滴滴实时计算发展之路及平台架构实践
- - zhisheng的博客滴滴的核心业务是一个实时在线服务,因此具有丰富的实时数据和实时计算场景. 本文将介绍滴滴实时计算发展之路以及平台架构实践. 随着滴滴业务的发展,滴滴的实时计算架构也在快速演变. 到目前为止大概经历了三个阶段:. 下图标识了其中重要的里程碑,稍后会给出详细阐述:. 在2017年以前,滴滴并没有统一的实时计算平台,而是各个业务方自建小集群.
滴滴的核心业务是一个实时在线服务,因此具有丰富的实时数据和实时计算场景。本文将介绍滴滴实时计算发展之路以及平台架构实践。
随着滴滴业务的发展,滴滴的实时计算架构也在快速演变。到目前为止大概经历了三个阶段:
业务方自建小集群阶段;
集中式大集群、平台化阶段;
SQL化阶段。
下图标识了其中重要的里程碑,稍后会给出详细阐述:
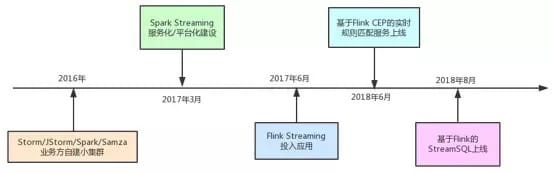
在2017年以前,滴滴并没有统一的实时计算平台,而是各个业务方自建小集群。其中用到的引擎有Storm、JStorm、Spark Streaming、Samza等。业务方自建小集群模式存在如下弊端:
需要预先采购大量机器,由于单个业务独占,资源利用率通常比较低;
缺乏有效的监控报警体系;
维护难度大,需要牵涉业务方大量精力来保障集群的稳定性;
缺乏有效技术支持,且各自沉淀的东西难以共享。
为了有效解决以上问题,滴滴从2017年年初开始构建统一的实时计算集群及平台。
技术选型上,我们基于滴滴现状选择了内部用大规模数据清洗的Spark Streaming引擎,同时引入On-YARN模式,并利用YARN的多租户体系构建了认证、鉴权、资源隔离、计费等机制。
相对于离线计算,实时计算任务对于稳定性有着更高的要求,为此我们构建了两层资源隔离体系:
第一层是基于CGroup做进程(Container)级别的CPU及内存隔离;
第二层是物理机器级别的隔离。
我们通过改造YARN的FairScheduler使其支持Node Label。达到的效果如下图所示:

普通业务的任务混跑在同一个Label机器上,而特殊业务的任务跑在专用Label的机器上。
通过集中式大集群和平台化建设,基本消除了业务方自建小集群带来的弊端,实时计算也进入了第二阶段。
伴随着业务的发展,我们发现Spark Streaming的Micro Batch模式在一些低延时的报警业务及在线业务上显得捉襟见肘。于是我们引入了基于Native Streaming模式的Flink作为新一代实时计算引擎。
Flink不仅延时可以做到毫秒级,而且提供了基于Process Time/Event Time丰富的窗口函数。基于Flink我们联合业务方构架了滴滴流量最大的业务网关监控系统,并快速支持了诸如乘客位置变化通知、轨迹异常检测等多个线上业务。
为了最大程度方便业务方开发和管理流计算任务,我们构建了如图所示的实时计算平台:
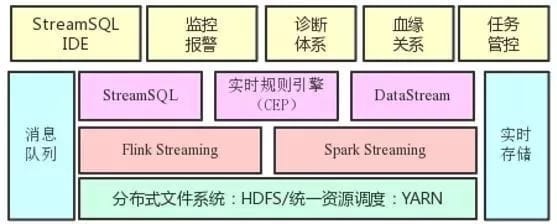
在流计算引擎基础上提供了StreamSQL IDE、监控报警、诊断体系、血缘关系、任务管控等能力。各自的作用如下:
StreamSQL IDE。下文会介绍,是一个Web化的SQL IDE;
监控报警。提供任务级的存活、延时、流量等监控以及基于监控的报警能力;
诊断体系。包括流量曲线、Checkpoint、GC、资源使用等曲线视图,以及实时日志检索能力。
血缘关系。我们在流计算引擎中内置了血缘上报能力,进而在平台上呈现流任务与上下游的血缘关系;
任务管控。实现了多租户体系下任务提交、启停、资产管理等能力。通过Web化任务提交消除了传统客户机模式,使得平台入口完全可控,内置参数及版本优化得以快速上线。
在滴滴内部有大量的实时运营场景,比如“某城市乘客冒泡后10秒没有下单”。针对这类检测事件之间依赖关系的场景,用Fink的CEP是非常合适的。
但是社区版本的CEP不支持描述语言,每个规则需要开发一个应用,同时不支持动态更新规则。为了解决这些问题,滴滴做了大量功能扩展及优化工作。功能扩展方面主要改动有:
支持wait算子。对于刚才例子中的运营规则,社区版本是表达不了的。滴滴通过增加wait算子,实现了这类需求;
支持DSL语言。基于Groovy和Aviator解析引擎,我们实现了如下图所示的DSL描述规则能力:
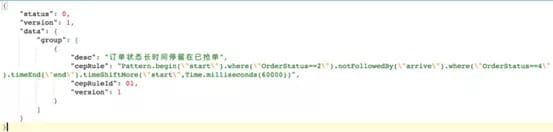
除了功能拓展之外,为了应对大规模运营规则的挑战,滴滴在CEP性能上也做了大量优化,主要有:
SharedBuffer重构。基于Flink MapState重构SharedBuffer,减少每次数据处理过程中的状态交互。同时剥离规则和用户数据极大降低每次匹配的时候从状态中反序列化的数据量;
增加访问缓存(已贡献社区)。缓存SharedBuffer数据中每次处理所需要更新的引用计数,延缓更新;
简化event time语义处理。避免key在很分散情况下每次watermark更新时要遍历所有key的数据;
复用conditionContext(已贡献社区)。减少条件查询时对partialMatch元素的反复查询。
以上优化将CEP性能提升了多个数量级。配合功能扩展,我们在滴滴内部提供了如图所示的服务模式:
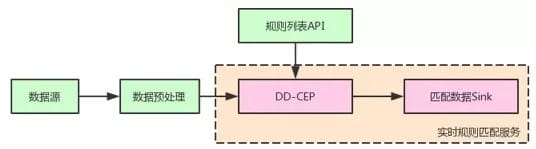
业务方只需要清洗数据并提供规则列表API即可具备负责规则的实时匹配能力。
目前滴滴CEP已经在快车个性化运营、实时异常工单检测等业务上落地,取得了良好的效果。
正如离线计算中Hive之于MapReduce一样,流式SQL也是必然的发展趋势。通过SQL化可以大幅度降低业务方开发流计算的难度,业务方不再需要学习Java/Scala,也不需要理解引擎执行细节及各类参数调优。
为此我们在2018年启动了StreamSQL建设项目,在社区Flink SQL基础上拓展了以下能力:
扩展DDL语法。如下图所示,打通了滴滴内部主流的消息队列以及实时存储系统(StreamSQL内置打通消息队列及实施存储):
通过内置常见消息格式(如json、binlog、标准日志)的解析能力,使得用户可以轻松写出DDL语法,并避免重复写格式解析语句。
拓展UDF。针对滴滴内部常见处理逻辑,内置了大量UDF,包括字符串处理、日期处理、Map对象处理、空间位置处理等。
支持分流语法。单个输入源多个输出流在滴滴内部非常常见,为此我们改造了Calcite使其支持分流语义。
支持基于TTL的join语义。传统的Window Join因为存在window边界数据突变情况,不能满足滴滴内部的需求。为此我们引入了TTL State,并基于此开发了基于TTL Join的双流join以及维表join。
StreamSQL IDE。前文提到平台化之后我们没有提供客户机,而是通过Web提交和管控任务。因此我们也相应开发了StreamSQL IDE,实现Web上开发StreamSQL,同时提供了语法检测、DEBUG、诊断等能力。
目前StreamSQL在滴滴已经成功落地,流计算开发成本得到大幅度降低。预期未来将承担80%的流计算业务量。
作为一家出行领域的互联网公司,滴滴对实时计算有天然的需求。
过去的一年多时间里,我们从零构建了集中式实时计算平台,改变了业务方自建小集群的局面。为满足低延时业务的需求,成功落地了Flink Streaming,并基于Flink构建了实时规则匹配(CEP)服务以及StreamSQL,使得流计算开发能力大幅度降低。未来将进一步拓展StreamSQL,并在批流统一、IoT、实时机器学习等领域探索和建设。
微信公众号: zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字: Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信: yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客
1、 Flink 从0到1学习 —— Apache Flink 介绍
2、 Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、 Flink 从0到1学习 —— Flink 配置文件详解
4、 Flink 从0到1学习 —— Data Source 介绍
5、 Flink 从0到1学习 —— 如何自定义 Data Source ?
6、 Flink 从0到1学习 —— Data Sink 介绍
7、 Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、 Flink 从0到1学习 —— Flink Data transformation(转换)
9、 Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、 Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、 Flink 从0到1学习 —— Flink 项目如何运行?
13、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、 Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、 Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、 Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、 Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、 Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、 Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
28、 Flink 从0到1学习 —— Flink 中如何管理配置?
29、 Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、 Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
31、 Flink 架构、原理与部署测试
32、 为什么说流处理即未来?
33、 OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
35、 Flink状态管理和容错机制介绍
36、 Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
38、 如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
40、 Flink 全网最全资源(视频、博客、PPT、入门、实战、源码解析、问答等持续更新)
42、 Flink 从0到1学习 —— 如何使用 Side Output 来分流?
4、 Flink 源码解析 —— standalone session 模式启动流程
5、 Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、 Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、 Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、 Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、 Flink 源码解析 —— 如何获取 JobGraph?
10、 Flink 源码解析 —— 如何获取 StreamGraph?
11、 Flink 源码解析 —— Flink JobManager 有什么作用?
12、 Flink 源码解析 —— Flink TaskManager 有什么作用?
13、 Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、 Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、 Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、 Flink 源码解析 —— 深度解析 Flink 序列化机制
17、 Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
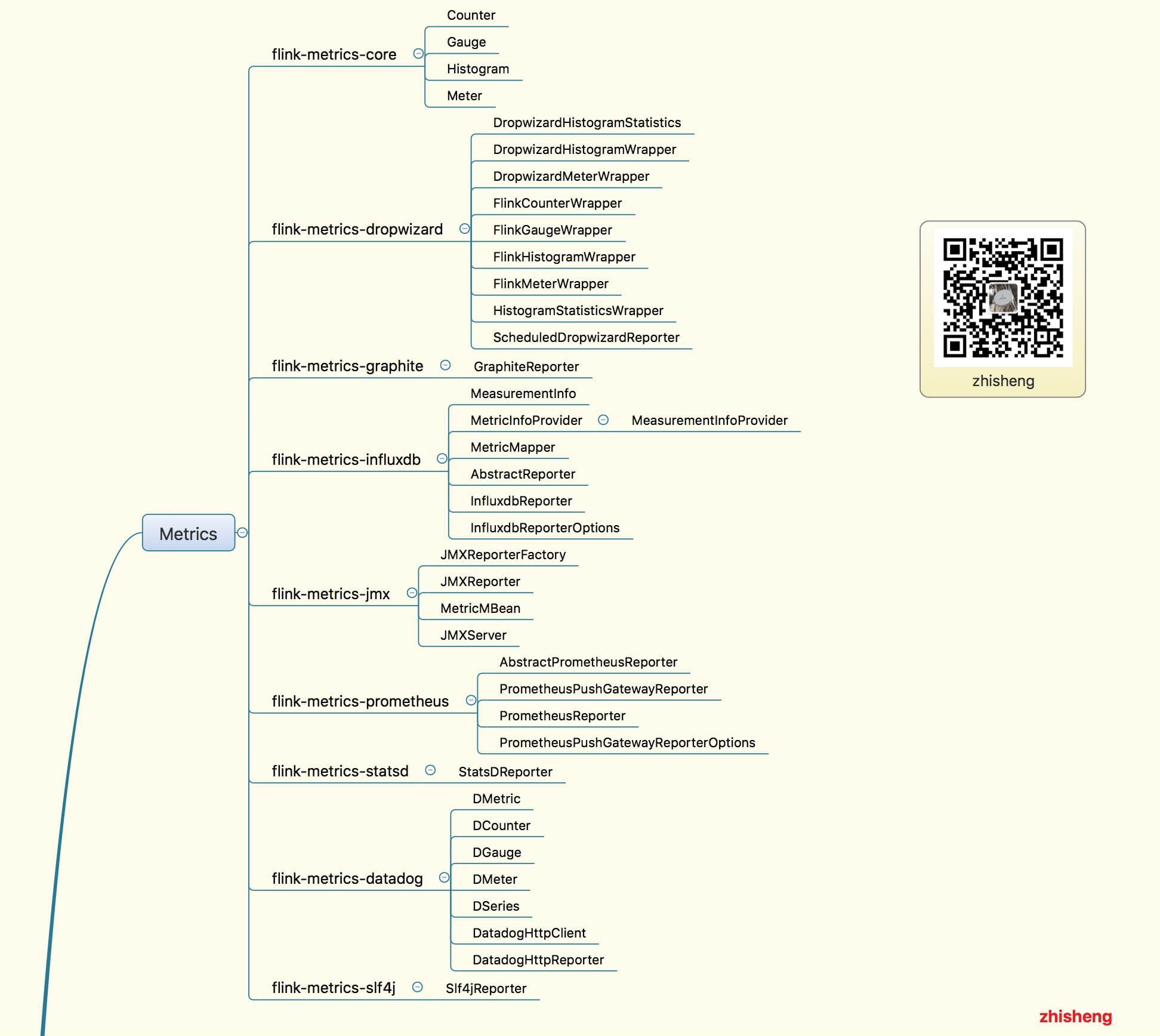
18、 Flink Metrics 源码解析 —— Flink-metrics-core
19、 Flink Metrics 源码解析 —— Flink-metrics-datadog
20、 Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、 Flink Metrics 源码解析 —— Flink-metrics-graphite
22、 Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、 Flink Metrics 源码解析 —— Flink-metrics-jmx
24、 Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、 Flink Metrics 源码解析 —— Flink-metrics-statsd
26、 Flink Metrics 源码解析 —— Flink-metrics-prometheus