每秒百万级流式日志处理架构的开发运维调优笔记 | Cloud
- -荣幸之至,我们团队在实时日志分析、搜索项目中曾经应对过百万级的挑战,在这方面有长足的进步. 本文以笔记和问答的形式记录了我们曾经遇到过的实际问题及解决方案,而非小白式的大数据科普文章. 相信只有真正做过每秒近百万以上的实时日志处理业务,遇到过棘手问题,才能深刻感受我们当时越不过高坎的窘境与解决问题后的狂喜.
荣幸之至,我们团队在实时日志分析、搜索项目中曾经应对过百万级的挑战,在这方面有长足的进步。本文以笔记和问答的形式记录了我们曾经遇到过的实际问题及解决方案,而非小白式的大数据科普文章。相信只有真正做过每秒近百万以上的实时日志处理业务,遇到过棘手问题,才能深刻感受我们当时越不过高坎的窘境与解决问题后的狂喜。
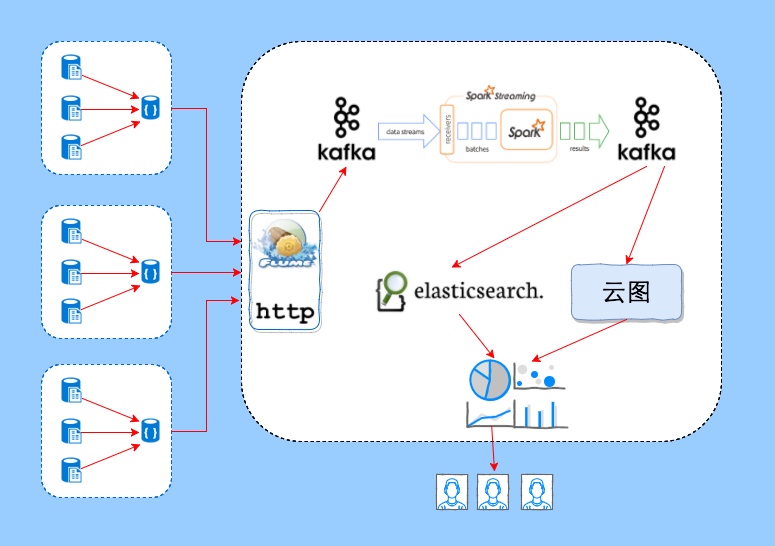
我们首先对架构做一个简单的介绍,在产生日志的服务器上通过agent(rsyslog或其它工具)把日志发送到数据平台的接收接口(nginx或flume等架设的http或tcp接口),通过kafka队列,经过Spark的ETL输出统一格式的日志到Kafka,进而使用Elasticsearch索引全量数据提供全文搜索服务,同时数据存储到我们内部的云图系统提供海量统计分析服务。最终用户打开我们定制开发的UI,即点即用,完成业务分析需求。
架构不复杂,但一旦涉及海量和实时,必定充满挑战。我们对数据平台做了无数次优化,实则在不停得迭代回答以下几个问题:
如何做到日志源将日志尽可能均匀打到日志接收节点,实现负载均衡?
如何做到不丢日志?
如何做到处理能力每秒近百万?
如何降低搜索和统计的延迟?
如何用更少的成本实现以上目标?
我们计划通过一系列的文章介绍我们的思考与解决方案,本文后面的内容是系列的开篇,是架构中主要开源技术的开发、运维、调优的笔记。
问题1: 通配日志文件名?从最新位置开始读?
v8.15.0 之前不支持imfile 通配,不支持从最新位置开始读; centos 6.x 上默认安装的是 v5.8.10
问题2: rsyslog 直接写kafka ?
v8.7.0 之前不支持 omkafka, 不能直接写kafka; omkafka 底层使用librdkafka库(kafka c api client), 发送队列满后会丢弃数据,将导致丢数据。
问题3: 不会配置rsyslog ?
v5.8.10 配置模版(从文件读日志发送到flume):
http://git.letv.cn/oi/configs/blob/master/log_agent/rsyslog/oi_rsyslog_agent.conf.template
问题4: 使用omfwd tcp 发送数据时,如何实现 rsyslog 以load balance的方式向多个接收端发送日志?
如果发送端 rsyslog节点个数较多(发送端个数数量级大于接收端),可以在发送端与接收端之间部署LVS或haproxy 等 load balance工具。
如果发送端 rsyslog节点个数很少,如 rsyslog 发送端有4个,接收端有5个,由于 rsyslog 与接收端建立长链接,将导致多个发送端将数据发送到同一个接收端上。此时常见的有2种方案:
(1)在有 lvs 或 haproxy 的基础上,配置omfwd的 rebindinterval 参数,每次发送一定量的数据后与接收端重新建立链接。代价是此方案不是并行的向多个接收端发送数据,还需要关注一下lvs/haproxy的负载均衡策略,防止单台接收端上建立过多链接。rsyslog v7.x之前,这个参数的名称是:\$ActionSendTCPRebindIntervalinteger(或者 \$ActionSendUDPRebindIntervalinteger。
(2)用mmsequence生成随机数字,然后按照这个数字来走不同的omfwd。好处是rsyslog可以并行得向多个接收端发送数据。代价是需要在 rsyslog 配置里写很长的action列表,配置有些繁琐。
在此感谢rsyslog大神@argv提供rsyslog负载均衡的思路。
source(syslogtcp/avro) -> channel(mem) -> sink(kafka/avro)
transaction[begin, commit], putlist, takelist
transactionCapacity, batch_size 的意义以及两者关系
source:开启事务 -> 存数据 -> 放入私有的putlist->提交事务(消息进入channel,清空事务的takelist,putlist)
sink:开启事务 -> 从channel取数据 -> 放入私有的takelist->提交事务(消息进入channel,清空事务的takelist,putlist)
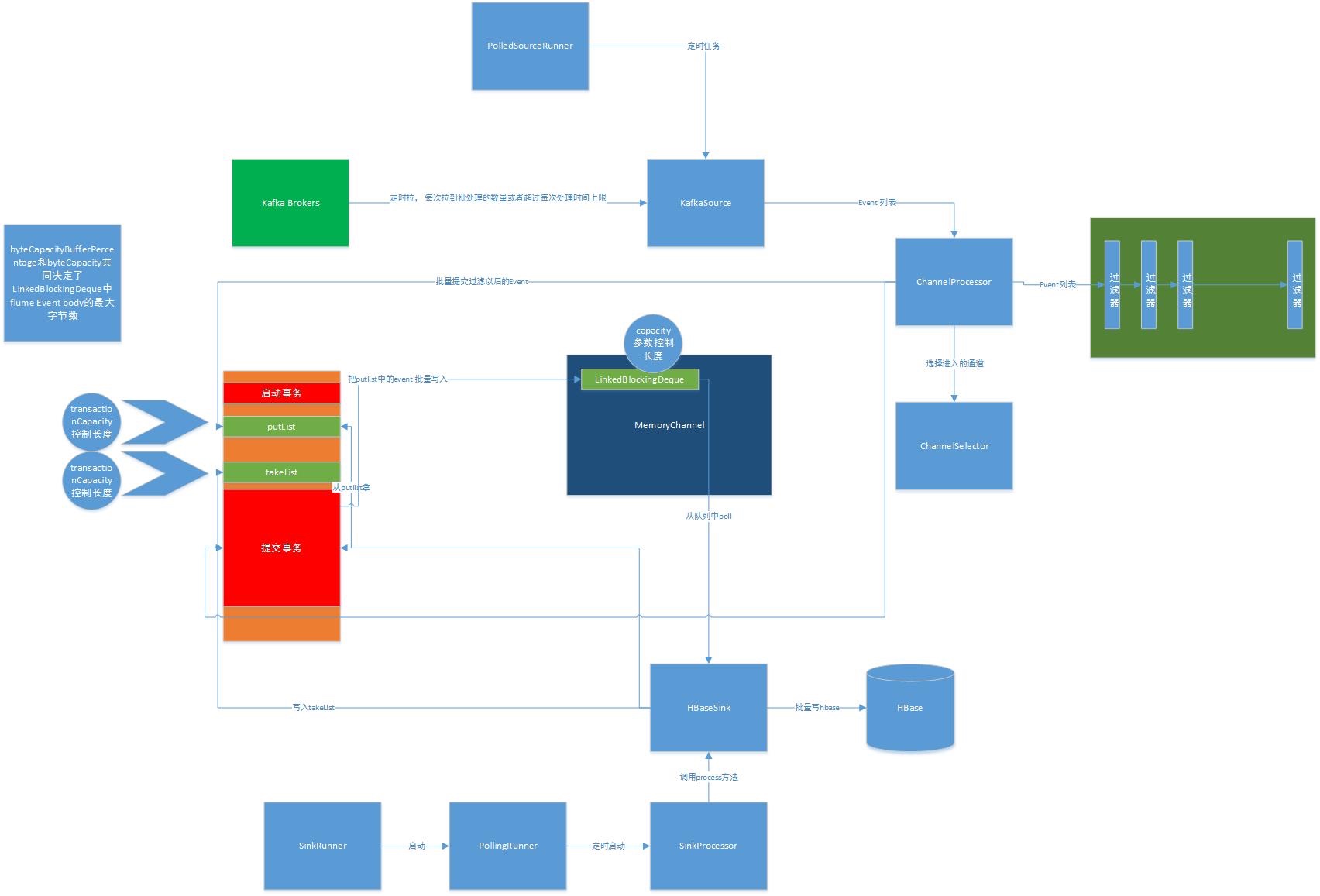
注:上图非原创,原图地址: http://www.cnblogs.com/dongqingswt/p/5070776.html
AvroSink在消费的事务中通过rpc调用对应的AvroSource的appendBatch方法,开启并提交了一次AvroSource的put事务,
AvroSource的生产拥堵(就是avro source 往后面的channel put 太慢,可能是source里配置了几个非常消耗CPU资源和时间的interceptor造成的)也会减慢对应的AvroSink的消费速度
AbstractRpcSink
AbstractRpcSink 主要源码:
|
|
不同类型的source事务的提交机制不同,例如:kafka source是通过batch size和batch duration共同控制,kafka sink只通过batch size控制,而SyslogTcpSource是每写入一条消息就会开启并提交一次事务
SyslogTcpSource 主要源码:
|
|
KafkaSink 主要源码:
|
|
在flume1.7中kafka sink会在一个事务提交前强制发送kafka proudcer中缓存的消息,意味着值大于sink batch size(默认为100)的kafka.producer.batchsize将不生效
|
|
理解了上面的原理后,我们来提出下面几个问题:
使用memory channel时,重启将丢失channel中未处理完的数据。
检查是否在source中配置了interceptors, 某些interceptor性能很差,如 regex_extractor。
flume 1.6.0 的 kafka sink 的 kafka api client 不兼容新版本的kafka, 需要自己编译 https://github.com/apache/flumetrunk 分支的最新版 kafka sink , 引入 flume 1.6.0 版本中。
以双层 flume 架构为例,数据流是:
rsyslog ===>
Flume_01 (syslogtcp source -> memory channel -> avro sink ) ===>
Flume_02 (avro source -> memory channel -> kafka sink) ===> Kafka
举个例子,如果第一层syslogtcp source 的tcp队列recv queue阻塞,但是后面的 channel size增长很慢,说明是syslogtcp source接收和处理太慢;如果第一层flume的channel size持续增长,说明Avro sink比较慢;如果第二层flume的channel size持续增长,说明kafka sink太慢。
这里有一个普适性规律:
(a) 如果是source慢,可以考虑去掉source后面的interceptor;如果是往channel put太慢,可以考虑增加batch size,channel transaction capicity size。
(b) 如果是sink慢,可以考虑增加sink的个数,增加并发度;增加sink发送的batch size;对于avro sink -> avro source 这样sink 通过rpc调用下一级source appendBatch() 的数据流,应该保证下一级source不阻塞。
(a) 尽可能使数据来源均匀打量到后段多个flume上
(b) 增加 flume 实例数
(c) 单 flume 实例增加 sink 个数 (sink 个数与线程个数相关)
(d) 少用 regex_extractor 等消耗性能的interceptor
把flume 1.7.0 引入的 TaildirSource 加入到 flume 1.6.0 中
参考: http://lxw1234.com/archives/2015/10/524.htm
我们下载了flume 1.7.0 (还未正式发布)的源码,编译后,用里面的一些jar 包替换了flume 1.6.0 的 jar包,包括:kafka-sink , taildir-source; 并且增加了一些常用的interceptor, 如:。
我们在互联网上找到的一些不错的 flume 插件在这里列出:
https://github.com/garyelephant/awesome-flume-plugins
参考static inteceptor 作为样板开发:
https://github.com/apache/flume/blob/trunk/flume-ng-core/src/main/java/org/apache/flume/interceptor/StaticInterceptor.java
下面还有几篇介绍自定义inteceptor 的文章:
https://medium.com/@bkvarda/building-a-custom-flume-interceptor-8c7a55070038
https://thisdataguy.com/2014/02/07/how-to-build-a-full-flume-interceptor-by-a-non-java-developer/
https://hadoopi.wordpress.com/2014/06/11/flume-getting-started-with-interceptors/
需求:多用户多种日志收集,高性能
rsyslog/avro source -> file channel -> kafka sink
我们的解决方案:
(1)apptag interceptor
(2)修复 kafka sink 向未创建 topic produce message时的严重性能bug
|
|
可能是 kafka api 版本问题
参见streamingetl的代码和配置。
producer端:
acks = “all”
retries = “2147483647” (Long.MAX_VALUE)
= Long.MAX_VALUE
consumer端:
Disable auto.offset.commit
Commit offsets only after the messages are processed:Spark Direct Kafka Stream, 自己控制offset 的commit
topic设置:
replication factor >= 3
至少出现一次 -> 数据可能重复
增大 linger.ms, 默认值: 0
增大 batch.size, 默认值:16384
max.in.flight.requests.per.connection = 5
compression.type = snappy,默认不压缩
多 producer 实例, 提高并发
kafka 0.9.0.0 引入的new consumer 还处于测试阶段,暂不考虑。
num.consumer.fetchers = 1
fetch.message.max.bytes = 2 10241024
多个 consumer 实例
kafka 性能一般受限于 kafka broker 的带宽的大小,CPU, Disk IO 极少成为瓶颈;使用 snappy 等压缩方式压缩message有助于减少broker 带宽压力,一般能压缩到原来的5/6。
Kafka 不能像 Elasticsearch 一样能自动做数据的 rebalance 和 replicas recovery。如果某个borker 异常下线,将导致部分topic的partition副本数不够;扩容节点时,新加入的节点上不会自动分配topic 的parition,处于空闲状态。综上,在扩容,节点异常下线后,缩容前,都应该做数据的rebalance。可以参考官方的具体操作 Expanding Your Cluster, 更方便的是直接使用 Kafka Manager中的”Generate Partition Assignments”,”Reassign Partitions”功能。
(a) pyspark executor 进程模型(jvm fork出 python进程):根据partiton数量生成python 多个进程
(b). virtual memory exceeded error : fork 出了很多 python进程,每个python 进程占用 400M + virtual memory
(c) kafka-python package 向 kafka 0.9 写数据存在未知bug 导致 kafka 集群不可用(invalid message size)
(d) 处理同样量级的数据,需要更多资源(导致某些节点负载过高,卡住这些节点上的其它spark job)
(e) task processing time 极度不均衡导致处理能力下降(单个task processing time 远大于平均)
(f) 无法实现广播变量(spark 官方doc的例子可能是假的)
结论:大规模 spark streaming,输出是 kafka 的不要使用 python 作为开发语言。
用广播变量(broadcast variable),单个executor (同一个jvm 程序)的不同task 可以复用同一个kafka producer。
影响 spark 程序并行度的两个重要参数:(1) job partition 个数 (2) concurrent job(spark.streaming.concurrentJobs) 个数。常见的是通过repartition可以调节partition个数,要做好repartition耗时与并行度之间的平衡。默认情况下concurrentJobs=1, 一个batch只能执行一个job。concurrentJobs=2时,如果下一个batch已经开始,上一个batch还没执行完,就会出现2个active job并行执行。在这种情况下,只要一个batch的job的执行时间不超过2个batch的duration,就不会出现batch scheduling delay。即,假设 concurrentJobs=n, 一个job的实际执行时间为t, 一个batch的duration设置的是d, 只要 t < n * d 就不会出现scheduling delay。
例如,对于kafka direct stream,kafka topic partition 个数在实现上是映射为相同的 spark job partition个数, 可以通过增加数据来源kafka topic partition 个数来增加spark job的 partition个数.
spark streaming的stopGracefully策略允许处理完receiver已收到但还未处理的数据后,再停止application。
spark streaming的checkpoint 可以做到至少处理一次,但会对spark streaming有一定的性能损耗。
kafkaDirectStream 可以实现先处理完数据,再更新offset,也可以保证至少处理一次,在这种场景下不需要spark streaming 的 checkpoint 做保证。
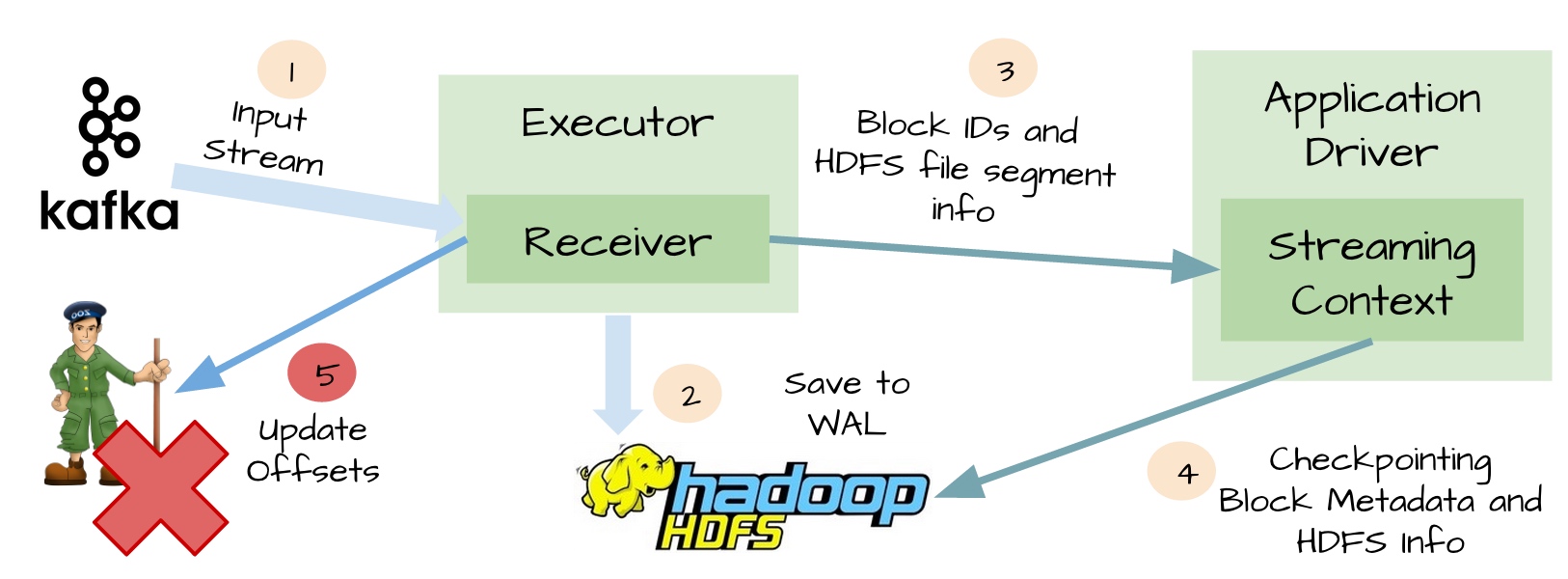
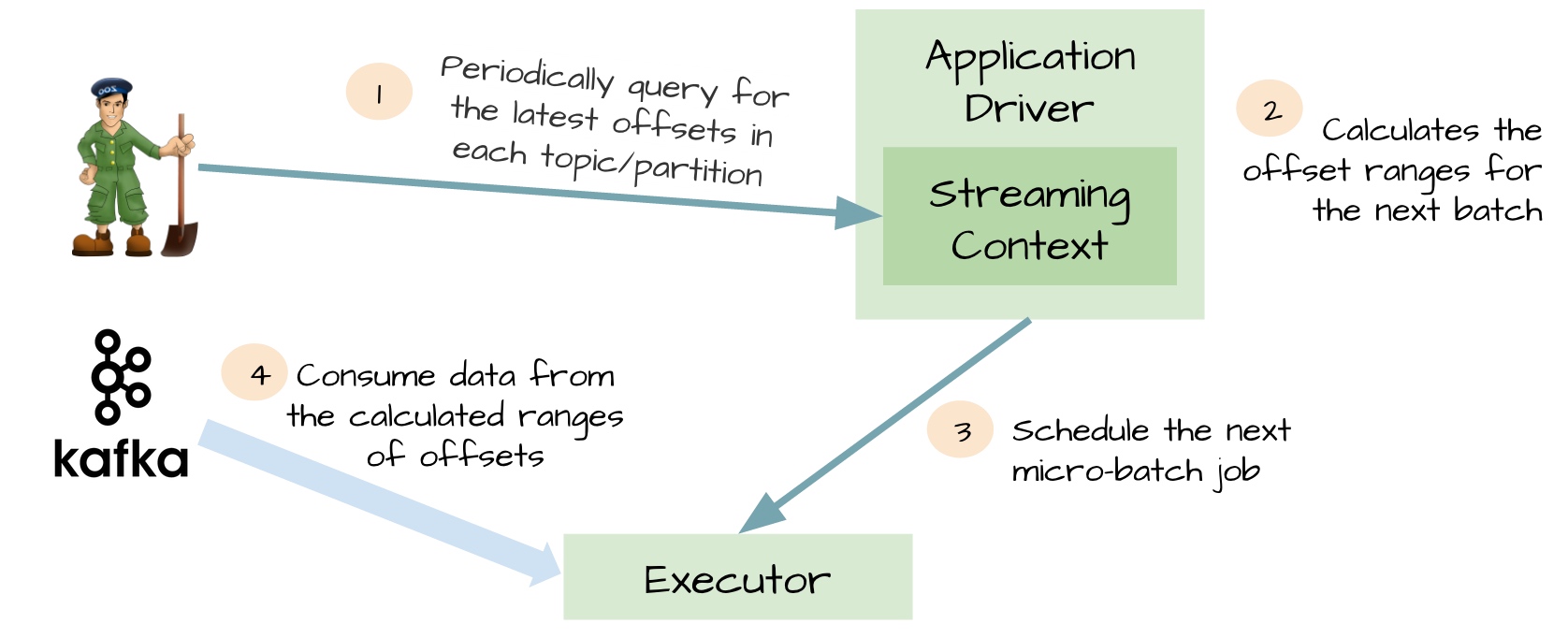
采用kafkaStream的情况下如果接收的数据没处理完会出现重启spark job丢失数据的情况,结合stopGracefully和checkpoint机制才能保证数据不丢失
采用kafkaDirectStream需要自己维护offset,优点是不需要stopGracefully和checkpoint就能保证数据不丢失
(a) mapPartition vs map
http://lxw1234.com/archives/2015/07/348.htm
https://martin.atlassian.net/wiki/pages/viewpage.action?pageId=67043332
进入spark 监控界面,查看Jobs里的各个stages,确认是普遍都慢还是个别stages耗时较长;
同时确认是每个executor上的task耗时长,还是个别executor上执行的task耗时长。如果是个别executor的task执行时间较长,有可能是这个executor所在的节点CPU耗尽或负载较大。
如下图,有2个executor,其中一个执行task耗时明显比另外一个时间长
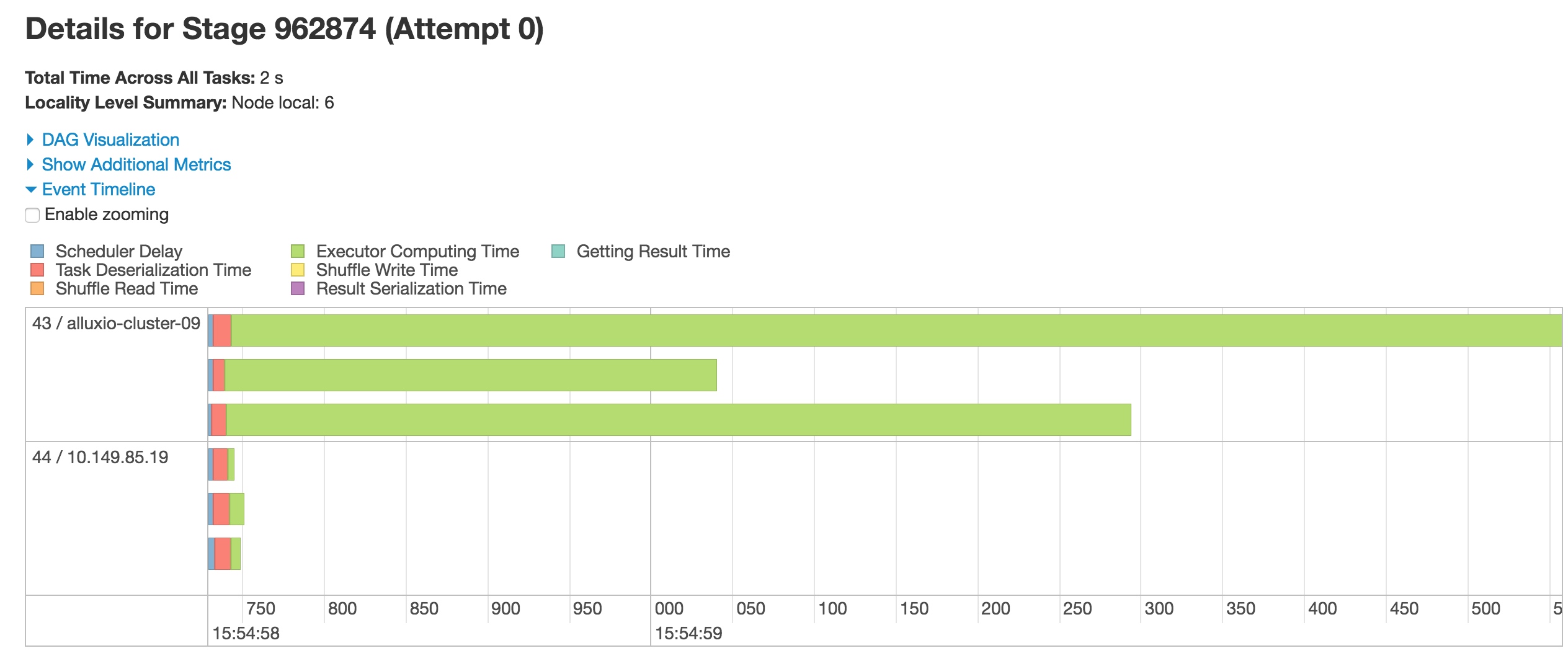
如果在executors监控页面中也看到某个executor的task time明显长于其它executor,说明在此executor上,可能有很多stages的task 执行时间都过长。
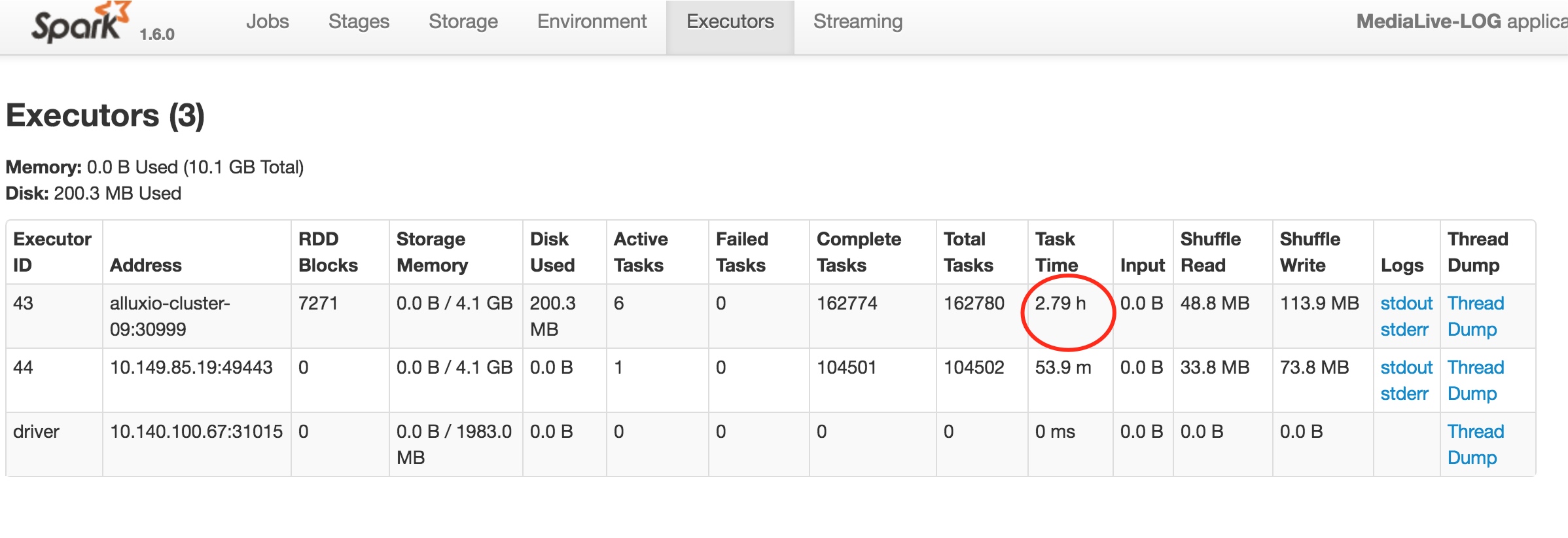
问题1: 如何加快 recovery 速度?
问题2: 集群 recovery 时数据不能写入?
从 _cat/pending_tasksapi 查看es待执行的任务看到,因为recovery task 的 priority 是urgent, 所以会阻塞其它task,如:create index 时的 put mapping task(priority 是 high), put mapping 失败,导致对应index的数据写入失败。
|
|
你可以在es日志中看到大量的如下put mapping 失败的信息:
|
|
对 es 执行 task 的优先级定义、执行顺序、并行个数感到好奇!recovery 的时候,观察到集群负载并不高,但是 index/search 很慢。
另外还有2个人在elasticsearch google group 上 询问recovery/index/search priority的,但是没有人回复:
https://groups.google.com/d/msg/elasticsearch/2XQuTnrtuVI/xQ7CuL0x5HkJ
https://groups.google.com/d/msg/elasticsearch/bEX1XngiIXg/p5YDLWnVrJEJ
hangout, flume 没有反压机制,sink发不出去的时候,source会继续接收数据,直到channel满,OOM。
(a) translog 设置的太大, index settings 里面:index.translog.flush_threshold_size: “200mb”的意思是index的每个shard最大translog buffer size,可能到达这个size后才flush,如果这个值设置的很大(我们以前误以为这个值越大越好,所以设置为10g),在flush会占用过多内存。
(b) indexing buffer 设置的太大.
(c) 其它原因待整理.
ss -n | grep 618 | sort -k2 -n -r | head
strace -f -p 13323
strace -f -c -p 13323
lsof -p 13323
lsof -i:618
sar -q / sar -n DEV
iostat -dtx 5
大部分大数据相关的开源软件如hadoop, spark, kafka, flume 等都是基于JVM的程序,它们都可以通过配置开放JMX端口,查看到 jvm 程序的详细运行时信息(内存,GC,线程,对象…)。
开源软件很优秀,也有诸多性能的问题和bug。
解决性能问题不能只靠猜和试 - 尝试做好监控和阅读源码。
性能调优分几个层级:硬件级别,OS 级别,程序代码级别,架构级别;请认准特定环境下投入产出比最大的层级进行调优。
系统资源瓶颈就是4种资源的瓶颈: CPU (占用率), Memory(占用率), Disk(剩余空间, IO速度, IO利用率), Network(网络RTT时间,网卡速率上限)。
本文由乐视云计算OI数据平台 @高英举,@王捷共同撰写。
References: