使用Java 8 Streams和Spring Data JPA流式传输MySQL结果
- -2015年10月19日| KrešimirNesek. 从1.8版开始,Spring数据项目包含一个有趣的功能 - 通过一个简单的API调用,开发人员可以请求将数据库查询结果作为Java 8流返回. 在技术上可行并且由底层数据库技术支持的情况下,结果将逐个流式传输,并且可以使用流操作进行处理.
从1.8版开始,Spring数据项目包含一个有趣的功能 - 通过一个简单的API调用,开发人员可以请求将数据库查询结果作为Java 8流返回。在技术上可行并且由底层数据库技术支持的情况下,结果将逐个流式传输,并且可以使用流操作进行处理。在处理大型数据集时(例如,以特定格式导出大量数据库数据),此技术特别有用,因为除其他外,它可以限制应用程序处理层中的内存消耗。在本文中,我将讨论当Spring数据流与MySQL数据库一起使用时的一些好处(以及陷阱!)。
从数据库中获取和处理大量数据(通过较大的数据集,不适合正在运行的应用程序的内存中)的天真方法通常会导致内存不足。当使用诸如JPA之类的ORM /抽象层时,尤其如此,您无法访问较低级别的工具,这些工具将允许您手动管理从数据库中获取数据的方式。通常,至少对于我通常使用的堆栈--MySQL,Hibernate / JPA和Spring Data--大型查询的整个结果集将完全由MySQL的JDBC驱动程序或之后的上述框架之一获取。如果结果集足够大,这将导致OutOfMemory异常。
让我们专注于一个示例 - 将大型查询的结果导出为CSV文件。当遇到这个问题,当我想留在Spring Data / JPA世界时,我通常会选择寻呼解决方案。查询分解为较小的查询,每个查询返回一页结果,每个查询的大小有限。Spring Data提供了很好的分页/切片功能,使这种方法易于实现。Spring Data的PageRequests被转换为MySQL中的限制/偏移查询。但有一些警告。使用JPA时,实体会缓存在EntityManager的缓存中。需要清除此缓存以使垃圾收集器能够从内存中删除旧的结果对象。
让我们看看分页策略的实际实现在实践中是如何表现的。出于测试目的,我将使用 基于Spring Boot,Spring Data,Hibernate / JPA和MySQL的小型 应用程序。它是一个待办事项列表管理webapp,它具有将所有待办事项下载为CSV文件的功能。待办事项存储在单个MySQL表中。该表已填充了100万条目。这是分页/切片导出功能的代码:
@RequestMapping(value = "/todos2.csv", method = RequestMethod.GET)
public void exportTodosCSVSlicing(HttpServletResponse response) {
final int PAGE_SIZE = 1000;
response.addHeader("Content-Type", "application/csv");
response.addHeader("Content-Disposition", "attachment; filename=todos.csv");
response.setCharacterEncoding("UTF-8");
try {
PrintWriter out = response.getWriter();
int page = 0;
Slice<Todo> todoPage;
do {
todoPage = todoRepository.findAllBy(new PageRequest(page, PAGE_SIZE));
for (Todo todo : todoPage) {
String line = todoToCSV(todo);
out.write(line);
out.write("\n");
}
entityManager.clear();
page++;
} while (todoPage.hasNext());
out.flush();
} catch (IOException e) {
log.info("Exception occurred " + e.getMessage(), e);
throw new RuntimeException("Exception occurred while exporting results", e);
}
}
这是在导出操作正在进行时内存使用情况的样子:
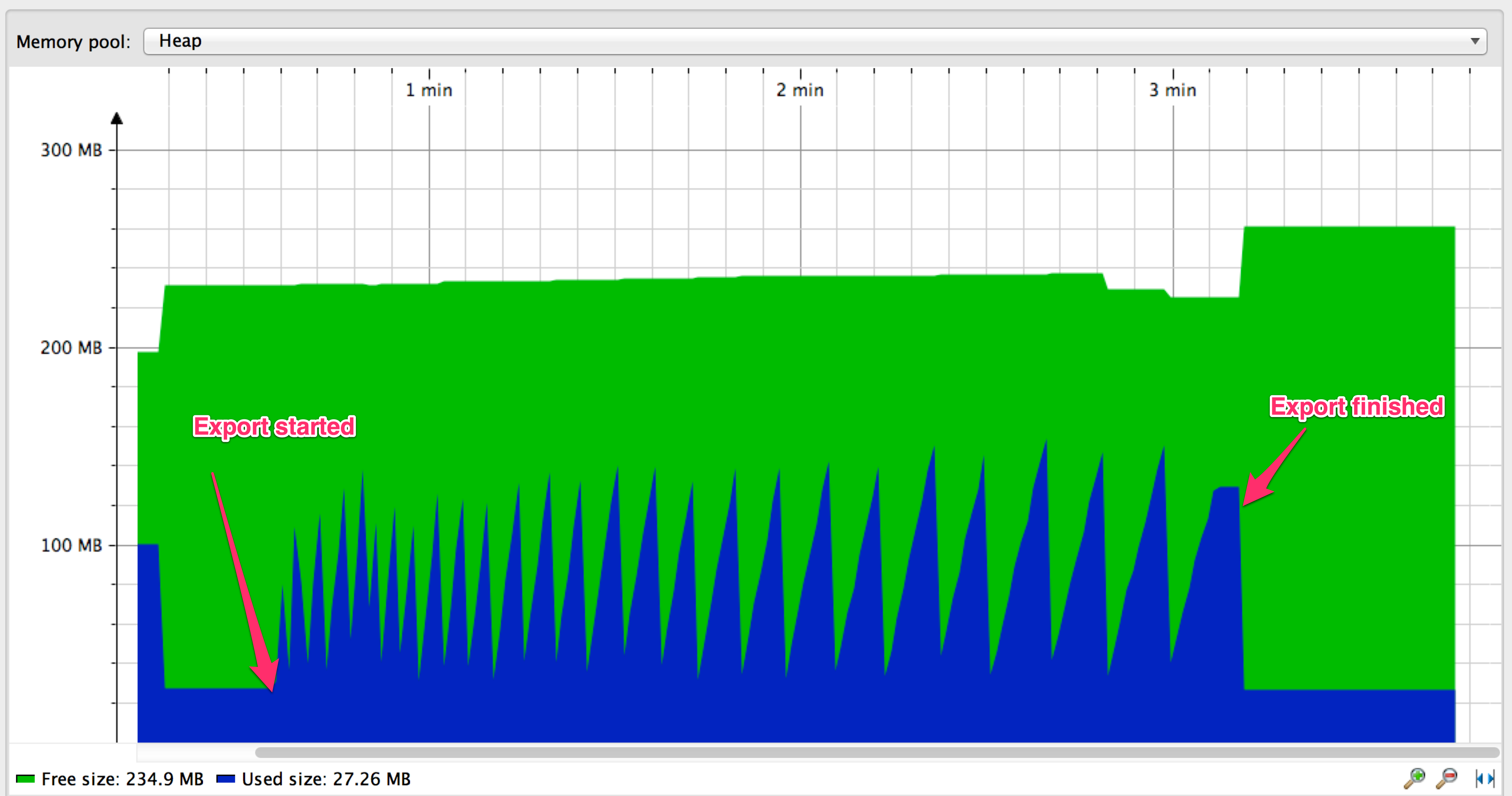
内存使用情况图形具有锯齿形状:内存使用量随着从数据库中提取条目而增加,直到GC启动并清除已经从EntityManager缓存中输出和清除的条目。分页方法效果很好但绝对有改进的余地:
我们发出1000个数据库查询(条目数/ PAGE_SIZE)来完成导出。如果我们能够避免执行这些查询的开销会更好。
您是否注意到随着出口的进展以及峰值之间的距离增加,图表上的齿的上升斜率越来越小?似乎从DB获取新的entires的速度越来越慢。其原因是MySQL的限制/偏移性能特征 - 随着偏移量变大,查找和返回所选行所需的时间越来越多。
我们可以使用Spring Data 1.8中提供的新流功能来改进上述内容吗?我们试试吧。
Spring Data 1.8引入了对流式结果集的支持。存储库现在可以声明返回Java 8实体对象流的方法。例如,现在可以将具有以下签名的方法添加到存储库:
@Query("select t from Todo t")
Stream<Todo> streamAll();
Spring Data将使用特定于特定JPA实现的技术(例如Hibernate,EclipseLink等)来传输结果集。让我们使用此流功能重新实现CSV导出:
@RequestMapping(value = "/todos.csv", method = RequestMethod.GET)
@Transactional(readOnly = true)
public void exportTodosCSV(HttpServletResponse response) {
response.addHeader("Content-Type", "application/csv");
response.addHeader("Content-Disposition", "attachment; filename=todos.csv");
response.setCharacterEncoding("UTF-8");
try(Stream<Todo> todoStream = todoRepository.streamAll()) {
PrintWriter out = response.getWriter();
todoStream.forEach(rethrowConsumer(todo -> {
String line = todoToCSV(todo);
out.write(line);
out.write("\n");
entityManager.detach(todo);
}));
out.flush();
} catch (IOException e) {
log.info("Exception occurred " + e.getMessage(), e);
throw new RuntimeException("Exception occurred while exporting results", e);
}
}
我像往常一样开始出口,但结果没有显示出来。发生了什么?
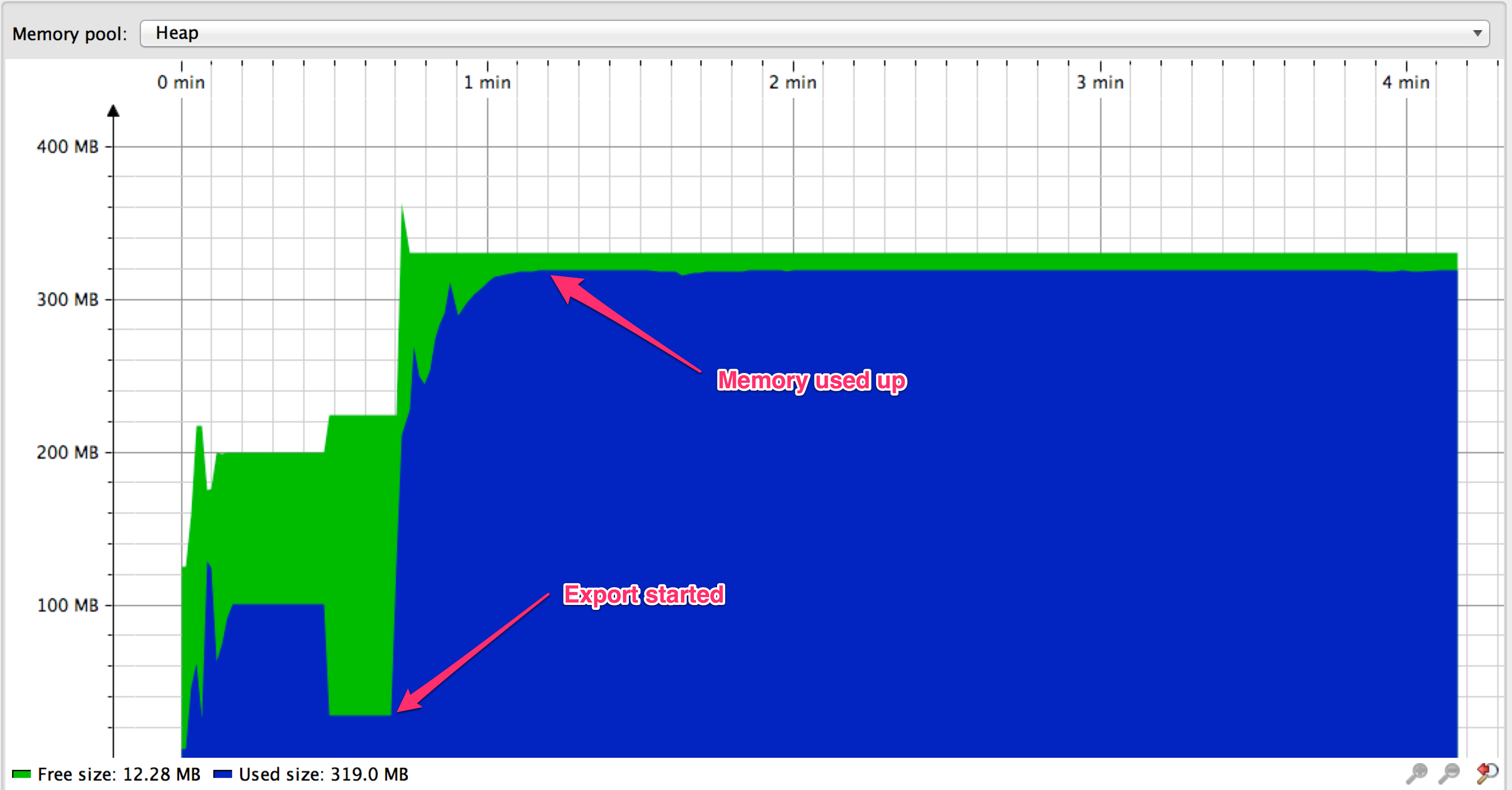
看来我们的内存耗尽了。此外,没有写入任何结果 HttpServletResponse。为什么这不起作用?在深入研究源代码之后, org.springframework.data.jpa.provider.PersistenceProvider可以发现Spring Data正在使用可滚动的结果集来实现结果集流。谷歌搜索可滚动的结果集和MySQL表明,使用它们时会有问题。例如,这是 MySQL的JDBC驱动程序文档的引用:
默认情况下,ResultSet完全检索并存储在内存中。在大多数情况下,这是最有效的操作方式,并且由于MySQL网络协议的设计,更容易实现。如果您正在使用具有大量行或大值的ResultSet,并且无法在JVM中为所需内存分配堆空间,则可以告诉驱动程序一次将结果流回一行。要启用此功能,请按以下方式创建Statement实例:
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY,java.sql.ResultSet.CONCUR_READ_ONLY); stmt.setFetchSize(Integer.MIN_VALUE);只有正向的只读结果集与获取大小Integer.MIN_VALUE的组合用作驱动程序逐行传输结果集的信号。在此之后,将逐行检索使用该语句创建的任何结果集。
这种方法有一些警告。您必须先读取结果集中的所有行(或关闭它),然后才能对连接发出任何其他查询,否则将抛出异常。
好吧,似乎在使用MySQL以真正流式传输结果时,我们需要满足三个条件:
Spring-only似乎已经由Spring Data设置,因此我们不必对此做任何特别的事情。我们的代码示例已经具有 @Transactional(readOnly = true)足以满足第二个标准的注释。似乎缺少的是fetch-size。我们可以使用存储库方法的查询提示进行设置:
...
import static org.hibernate.jpa.QueryHints.HINT_FETCH_SIZE;
@Repository
public interface TodoRepository extends JpaRepository<Todo, Long> {
@QueryHints(value = @QueryHint(name = HINT_FETCH_SIZE, value = "" + Integer.MIN_VALUE))
@Query(value = "select t from Todo t")
Stream<Todo> streamAll();
...
}
有了查询提示,让我们再次运行导出:
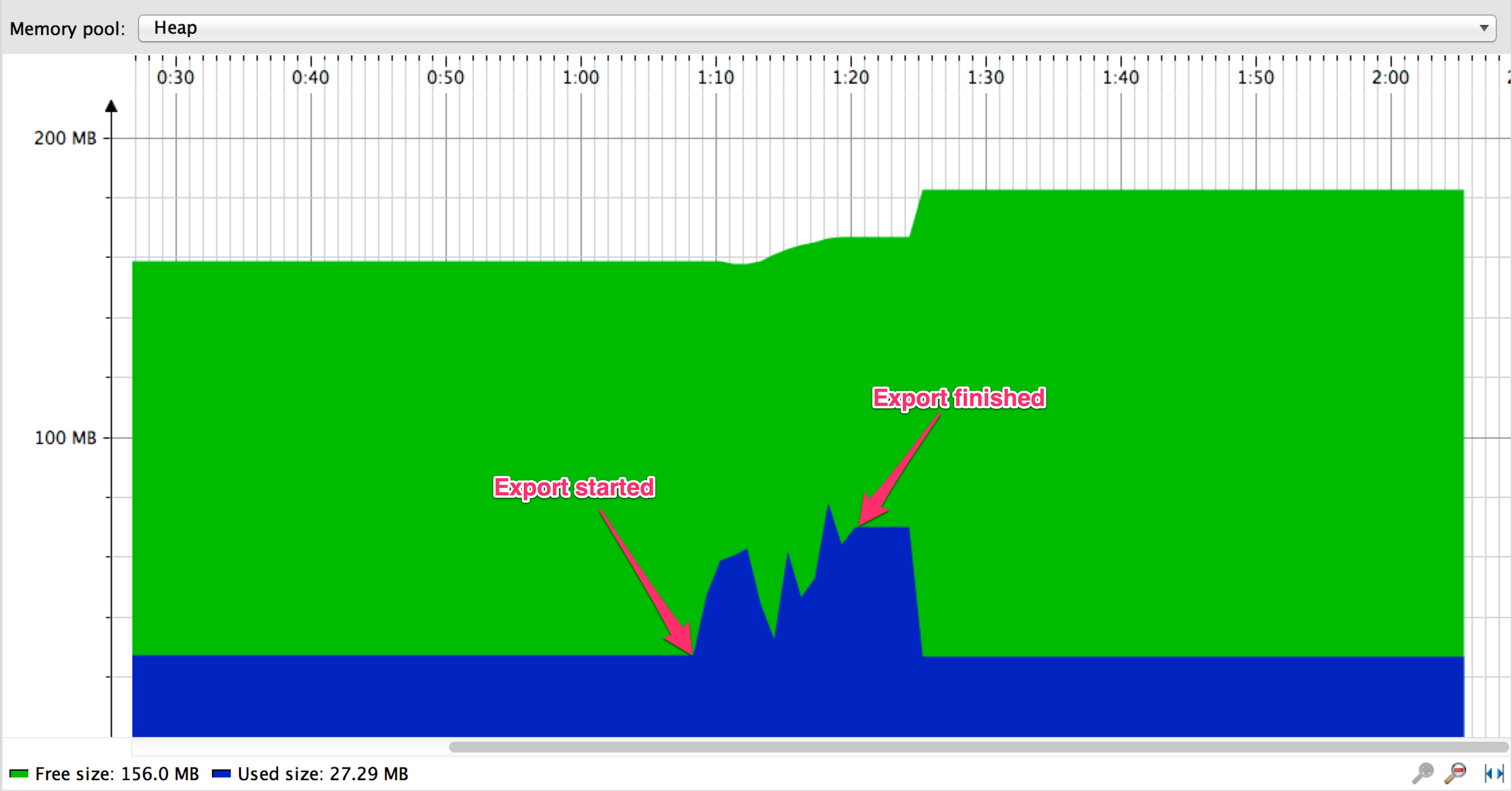
现在一切正常,似乎它比分页方法更有效:
HttpServletResponse。如果我们使用默认的Spring的消息转换器(例如从控制器方法返回流),那么很有可能这不会按预期工作。这是 一篇关于这个主题的有趣 文章。我很乐意尝试使用其他数据库进行测试,并通过Spring消息转换器探索流式传输结果的可能性,如上面链接的文章中所示。如果你想自己试验一下,测试应用程序 可以在github上找到。我希望你发现这篇文章很有意思,我欢迎你在下面的评论部分提出意见。