- - 数据库 - ITeye博客
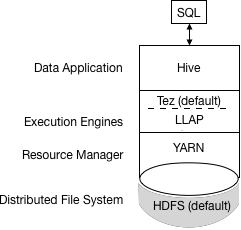
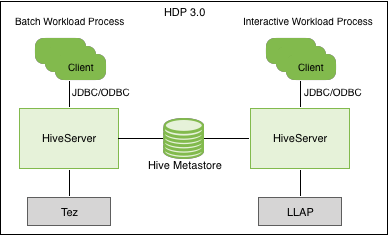
Apache Hive 3.x 架构介绍. hive 的更新操作一直是大数据仓库头痛的问题,在3.x之前也支持update,但是速度太慢,还需要进行分桶,现在hive 支持全新ACID,并且底层采用TEZ 和内存进行查询,性能是hive2的50倍. 生产建议升级到hive3.1.1版本. 了解Apache Hive 3主要的设计更改,例如默认的ACID事务处理和仅支持瘦配置客户端,可以帮助您使用新功能来满足企业数据仓库系统不断增长的需求.
- -
在工作中使用hive比较多,也写了很多HiveQL,对于那些执行比较慢的语句,看着那些执行慢的任务显示的进度真的是欲哭无泪. 是真的数据量比较大,计算比较复杂,还是还没将相关参数设置最优呢. 这里对Hive常用的一些性能优化进行了总结. Hive在读数据的时候,可以只读取查询中所需要用到的列,而忽略其他的列.
- - 数据库 - ITeye博客
经常看到一些Hive优化的建议中说当小表与大表做关联时,把小表写在前面,这样可以使Hive的关联速度更快,提到的原因都是说因为小表可以先放到内存中,然后大表的每条记录再去内存中检测,最终完成关联查询. 这样的原因看似合理,但是仔细推敲,又站不住脚跟. 如果所谓的小表在内存中放不下怎么办. 我用2个只有几条记录的表做关联查询,这应该算是小表了,在查看reduce的执行日志时依然是有写磁盘的操作的.
- - 博客园_首页
继续《 那些年使用Hive踩过的坑》一文中的剩余部分,本篇博客赘述了在工作中总结Hive的常用优化手段和在工作中使用Hive出现的问题. 首先,我们来看看Hadoop的计算框架特性,在此特性下会衍生哪些问题. 数据量大不是问题,数据倾斜是个问题. jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,耗时很长.
- - 奔跑的兔子
一个Hive查询生成多个map reduce job,一个map reduce job又有map,reduce,spill,shuffle,sort等多个阶段,所以针对hive查询的优化可以大致分为针对MR中单个步骤的优化(其中又会有细分),针对MR全局的优化,和针对整个查询(多MR job)的优化,下文会分别阐述.
- - 极客521 | 极客521
一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,Reduce,Spill,Shuffle,Sort等多个阶段,所以针对Hive查询的优化可以大致分为针对MR中单个步骤的优化(其中又会有细分),针对MR全局的优化,和针对整个查询(多MRJob)的优化,下文会分别阐述.
- - 互联网 - ITeye博客
一、 控制hive任务中的map数: . 1. 通常情况下,作业会通过input的目录产生一个或者多个map任务. 主要的决定因素有: input的文件总个数,input的文件大小,集群设置的文件块大小(目前为128M, 可在hive中通过set dfs.block.size;命令查看到,该参数不能自定义修改);.
- - CSDN博客推荐文章
一、 Hive join优化. 也可以显示声明进行map join:特别适用于小表join大表的时候,SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a join b on a.key = b.key. 2. 注意带表分区的join, 如:.
- - CSDN博客云计算推荐文章
select a.* from a join b on a.id = b.id
select a.* from a join b on (a.id = b.id and a.department = b.department). 在使用join写查询的时候有一个原则:应该将条目少的表或者子查询放在join操作符的左边.
- - 开源软件 - ITeye博客
Hive是将符合SQL语法的字符串解析生成可以在Hadoop上执行的MapReduce的工具. 使用Hive尽量按照分布式计算的一些特点来设计sql,和传统关系型数据库有区别,. 所以需要去掉原有关系型数据库下开发的一些固有思维. 1:尽量尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段.