图像识别VPU——易用的嵌入式AI支持深度学习平台介绍-桐烨科技-踏上文明的征程-51CTO博客
- -公司玩了大半年的嵌入式AI平台,现在产品进入量产模式,也接触了很多嵌入式方案,有了一些心得体会,本人不才,在这里介绍一下一款简单易用的嵌入式AI方案——Movidius Myriad 2 VPU(MA2450) 和 Myriad X VPU(MA2485). 这里本人重点提示:简单易用的嵌入式AI.
公司玩了大半年的嵌入式AI平台,现在产品进入量产模式,也接触了很多嵌入式方案,有了一些心得体会,本人不才,在这里介绍一下一款简单易用的嵌入式AI方案——Movidius Myriad 2 VPU(MA2450) 和 Myriad X VPU(MA2485)。这里本人重点提示:简单易用的嵌入式AI。现在好多家半导体厂商已经推出嵌入式AI平台,比如华为海思今年4月份发布的Hi3559A,这个样品超过100美金/片,集成寒武纪AI核(遗憾不是最新的版本,因为最近寒武纪又发布最新的AI版本,同时还集成大名鼎鼎Cadence的 4核DSP);赛灵思Xilinx的FPGA—— Zynq 7020,ZU2CG开发难度大,价格不菲,还有其他家的ARM+FPGA方案也不便宜,开发难度也不小;英伟达的GPU——JETSON TX2,TX2核心板英伟达自己生产,价格太贵,不适合产品小型化生产;TI 的TDA2x系列和DAVINCI系列最新的DM505,以及后续的版本,专注辅助驾驶ADAS,他的64bit浮点DSP C66X+EYE也支持深度学习(不要小瞧这个EYE,深度学习方面一个EYE可比2个C66X 浮点DSP还牛),不过功耗太高,软件资源也不好搞到,海掏买美国D3公司DEMO板价格不菲,而且没技术支持开发周期过长,价格也不便宜。鉴于本公司的资源(小公司),我们选择了Intel的Movidius Myriad 2,在软件资源方面,Intel推出神经计算棒的免费NCSDK,这个软件资源让很多公司看到嵌入AI领域的希望,这一手Intel做得不错,很多公司都在嵌入式开发板树莓派3上面加这个神经计算棒学习,销售比较火爆。当然如果要拿到完整的MDK,直接使用Myriad 2 VPU和Myriad X VPU做控制器(比如直接使用片上LEON4运行客户软件,直接接CMOS SENSOR,接网口芯片,4K H.264和H.265编解码,USB,PCIE,SPI,I2C,UART控制等等),那就得花超过100---400万RMB不菲的门槛费,这些就是中大型公司的玩法,这点钱无所谓。
Movidius Myriad 2 VPU (Vision Processing Unit——视觉处理器)被称作为“第三次影像革命的开端”的芯片方案。Movidius 已经被Intel收购,Intel Movidius Myriad 2 VPU可在不同目标应用中提供低功耗、高性能的视觉处理解决方案,其中包括嵌入式深度神经网络、位姿估计、室内导航、3D深度感应、3D制图(3D扫描建模),视觉惯性测距,以及手势/眼部跟踪,基于深度学习的环境感知。
安防巨头海康和大华把Movidius Myriad 2(MA2450)视觉处理单元应用于视频监控摄像头,在完成监控和录制等传统任务外,提供人群密度监测、立体视觉、面部识别、人数统计、行为分析以及检测非法停放车辆等先进的视频分析功能。Myriad 2为大疆最近发布的首款迷你无人机Spark提供了视觉智能技术,该无人机早就大批量生产。
这颗芯片被一分为二,其中一部分有12个SHAVE 128位处理器,专为影像处理负载做优化,每颗都运作在600MHz的频率下,而且有超频潜能,第一代的180MHz显然是不够看的;与这些处理器相匹配的是Movidius称之SIPP过滤器(Streaming Inline Processing Pipeline filters)的硬件加速器——这玩意儿可完成一些预设的影像处理任务,比如将来自不同类型摄像头的数据融合到一起,或者将多个视频内容接合到一起;另外还有2个32位RISC处理器用于芯片管理,这就是LEON4(LEON是一款32位RISC处理器,支持SPARC V8指令集,由欧洲航天总局旗下的Gaisler Research开发、维护,目的是摆脱欧空局对美国航天级处理器的依赖。LEON的主要产品线包括LEON2、LEON3、LEON4)。SHAVE这一端对原始影像数据做计算处理,OEM厂商可以选择不同的方案;SIPP则可协力处理通常任务;集中型的寄存器结构令芯片两侧可同时对相同的数据做处理。这些对于降低延迟是相当有价值的。
鉴于这样的架构设计,Myriad 2 VPU芯片面积是6.5mm,厚度1mm,具体的性能则是可以48fps的帧率同时处理来自12个1300万像素摄像头的数据,以60fps拍摄4K视频自然也是毫无压力,功耗低于0.5W(台积电28nm HPC工艺)。按照El-Ouazzane的说法,相比能够提供同等效果的GPU,Myriad 2的功耗低了最少10倍。
深度学习框架方面,支持Caffe,Caffe的全称是Convolutional Architecture for Fast Feature Embedding,作者是博士毕业于伯克利的浙江人贾扬清,它是一个清晰、高效的开源深度学习框架,核心语言是C++,支持命令行、Python和Matlab接口,既可以在CPU上运行也可以在GPU上运行。同时也支持Google的TensorFlow。所以C/C++、Python程序员可以快速切入深度学习的架构去工作。所以说,支持深度学习易用的嵌入式平台,非VPU莫属。前面提到的Intel Movidius神经元棒,包括他们提供的免费NCSDK软件包,可以满足那些C/C++程序员、Python程序员轻松在WIN下直接开发AI软件,也可以在ubuntu下直接开发软件,很方便,而在嵌入式前端,同样也可以支持NCSDK软件包,玩得好Caffe和TensorFlow应该很快上手进行算法优化和设计。
而2017年推出的Movidius Myriad X(MA2485)超级NB,Myriad X将提供十倍于Myriad 2同样功率范围内深层神经网络(DNN)的性能。
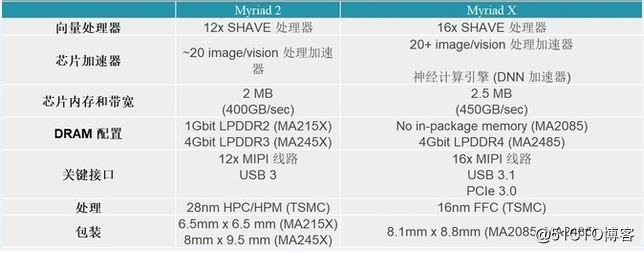
Myriad X 有4个可C编程的128位VLIW矢量处理器和可配置的MIPI通道,并扩展了2.5 MB的芯片内存和更多的固定功能成像/视觉加速器。就像在Myriad X中发现的一样,Myriad X的矢量单位都是专有的SHAVE (流混合的架构矢量引擎)处理器,对计算机视觉工作负载进行了优化。Myriad X也支持最新的LPDDR4,MA2085变体只配置了外部存储器接口。
Myriad X的另一个新功能是4K硬件编码,4K在30Hz(H.264/H.265)和60 Hz(M/JPEG)支持。从接口上看,Myriad X带来了USB 3.1和PCIe 3.0支持,这两个都是Myriad VPU家族新支持的接口。与Myriad 2一样,所有这些都是在同一个小于2W的功率范围中完成的,更具体地说是在1W以内,使用台积电16nm FFC工艺。所以说,在如此低功耗下就能完成很多视频处理和深度学习,前面提到的几个平台根本无法做到。
从目前前端图像识别市场反馈的角度看,这个Myriad 2 VPU(MA2450) 和 Myriad X VPU(MA2485)芯片出货量比较大。还有在开发板-学习板方面,便宜的树莓派3,树莓派3+都可以直接拿神经计算棒进行深度学习算法开发,简单易用。如果是产品设计方面,本公司的VPU模组和ARM + VPU方案也可以快速出产品。以下是在本公司的HI3516D+VPU和Hi3519V101+VPU板子上面测试的结果图:
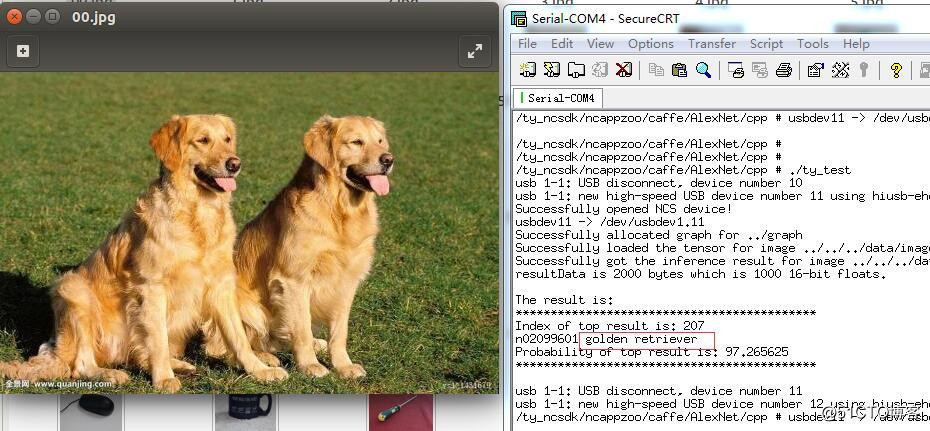
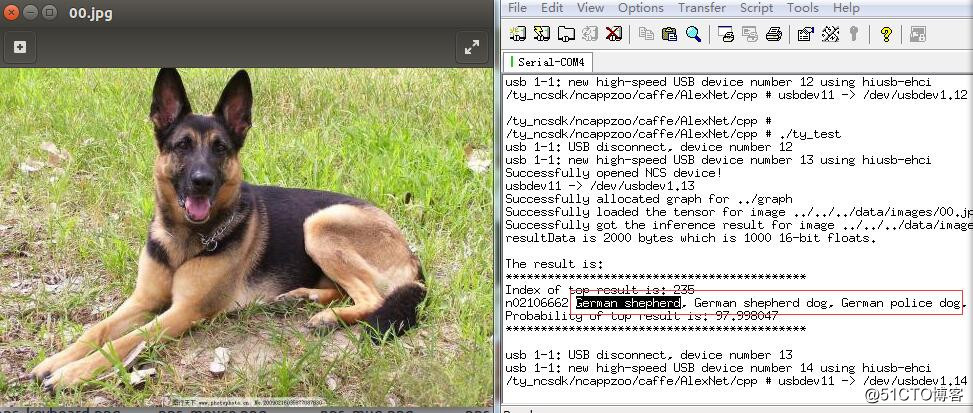
本公司开发的AI平台,是ARM+VPU组合模式,我们低端使用华为海思Hi3516A/D + VPU和高端使用Hi3519V101+VPU,国产和进口的组合,因为海思Hi3516A/D和Hi3519V101支持H.264/H.265编解码,带有ISP,还带有一个IVE(智能视频分析算法加速器,确切的说是传统机器视觉算法加速器),然后再加上Intel Movidius 这个支持深度学习的VPU,就是我们ARM+VPU支持深度学习平台。也就是说我们的平台同时支持传统机器视觉算法+深度学习算法,而且还支持H.265编解码,海思Hi3516A/D和Hi3519V101的IVE支持的功能如下:
★DMA:支持直接拷贝、间隔拷贝、内存填充。
★Filter:支持 5x5 模板滤波。
★CSC:支持 YUV2RGB、 YUV2HSV、 YUV2LAB、 RGB2YUV 颜色空间转换。
★FilterAndCSC:支持 5x5 模板滤波和 CSC 的复合功能。
★Sobel:支持 5x5 模板 Sobel-like 梯度计算。
★MagAndAng\Canny:支持 5x5 模板梯度幅值和幅角计算、 Canny 边缘提取。
★Erode:支持 5x5 模板腐蚀。
★Dilate:支持 5x5 模板膨胀。
★Thresh\Thresh_S16\Thresh_U16:支持图象阈值化处理。
★And\Or\Xor:支持两幅图象相与、或、异或。
★Add\Sub:支持两幅图象相加权加、减。
★Integ:支持积分图计算。
★Hist:支持直方图统计。
★Map:支持对图像通过 256 级 map 映射赋值。
★16BitTo8Bit:支持 16bit 数据到 8bit 数据线性转换。
★OrdStatFilter:支持顺序统计量滤波:中值滤波、最大值滤波、最小值滤波。
★Bernsen:支持 Bernsen 二值化。
★NCC:支持两相同大小图像互相关系数计算。
★CCL:支持连通区域标记。
★GMM:支持灰度图与 RGB 图的混合高斯背景建模。
★LBP:支持简单局部二值模式计算。
★NormGrad:支持归一化梯度计算。
★LKOpticalFlow:支持 LK 光流跟踪。
★STCorner:支持 ShiTomasi 角点检测。
★GradFg:支持梯度前景运算。
★MatchBgModel\UpdateBgModel:支持背景匹配、背景更新。
★ANN_MLP_Predict:支持 ANN_MLP 预测。
★SVM_Predict:支持 SVM 预测。
★支持单独进行软复位。
★支持 128bit AXI 总线和 32 bit APB 总线。
★支持链表级中断、节点级中断和超时中断。
★支持 SP 400、 SP420 (semi-plannar 420)、 SP422 (semi-plannar 422)、 package、
planar 等输入格式。
★支持 SP 400、 SP420、 SP422、 package、 plannar 等输出格式。
这些功能直接集成在芯片内部,通过加载LIB和函数调用就可以使用了,不需要ARM来运算。搞过传统算法的人对上面列的内容应该很熟悉,这里就不累赘。
至于Hi3519V101+VPU的开发攻略,本人不打算写了,因为海思的SDK包里面的手册就写得很详细了,VPU移植到ARM平台的NCSDK软件Intel官网也有,本人现在没有深入去研究,都是员工在搞,在这里写出来就比较班门弄斧。
下图就是Hi3519V101 SDK的里面的文档,看了这些详细的文档,有点嵌入式底子的工程师应该知道如何搭建环境、编译、和烧写了。
下面图片是我们自己做的嵌入式VPU模块和嵌入式Hi3519V101+VPU核心板硬件,没有硬件平台支持,再好的算法也不能转化价值。还有这个VPU支持Google的TensorFlow,这个对Python程序员应该很快进入嵌入式AI开发角色,而不是停留在PC端和服务端,现在很多大公司和有前沿实力的创业公司都往前端布局,嵌入式AI平台会越来越火,特别是LPDDR5出来的时候,会使嵌入式AI芯片的带宽大大提升,这样更加支持算法度更复杂的深度学习算法。
(项目双赢合作,联系QQ:2505133162)



