背景
最近处理了几个客户的需求,需求有相似之处,解决方案迭代几次以后也具备了一定的复制性。分享出来,抛砖引玉。
需求
- 目前应用用springboot写的,以业务分块,大概形成了几十个(30+)部署单元;每个部署单元都是独立的jar,其中每个包含十个左右的endpoints
- 目前用了eureka和zuul做服务注册/发现以及负载均衡;在整体部署规模超过200个jvm之后,出现了一些问题。目前团队整体对eureka和zuul应对更大规模部署信心不足
- 目前监控主要靠zabbix,对基础设施监控效果很好;但是缺乏对服务级别的监控,包括服务可用性和服务质量
- 目前还没有部署分布式跟踪系统。尝试过,但是效果一般;实施复杂而且有侵入性
- 目前日志用ELK套件方案处理,效果不错
- 需要一个入口的网关,处理认证和访问控制的内容
- 目前服务之间的服务基本没有管控,但是随着部署的服务越来越多,有计划加强管理,包括访问控制,熔断限流等保障整体服务质量的措施
- 目前团队在调研基于容器的方案,整体效果还可以,但是容器方案都是全容器方案,对于已有服务的兼容是个问题。但是容器一定会用的;非容器的内容也一定存在
- 已经有新的功能,团队有意用非java/springboot来开发,包括go和nodejs;服务间的耦合是个新的话题
- 服务的灰度发布和复杂发布(根据客户属性,路由到指定版本的服务实例)
方案概述
方案特点
- 现有程序不用改代码就可以解决上边全部需求
- 方案兼容容器环境;可以同时支持容器+非容器环境
- 不用改造,可以实现服务间调用链的管理
- 不再依赖eureka和zuul
- 引入了promethus+grafana做了服务质量的监控、告警、服务降级处理
- 服务网关设计模式的功能主体都实现了(https://microservices.io/patterns/apigateway.html)
方案讲解
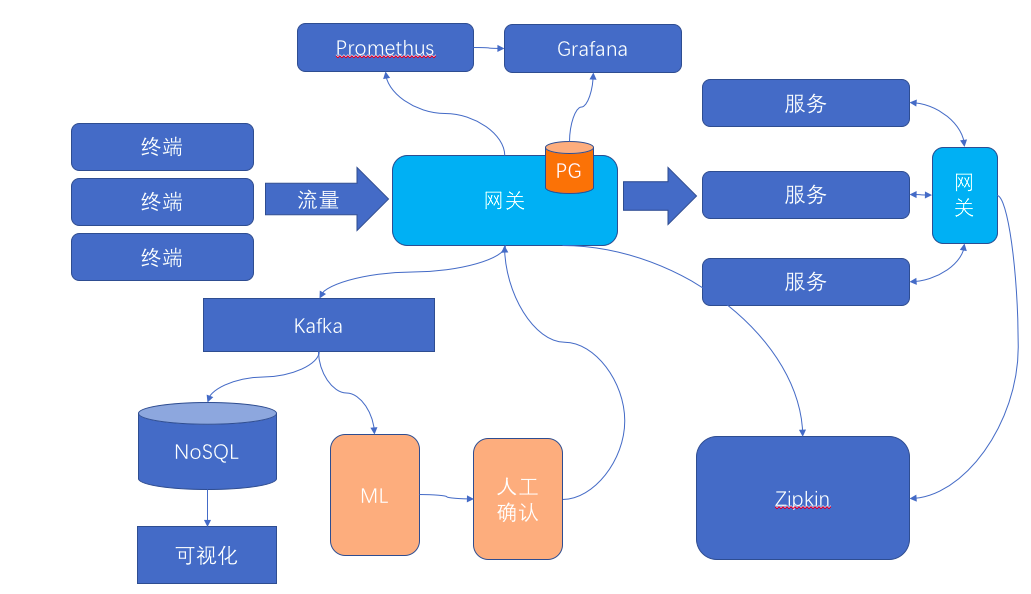
- 目前的部署单元,不改代码,但是注册eureka的地址,使用kong网关;然后在kong网关配置指向实际的eureka(现实当中是我们用kong实现了eureka的几个api)。这么做的主要因素是,kong在拦截到服务注册时候,可以动态生成路由信息(这里吐槽下,实际本来服务注册就应该和服务路由是一个事情,搞不懂spring cloud分那么多子项目有什么原因…)。简单的说,当有个一个服务的单元注册的时候,注册的信息包括这是哪个服务(spring.application.name),这个服务多了一个提供者(IP+Port),这些信息被拦截之后,动态的添加到了kong的配置里边
- 服务在调用的之前,先从eureka查询一个可以提供服务的实例,这个请求被kong拦截(拦截的技术手段是正向代理),返回给服务调用方的服务地址是kong网关地址。实际上,地址的域名和ip部分并没有意义;核心的是context,或者说uri的第一个部分,这个部分用于路由
- 之后服务调用涉及的负载均衡,由kong完成。这改变了基于eureka方案的“客户端负载均衡”的模式;不过实际效果而言,这种半集中的负载均衡方式更简单可靠
- 之后服务调用因为通过了kong,就可以实现分布式跟踪(open tracing)和服务间访问控制
- 在kong上通过插件实现了promethus的集成,和zipkin的集成,这样服务间的服务质量(延迟、响应时间、错误代码等)都可以直接获取并且和监控集成
- 整个服务平台的入口,也使用kong,这样简化了部署和管理。实测大概100~200个jvm实例需要配一个kong实例(不考虑高可用)。所以整个平台扩展到1000jvm需要也就是大概10个kong的网关
- 在kong上用插件实现了复杂的发布管理(不仅仅是蓝绿发布和灰度发布,实际需求包括根据任意的请求header路由到不同版本的相同后台服务)
- 向前兼容容器平台。实测采用openshift平台(客户目标平台是基于k8s的容器平台),不需要改变任何openshift的配置,不需要改变任何应用设置,可以支持应用上容器平台,同时可以支持容器+非容器混合使用场景(一部分服务在容器平台上,一部分服务不在容器平台上)
- 兼容非java的服务实现
意外收获
在实现客户诉求以后,通过进一步的分析和实践,我们得到了一些“意外收获”:
- 之前客户希望实现比“服务”更细力度的管理(可以认为是endpoint,或者我们叫做“API级别”),包括统计数据,包括服务质量和管控。在实施了这个方案之后,我们动态的获取了“服务以下”(就是uri里边第一个路径之后的内容)的统计数据,然后动态的添加了kong的路由,基本实现了这个目的。目前可以实现API级别的统计信息收集和管理
- 服务调用拓扑的获得。客户开发团队很复杂,水平不尽相同,服务在开发时候很难通过管理手段约束服务定义。通过逆向方式整理出服务的端点和服务拓扑解决了客户的实际痛点
下一步
在实现了这些以后,还是有很大空间可以提升的,眼前看到的包括:
- 我们通过网关,收集了全量的访问数据。目前这些数据被用于“恶意访问”的识别,这种结合机器学习的流量管控手段,可以看成是WAF一些功能点的升级版
- 进一步收敛部署和维护的复杂度。在数据存储和集成方面,还有空间可以做,这里细节很多,不多说了
方案对比
客户也要求我们对比几种他们感兴趣的方案,我们自己也在实施前内部对比和比较过一些细节问题处理,稍微总结一下:
- 全容器平台。客户计划实施全容器平台,但是仍然有无法容器化的内容。容器是趋势,但是如何过度,是方案的难点之一。在考察过几个容器平台之后,我们作出选择用目前方案。最核心的原因:1. 在没确认捡起来的是西瓜之前,抱着西瓜捡西瓜总比丢了西瓜捡芝麻强;2. 高度集成的容器平台并不太现实,针对分布式/微服务的纯商业产品的解决方案已经跟不上时代发展(其实也没有可以拿出手的商业产品);3. 定制化,细节的定制化,往往可以要了一个方案的命;好的方案一定是核心紧凑、简介,充分性留给定制化,而定制化一定要可控和有效,那种差不多重写整个产品的方案失败是在所难免的
- istio。我们最纠结的就是是否通过istio满足客户需求。在纠结了半年之后,作出放弃istio的选择还是很艰难的。尽量客观的描述下理由:1. istio刚GA,客户和我们都没有充分信心用这个,在这个时候;2. istio蛮复杂的,现实问题的复杂度和解决方案的复杂度之间的平衡点,是我们最关心的,从描述看istio可以解决各种问题,但是真的缺乏实践作为支撑,需求复杂度和产品简洁之间的沟就是团队成功的关键;3. istio绑定了k8s,尽管参与者都认可k8s,但是绑定怎么说都还是一种风险
- 公有云。实际这个问题不太具有典型性,有客户从开始就提出要求适用私有数据中心和公有云。简单的回答下这个问题:目前公有云优势明显,但是锁定性还是很强的。目前的方案,既可以适配各种公有云,也可以满足混合环境(多云和公有+私有)的使用诉求