一、概述
1.DPI(Deep packet inspection,深度报文解析)
所谓“深度”是和普通的报文分析层次相比较而言的,“普通报文检测”仅分析IP包4 层以下的内容,包括源地址、目的地址、源端口、目的端口以及协议类型,而DPI 除了对前面的层次分析外,还增加了应用层分析,识别各种应用及其内容,主要实现一下功能:
1)应用分析——网络流量构成分析、性能分析、流向分析等;
2)用户分析——用户群区分、行为分析、终端分析、趋势分析等;
3)网元分析——根据区域属性(市、区、街道等)、基站负载情况进行分析等;
4)流量管控——P2P限速、保证QoS、带宽保障、网络资源优化等;
5)安全保障——DDoS攻击、数据广播风暴、防范恶意病毒攻击等。
2.网络应用的大致分类
现在的上的应用不计其数,但大众常用的网络应用可以进行穷举。
据我的了解应用识别做的最好的就是华为,号称能识别4000种应用。协议分析是很多防火墙公司(华为、网神、天融信、网康等)的基础模块,也是很重要的模块,支撑着其他的功能模块的实现,精准的应用识别,大大提高产品的性能和可靠性。像我现在在做的基于网络流量特征识别恶意软件的建模,精准的,大量的协议识别也是很重要的一环。公司出口的流量剔除掉常用应用的网络流量,剩下的流量占比会很少,更好的进行恶意软件的分析,报警。
根据我的经验将现有常用的应用根据作用进行分类:
ps:根据个人对应用的理解进行应用分类,大家有什么好的建议欢迎留言提议
1、电子邮件类
2、视频类
3、游戏类
4、办公OA类
5、软件更新类
6、金融类(银行、支付宝)
7、股票类
8、社交通讯类(IM软件)
9、Web浏览(借助url可能会更好的识别)
10、下载工具类(网盘、P2P下载、BT类相关)
P2P下载是很蛋疼的硬骨头!
P2P下载相关:迅雷、Flashget-2.4/3.4、EasyMule-1.1.11、QQDownload、Vagaa-2.6.7.1、Baidu下吧-4.0.0.1
BT类相关:BitComet/BitTorrent、gnutella、KAZAA、directconnect、ARES、SOUL、WINMX、APPLE、DC、MUTE、XDCC、WASTE
3.传统的协议识别
基于端口的协议识别
网络中多种应用层协议可以同时运行在同一台计算机的同一个 IP 地址上。由于 IP 地址与网络应用程序的关系是一对多的关系,所以主机需要通过端口号来区分不同的网络服务。
对于端口号的分配,有两种基本的方式:
1)全局分配,即由一个公认的中央机构(LANA)统一进行分配。虽然这样容易确定应用程序和端口的对应关系,但不能适应大量且迅速变化的端口使用环境;
2)本地分配,即动态分配。当某应用程序进程需要访问网络时,主机操作系统临时为该进程分配一个本地唯一的端口号。但本地分配方式使得其它主机无法获知分配情况,无法建立通信。
Internet 同时采用上述两种分配方式,将端口分成两部分:
1)保留端口,以全局方式(IANA)进行分配。这样每一个标准的服务器应用程序都拥有一个或多个全局的公认端口号;
2)另一部分是自由端口,以本地方式进行分配。当某应用程序想要通过网络和远地程序通信之前,它会首先申请自由端口号与远地程序通信,主机操作系统临时为该进程分配一个本地唯一的端口号。
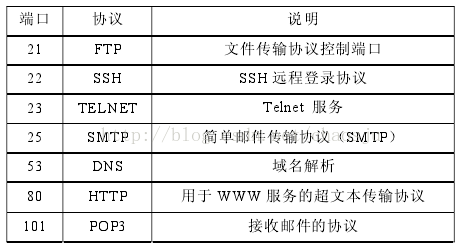
下图是常用的保留端口,部分还有一定的参考价值。
传统上一直是基于端口映射机制对应用层协议进行识别。随着越来越多的网络协议不使用固定的端口进行通信,基于报文端口的协议识别受到很大限制,准确性受到很大挑战。但由于基于公知端口进行协议识别操作简单,识别速度快,现在的带宽越来越大,在识别
DNS、SMTP、POP3 等目前端口比较固定的传统协议时依然有一定的价值。
基于测度的协议识别
基于测度的协议识别根据各协议产生的流测度的差异识别应用层协议。
基于测度识别协议无需分析报文体的内容,只要根据报文头中的域值、报文大小、报文间隙等特征分析流量所属的应用类型。例如,Web 浏览产生的流量一般为短流小报文,而各种 P2P 协议的流量一般为长流大报文。基于测度的协议识别一般采用机器学习的方式,利用已经按协议类型分类的报文来训练系统,使其把握该类应用的流测度特征以识别新的流量。
温超、郑雪峰等提出通过网络流量信息识别 P2P 协议。基于流量分析的 P2P协议识别方法,依据以下四个特征识别 P2P 协议:
1)P2P 主机的上下行流量基本相当;
2)P2P 主机连接的其它主机的数量较多;
3)P2P 主机既为服务器又为客户端;
4)P2P主机的监听端口的特点与其它协议不同。
虽然基于流量分析的识别方法只需对数据包的头部信息进行检测,不需要检测数据包的负载,具有简单、高效的特点。但是只能识别出网络流量是否为 P2P 协议,无法识别出具体是哪种 P2P 协议或是哪种非 P2P
协议,具有应用的局限性。PS:有些p2p下载应用也是可以识别的,后续的文章可以分析一下试试。
基于负载的协议识别(基于正则表达式)
基于负载的协议识别,对应用层协议交互过程中产生报文的内容进行分析,找出不同于其它协议的模式特征,根据各协议特有的模式特征确定流量所属协议类型。基于负载的协议识别主要有采用固定字符串和正则表达式来表示协议特征两种方式。这也是现在最常用的方式,大部门应用可以利用这种方式识别。
采用固定字符串的方式过于笨拙,在这不在做介绍,其实可以把它理解成基于正则表达式的子集。正则表达式比固定字符串具有更强的表达能力和更好的灵活性,采用正则表达式代替固定字符串表示协议的特征成为研究的热点。
正则表达式:又称正规表示法、常规表示法(
英语:Regular
Expression,在代码中常简写为regex、regexp或RE)。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的
字符串。
正则表达式语法学习网站:http://msdn.microsoft.com/zh-cn/library/ae5bf541(VS.80).aspx
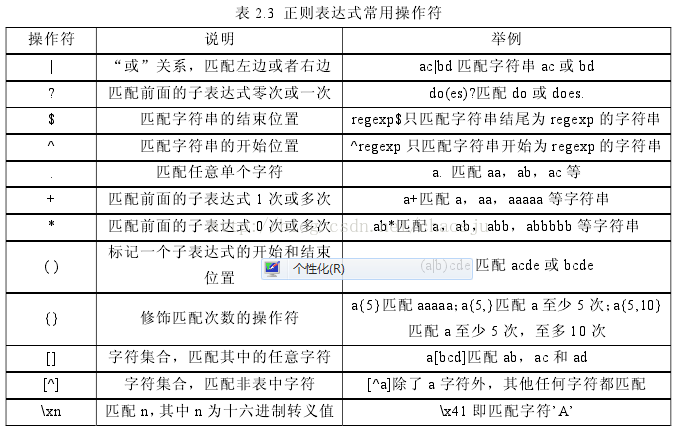
上面说的相对比较全的正则表达式,下面这张表相对来说比较常用的: