数据仓库
- Ran - Linux@SOHU翻译:马少兵、曾怀东、朱翊然、林业. 尽管服务器存储、处理能力得到有效的提高,以及服务器价格的降低,让人们能够负担起大量的服务器,但是商业软件应用和监控工具快速的增加,还是使得人们被大量的数据所困扰. 在数据仓库领域中的许多系统管理员、应用开发者,以及初级数据库管理员发现,他们正在处理“海量数据”-不管你准备与否-都会有好多不熟悉的术语,概念或工具.
数据质量一直是数据仓库领域一个比较令人头疼的问题,因为数据仓库上层对接很多业务系统,业务系统的脏数据,业务系统变更,都会直接影响数据仓库的数据质量。因此数据仓库的数据质量建设是一些公司的重点工作。
一、数据质量
数据质量的高低代表了该数据满足数据消费者期望的程度,这种程度基于他们对数据的使用预期。数据质量必须是可测量的,把测量的结果转化为可以理解的和可重复的数字,使我们能够在不同对象之间和跨越不同时间进行比较。 数据质量管理是通过计划、实施和控制活动,运用质量管理技术度量、评估、改进和保证数据的恰当使用。
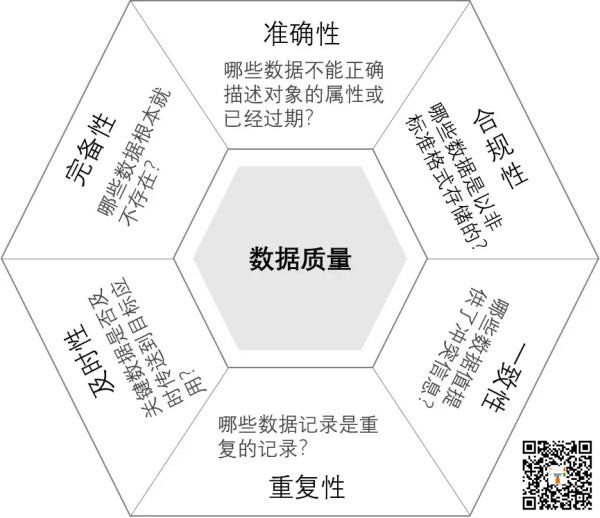
二、数据质量维度
1、准确性:数据不正确或描述对象过期
2、合规性:数据是否以非标准格式存储
3、完备性:数据不存在
4、及时性:关键数据是否能够及时传递到目标位置
5、一致性:数据冲突
6、重复性:记录了重复数据
三、数据质量分析
数据质量分析的主要任务就是检查数据中是否存在脏数据,脏数据一般是指不符合要求以及不能直接进行相关分析的数据。脏数据包括以下内容:
1、缺省值
2、异常值
3、不一致的值
4、重复数据以及含有特殊符号(如#、¥、*)的数据
我们已经知道了脏数据有4个方面的内容,接下来我们逐一来看这些数据的产生原因,影响以及解决办法。
第一、 缺省值分析
产生原因:
1、有些信息暂时无法获取,或者获取信息的代价太大
2、有些信息是被遗漏的,人为或者信息采集机器故障
3、属性值不存在,比如一个未婚者配偶的姓名、一个儿童的固定收入
影响:
1、会丢失大量的有用信息
2、数据额挖掘模型表现出的不确定性更加显著,模型中蕴含的规律更加难以把握
3、包含空值的数据回事建模过程陷入混乱,导致不可靠输出
解决办法:
通过简单的统计分析,可以得到含有缺失值的属性个数,以及每个属性的未缺失数、缺失数和缺失率。删除含有缺失值的记录、对可能值进行插补和不处理三种情况。
第二、 异常值分析
产生原因:业务系统检查不充分,导致异常数据输入数据库
影响:不对异常值进行处理会导致整个分析过程的结果出现很大偏差
解决办法:可以先对变量做一个描述性统计,进而查看哪些数据是不合理的。最常用的统计量是最大值和最小值,用力啊判断这个变量是否超出了合理的范围。如果数据是符合正态分布,在原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值,如果不符合正态分布,也可以用原理平均值的多少倍标准差来描述。
第三、 不一致值分析
产生原因:不一致的数据产生主要发生在数据集成过程中,这可能是由于被挖掘的数据是来自不同的数据源、对于重复性存放的数据未能进行一致性更新造成。例如,两张表中都存储了用户的电话号码,但在用户的号码发生改变时只更新了一张表中的数据,那么两张表中就有了不一致的数据。
影响:直接对不一致的数据进行数据挖掘,可能会产生与实际相悖的数据挖掘结果。
解决办法:注意数据抽取的规则,对于业务系统数据变动的控制应该保证数据仓库中数据抽取最新数据
第四、 重复数据及特殊数据产生原因:
产生原因:业务系统中未进行检查,用户在录入数据时多次保存。或者因为年度数据清理导致。特殊字符主要在输入时携带进入数据库系统。
影响:统计结果不准确,造成数据仓库中无法统计数据
解决办法:在ETL过程中过滤这一部分数据,特殊数据进行数据转换。
四、数据质量管理
大多数企业都没有一个很好的数据质量管理的机制,因为他们不理解其数据的价值,并且他们不认为数据是一个组织的资产,而把数据看作创建它的部门领域内的东西。缺乏数据质量管理将导致脏数据、冗余数据、不一致数据、无法整合、性能底下、可用性差、责任缺失、使用系统用户日益不满意IT的性能。
在做数据分析之前一般都应该初步对数据进行评估。初步数据评估通过数据报告来完成的,数据报告通常在准备把数据存入数据仓库是做一次,它是全面跨数据集的,它描述了数据结构、内容、规则、和关系的概况。通过应用统计方法返回一组关于数据的标准特征,包括数据类型、字段长度、列基数、粒度、值、格式、模式、规则、跨列和跨表的数据关系,以及这些关系的基数。初步评估报告的目的是获得对数据和环境的了解,并对数据的状况进行描述。数据报告应该如下:
| 编号 | 数据质量维度 | 检查对象 | 检查项 | 检查项说明 |
| 1 | 有效性 | 数据行数 | 有效性检查,单字段、详细结果 | 将输入数据的值与一个既定的值域作比较 |
| 2 | 有效性 | 汇总数据 | 有效性检查,卷积汇总 | 汇总有效性检查的详细结果,将卷积的有效/无效值计数和百分比与历史水平作比较 |
| 3 | 重复性 | 数据行数 | 重复性检查,单字段、详细结果 | 将输入数据的值与一个既定的值域数据作比较,检查数据是否重复 |
| 4 | 重复性 | 汇总数据 | 重复性检查,卷积汇总 | 汇总重复性检查的详细结果,将卷积的重复数据计数和百分比与历史水平作比较 |
| 5 | 一致性 | 数据行数 | 一致性剖析 | 合理性检查,将记录数据的分布,与国企填充相同的字段的数据实例作比较 |
| 6 | 一致性 | 汇总数据 | 数据集内容的一致性,所表示的实体的不重复计数和记录数比率 | 合理性检查,将数据集内所表示的实体的不同值计数与阈值、历史计数、或总记录数作比较 |
| 7 | 一致性 | 汇总数据 | 数据集内容的一致性,二个所表示的实体的不重复计数的比率 | 合理性检查,将重要字段/实体的不同值计数的比率与阈值或历史比率作比较 |
| 8 | 一致性 | 数据行数 | 一致性多列剖析 | 合理性检查,为了测试业务规则,将跨多个字段的值的记录数分布和历史百分比作比较 |
| 9 | 一致性 | 日期时间类型检查 | 表内时序与业务规则的一致性 | 合理性检查,将日期与时序的业务规则作比较 |
| 10 | 一致性 | 日期时间类型检查 | 用时一致性 | 合理性检查,将经过的时间与过去填充相同字段的数据的实例作比较 |
| 11 | 一致性 | 数值类型检查 | 数额字段跨二级字段计算结果的一致性 | 合理性检查,将跨一个或多个二级字段的数额列的计算结果、数量总和、占总数的百分比和平均数量与历史计数和百分比作比较,用限定符缩小比较结果 |
| 12 | 完整性/有效性 | 数据行数 | 有效性检查,表内多列,详细结果 | 将同一个表中相关列的值与映射关系或业务规则中的值作比较 |
| 13 | 完整性/完备性 | 接收数据状态 | 数据集的完备性——重复记录的合理性检查 | 合理性检查,将数据集中重复记录占总记录的比例与数据集以前的实例的这个比例作比较 |
| 14 | 完备性 | 数据接收 | 数据集的完备性——将大小与过去的大小作比较 | 合理性检查,将输入的大小与以前运行同样的过程时的输入大小、文件记录数据、消息的数目或速率、汇总数据等作比较 |
| 15 | 完备性 | 接收数据状态 | 字段内容的完备性——来自数据源的默认值 | 合理性检查,将数据源提供的关键字段的默认值记录数据和百分比与一个既定的阈值或历史数量和百分比作比较 |
| 16 | 完备性 | 接收数据状态 | 基于日期标准的数据集的合理性 | 确保关键日期字段的最小和最大日期符合某个合理性规则 |
| 17 | 完备性 | 数据处理 | 数据集的完备性——拒绝记录的理由 | 合理性检查,将出于特定原因而被删除的记录数据和百分比与一个既定的阈值或历史数据和百分比作比较 |
| 18 | 完备性 | 数据处理 | 经过一个流程的数据集的完备性——输入和输出的利率 | 合理性检查,将处理的输入和输出之间的比率与数据集以前的实例的这个比率作比较 |
| 19 | 完备性 | 数值类型检查 | 字段内容的完备性——汇总的数额字段数的比率 | 数额字段合理性检查,将输入和输出数额字段汇总数的比率与数据集以前的实例的比率作比较,用于不完全平衡 |
| 20 | 完备性 | 数据处理 | 字段内容的完备性——推导的默认值 | 合理性检查,将推导字段的默认值记录数和百分比与一个既定的阈值或历史数量和百分比作比较 |
| 21 | 及时性 | 流程处理检查 | 用于处理的数据的交付及及时性 | 把数据交付的实际时间与计划数据交付时间作比较 |
| 22 | 及时性 | 数据处理 | 数据处理用时 | 合理性检查,将处理用时和历史处理用时或一个既定的时间限制作比较 |
| 23 | 及时性 | 流程处理检查情况 | 供访问的数据的及时可用性 | 将数据实际可供数据的消费者访问的时间与计划的数据可用时间作比较 |
| 24 | 一致性 | 数据模型 | 一个字段内的格式一致性 | 评估列属性和数据在字段内数据格式一致性 |
| 25 | 一致性 | 数据模型 | 一个字段默认值使用的一致性 | 评估列属性和数据在可被赋予默认值的每个字段中的默认值 |
| 26 | 完整性/一致性 | 数据模型 | 跨表的格式一致性 | 评估列属性和数据在整个数据库中相同数据类型的字段内数据格式的一致性 |
| 27 | 完整性/一致性 | 数据模型 | 跨表的默认值使用的一致性 | 评估列属性和数据在相同数据类型的字段默认值上的一致性 |
| 28 | 完备性 | 总体数据库内容 | 数据集的完备性——元数据和参考数据的充分性 | 评估元数据和参考数据的充分性 |
| 29 | 一致性 | 汇总数据日期检查 | 按聚合日期汇总的记录数的一致性 | 合理性检查,把与某个聚合日期关联的记录数和百分比与历史记录数和百分比作比较 |
| 30 | 一致性 | 汇总数据日期检查 | 按聚合日期汇总的数额字段数据的一致性 | 合理性检查,把按聚合日期汇总的数额字段数据总计和百分比与历史总计和百分比 |
| 31 | 一致性 | 总体数据库内容 | 与外部基准比较的一致性 | 把数据质量测量结果与一组基准,如行业或国家为类似的数据建立的外部测量基准作比较 |
| 32 | 一致性 | 总体数据库内容 | 数据集的完备性——针对特定目的的总体充分性 | 把宏观数据库内容(例如:数据域、记录数、数据的历史广度、表示的实体)与特定数据用途的需求作比较 |
| 33 | 一致性 | 总体数据库内容 | 数据集的完备性——测量和控制的总体充分性 | 评估测量和控制的成效 |
| 34 | 完整性/有效性 | 跨库跨表数据检查 | 有效性检查,跨表,详细结果 | 比较跨表的映射或业务规则的关系中的值,以保证数据关联一致性 |
| 35 | 完整性/一致性 | 跨库跨表数据检查 | 跨表多列剖析一致性 | 跨表合理性检查,将跨相关表的字段的值的记录数据分布于历史百分比作比较,用于测试遵从业务规则的情况 |
| 36 | 完整性/一致性 | 跨库跨表时序检查 | 跨表的时序与业务规则的一致性 | 跨表合理性检查,对日期值与跨表的业务规则进行时序比较 |
| 37 | 完整性/一致性 | 跨表的数值类型检查 | 跨表数额列计算结果的一致性 | 跨表合理性检查,比较相关表的汇总数额字段总计,占总计百分比、平均值或它们之间的比率 |
| 38 | 完整性/一致性 | 跨表的汇总数据日期检查 | 按聚合日期汇总跨表数额列的一致性 | 跨表合理性检查,比较相关表的按聚合日期汇总的数额字段总计、占总计百分比 |
| 39 | 完整性/完备性 | 跨库跨表数据检查 | 父/子参考完整性 | 确定父表/子表之间的参考完整性,以找出无父记录的子记录和值 |
| 40 | 完整性/完备性 | 跨库跨表数据检查 | 子/父参考完整性 | 确定父表/子表之间的参考完整性,以找出无子记录的父记录和值 |
| 41 | 完整性/完备性 | 接收数据状态 | 数据集的完备性——重复数据删除 | 确定并删除重复记录 |
| 42 | 完备性 | 数据接收 | 数据集的完备性——对于处理的可用性 | 对于文件,确认要处理的所有文件都可用 |
| 43 | 完备性 | 数据接收 | 数据集的完备性——记录数与控制记录相比 | 对于文件,对文件中的记录数据和在一个控制记录中记载的记录数作比较 |
| 44 | 完备性 | 数据接收 | 数据集的完备性——汇总数额字段数据 | 对于文件,对数额字段的汇总值和在一个控制记录中的汇总值作比较 |
| 45 | 完备性 | 接收数据状态 | 记录的完备性——长度 | 确保记录的长度满足已定义的期望 |
| 46 | 完备性 | 接收数据状态 | 字段的完备性——不可为空的字段 | 确保所有不可为空的字段都被填充 |
| 47 | 完备性 | 接收数据状态 | 基于日期标准的数据集的完备性 | 确保关键日期字段的最小和最大日期符合确定加载数据参数的规定范围 |
| 48 | 完备性 | 接收数据状态 | 字段内容的完备性——接收到的数据缺少要处理的关键字段 | 在处理记录前检测字段的填充情况 |
| 49 | 完备性 | 数据处理 | 数据集的完备性——经过一个流程的记录数据的平衡 | 整个数据处理过程的记录数、被拒绝的记录数据平衡,包括重复记录数平衡,用于完全平衡的情况 |
| 50 | 完备性 | 数据处理 | 经过一个流程的数据集的完备性—— 数额字段的平衡 | 整个过程中的数额字段内容平衡,用于完全平衡的情况 |
五、总结
数据报告中列出了很多的检查项都是围绕数据质量管理相关的检查,所以做一个数据分析项目前一定要知道客户的数据质量情况。如果数据质量很糟糕,最终影响的是项目分析的实际效果。例如,用户业务系统中客户信息只输入了客户名称,要分析客户类型就会存在缺省值。当然有一些维度属性我们可以通过事实表反算数据进入维度表来补充维度属性。个人建议在数据分析项目中一定要对维度属性进行评估,在项目处理前利用简单的模型告诉客户能够出具的效果。