脉相承)。
Spark 将任务以 shuffle 依赖(宽依赖)为边界打散,划分多个 Stage. 最后的结果阶段叫做 ResultStage, 其它阶段叫 ShuffleMapStage, 从后往前推导,依将计算。
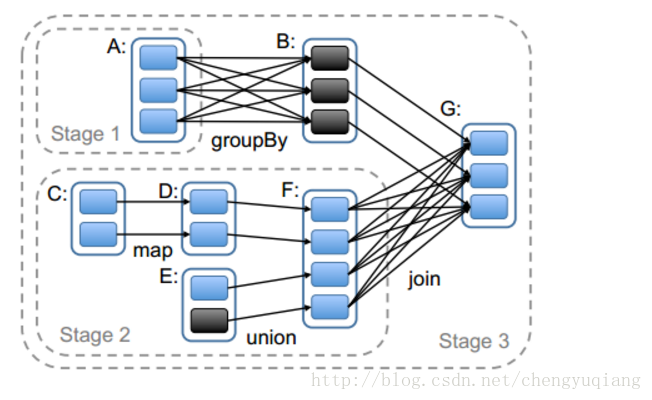
1.从后往前推理,遇到宽依赖就断开,遇到窄依赖就把当前RDD加入到该Stage
2.每个Stage里面Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的。
3.最后一个Stage里面的任务类型是ResultTask,前面其他所有的Stage的任务类型是ShuffleMapTask。
4.代表当前Stage的算子一定是该Stage的最后一个计算步骤
表面上看是数据在流动,实质上是算子在流动。
(1)数据不动代码动
(2)在一个Stage内部算子为何会流动(Pipeline)?首先是算子合并,也就是所谓的函数式编程的执行的时候最终进行函数的展开从而把一个Stage内部的多个算子合并成为一个大算子(其内部包含了当前Stage中所有算子对数据的计算逻辑);其次,是由于Transformation操作的Lazy特性!在具体算子交给集群的Executor计算之前首先会通过Spark Framework(DAGScheduler)进行算子的优化(基于数据本地性的Pipeline)。