Apache Flink OLAP引擎性能优化及应用
- - InfoQ推荐导读:本次分享的主题为Apache Flink新场景——OLAP引擎,主要内容包括:. Apache Flink OLAP引擎. OLAP是一种让用户可以用从不同视角方便快捷的分析数据的计算方法. 主流的OLAP可以分为3类:多维OLAP ( Multi-dimensional OLAP )、关系型OLAP ( Relational OLAP ) 和混合OLAP ( Hybrid OLAP ) 三大类.
导读:本次分享的主题为Apache Flink新场景——OLAP引擎,主要内容包括:

OLAP是一种让用户可以用从不同视角方便快捷的分析数据的计算方法。主流的OLAP可以分为3类:多维OLAP ( Multi-dimensional OLAP )、关系型OLAP ( Relational OLAP ) 和混合OLAP ( Hybrid OLAP ) 三大类。
多维OLAP ( MOLAP ):
关系型OLAP ( ROLAP ):
混合OLAP ( HOLAP ):
接下来为大家详细介绍下:
① MOLAP
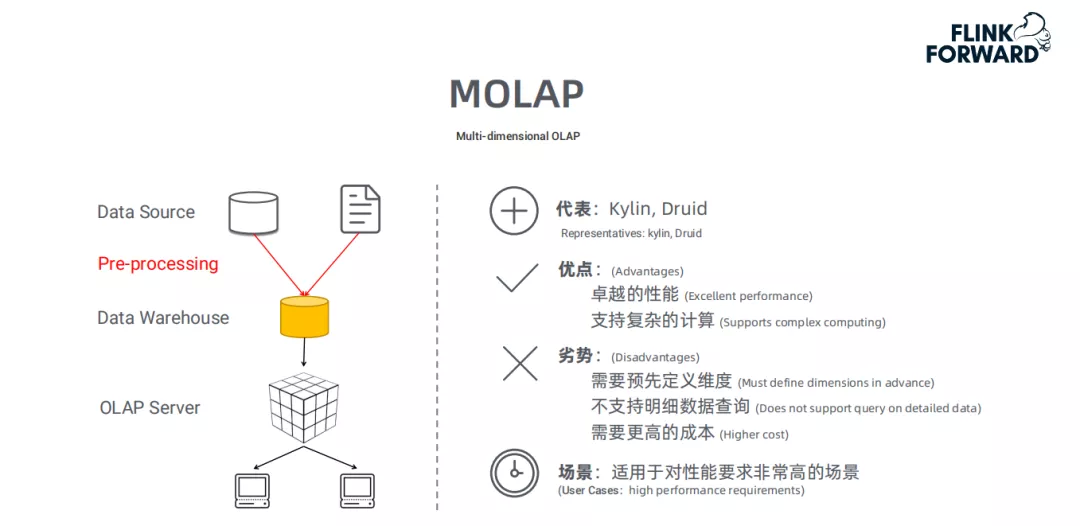
典型代表:
MOLAP的典型代表是Kylin和Druid。
处理流程:
MOLAP的优点和缺点:
MOLAP的优点和缺点都来自于其数据预处理 ( pre-processing ) 环节。数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的临时计算,提升了查询性能,同时也为很多复杂的计算提供了支持。
但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询。
因此,MOLAP适用于对性能非常高的场景。
② ROLAP
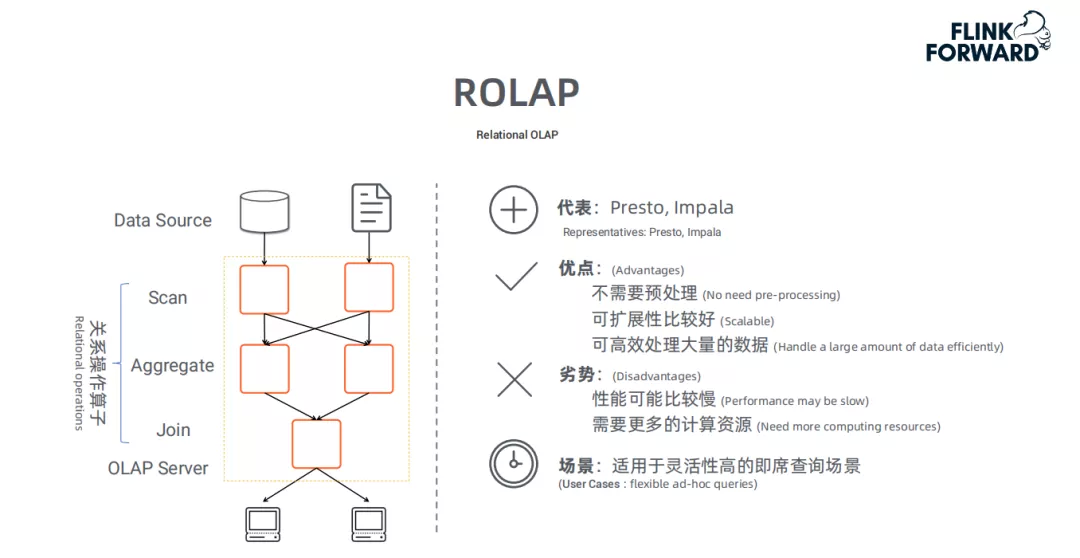
典型代表:
ROLAP的典型代表是Presto和Impala。
处理流程:
ROLAP的优点和缺点:
ROLAP不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用MPP架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。但是当数据量较大或query较为复杂时,查询性能也无法像MOLAP那样稳定。所有计算都是临时发生 ( 没有预处理 ),因此会耗费更多的计算资源。
因此,ROLAP适用于对查询灵活性高的场景。
③ HOLAP
混合OLAP,是MOLAP和ROLAP的一种融合。当查询聚合性数据的时候,使用MOLAP技术;当查询明细数据时,使用ROLAP技术。在给定使用场景的前提下,以达到查询性能的最优化。
① 当前Apache Flink支持的应用场景
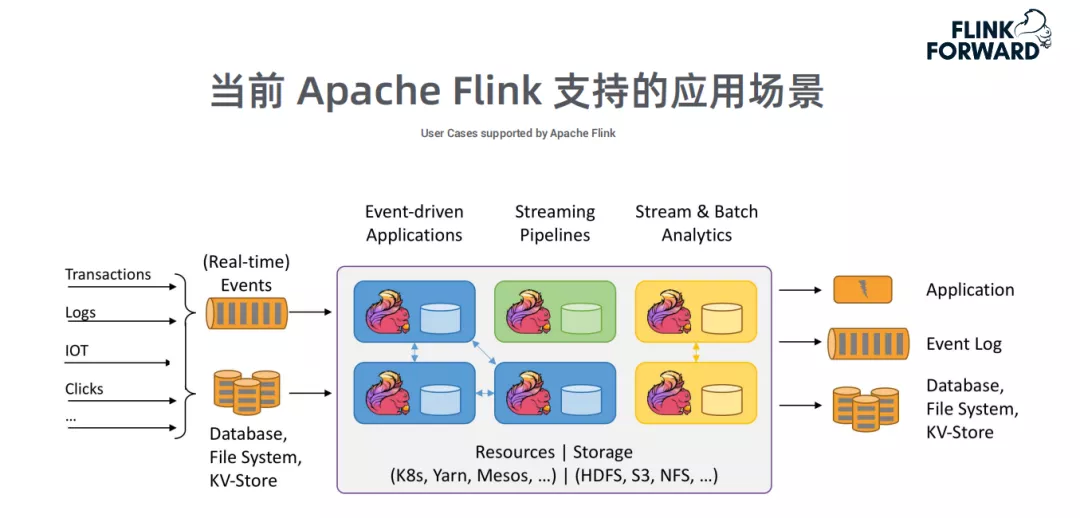
Apache Flink支持的3种典型应用场景:
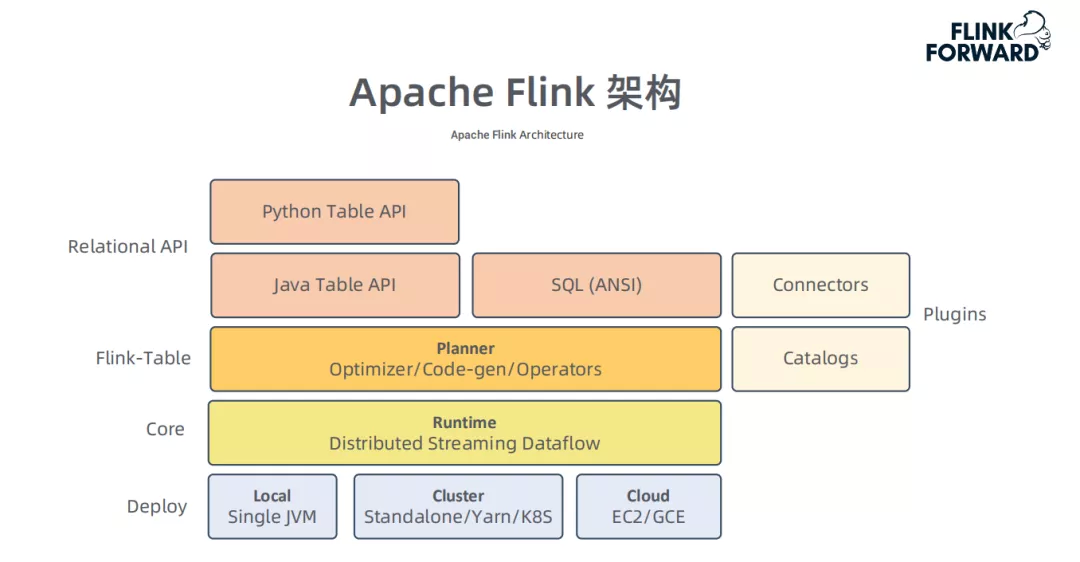
② Apache Flink 架构
③ Apache Flink 优势

① 为什么Apache Flink 可以做ROLAP引擎?
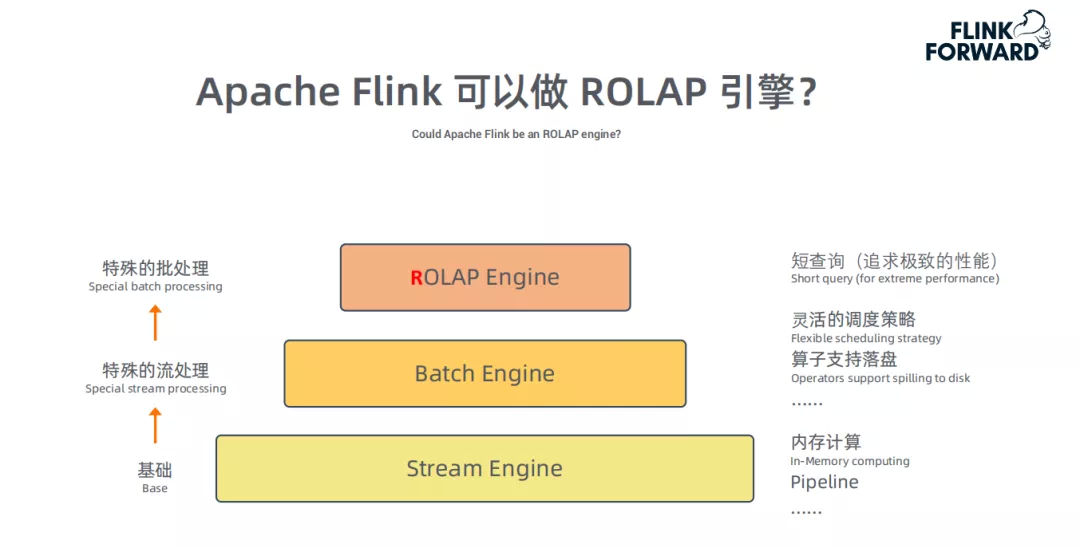
注:Flink OLAP引擎目前不带存储,只是一个计算框架
② Apache Flink 做OLAP引擎的优势
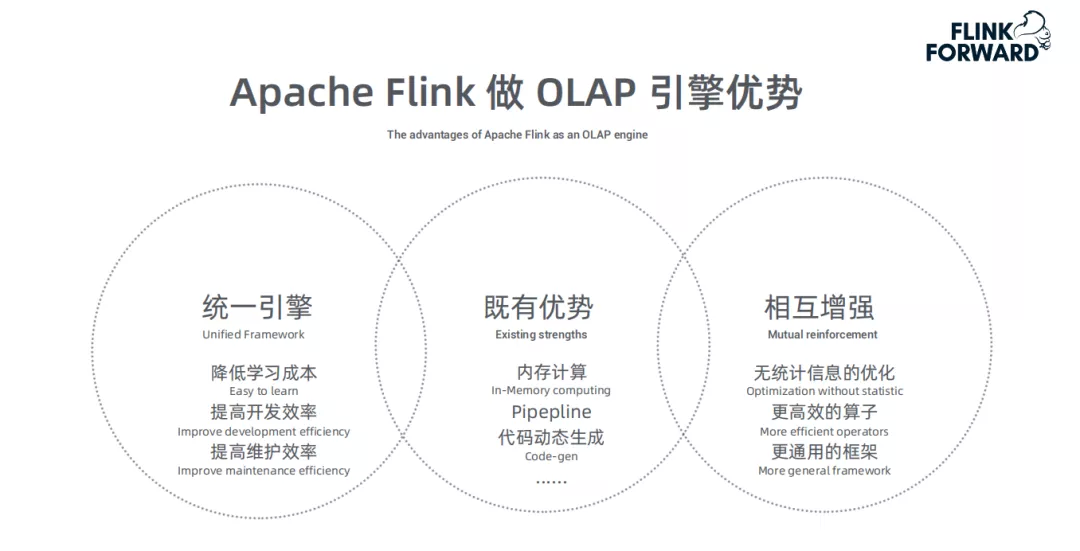
统一引擎:流处理、批处理、OLAP统一使用Flink引擎
既有优势:利用Flink已有的很多特性,使OLAP使用场景更为广泛
相互增强:OLAP能享有现有引擎的优势,同时也能增强引擎能力
OLAP 对查询时间非常敏感,当前很多组件的性能不满足要求,因此我们对Flink做了很多相关优化。
① 服务架构的优化
客户端服务化:
下图介绍了一条SQL怎么在客户端一步一步变为JobGraph,最终提交给JM:
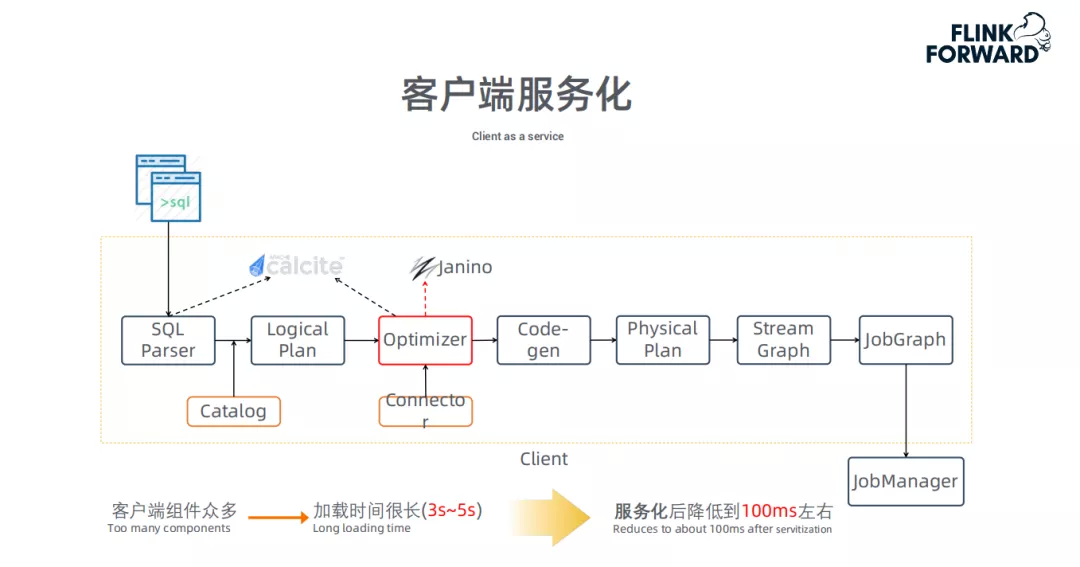
在改动之前,每次接受一个query时会启动一个新的JVM进程来进行作业的编译。其中JVM的启动、Class的加载、代码的动态编译 ( 如Optimizer模块由于需要通过Janino动态编译进行cost计算 ) 等操作都非常耗时 ( 需要约3~5s )。因此,我们将客户端进行服务化,将整个Client做成Service,当接收到用户的query时,无需重复各项加载工作,可将延时降低至100ms 左右。
自定义CollectionTableSink:
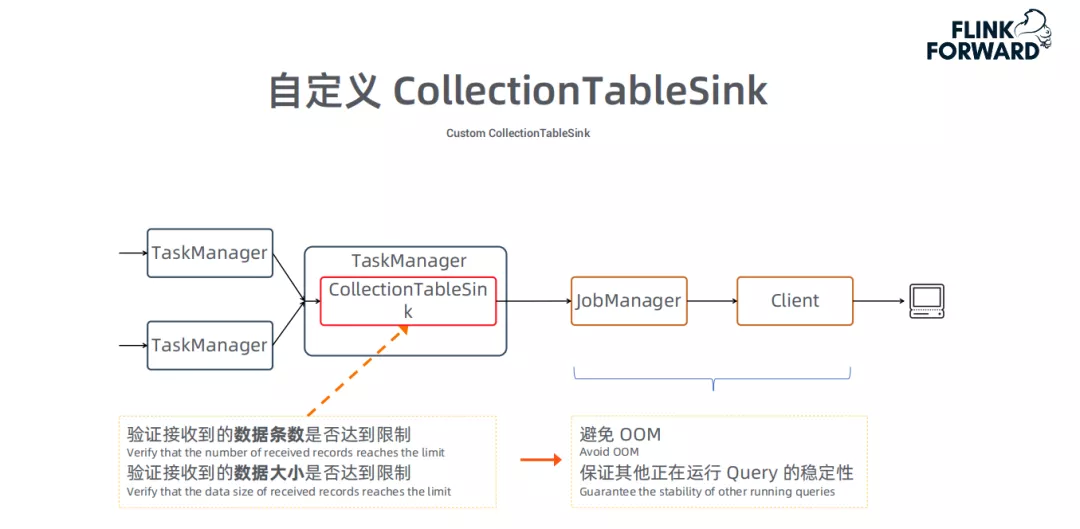
这部分优化,源于OLAP的一个特性:OLAP会将最终计算结果发给客户端,通过JobManager转发给Client。假如某个query的结果数据量很大,会让JobManager OOM ( OutOfMemory );如果同时执行多个query,也会相互影响。因此,我们从新实现了一个CollectionTableSink,限制数据的条数和数据大小,避免出现OOM,保证多个Query同时运行时的稳定性。
调度优化:
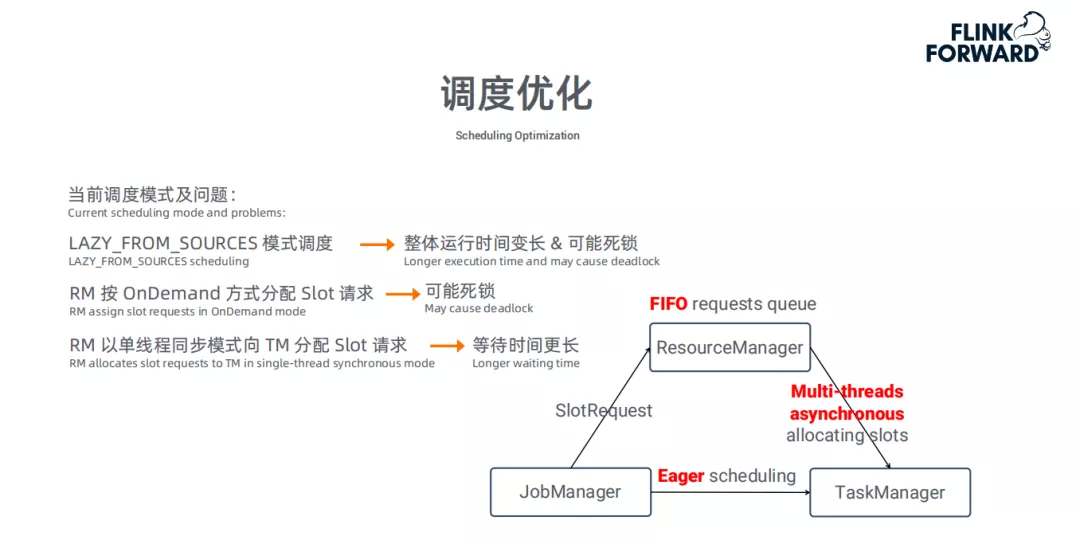
在Batch模式下的调度存在以下问题:
使用Lazy_from_sources模式调度,会导致整体运行时间较长,也可能造成死锁。
注:调度死锁是指在资源有限的情况下,多个Job同时运行时,如果多个Job都只申请到了部分资源并没有剩余资源可以申请,导致Job没法继续执行,新的Job也没法提交
RM ( Resource Manager ) 按OnDemand方式分配Slot需求,也会造成死锁
RM以单线程同步模式向TM ( Transaction Manager ) 分配Slot请求,会造成等待时间更长。
针对上述问题,我们提出了以下几点改动:
② 针对source的优化
在ROLAP的执行场景中,所有数据都是通过扫描原始数据表后进行处理;因此,基于Source的读取性能非常关键,直接影响Job的执行效率。
Project&Filter下堆:
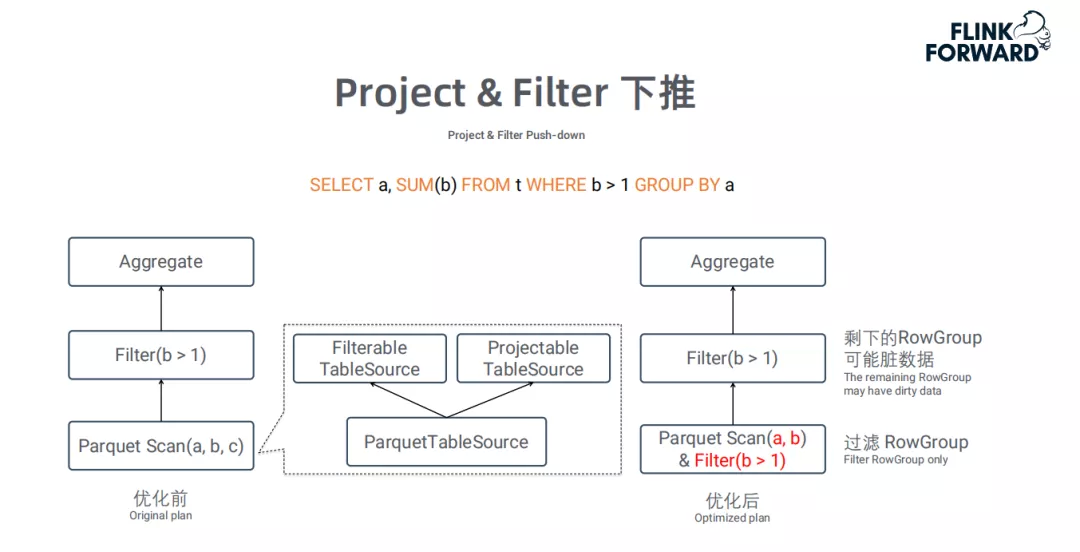
像Parquet这类的列存文件格式,支持按需读取相所需列,同时支持RowGroup级别的过滤。利用该特性,可以将Project和Filter下推到TableSource,从而只需要扫描Query中涉及的字段和满足条件的RowGroup,大大提升读取效率。
Aggregate下堆:
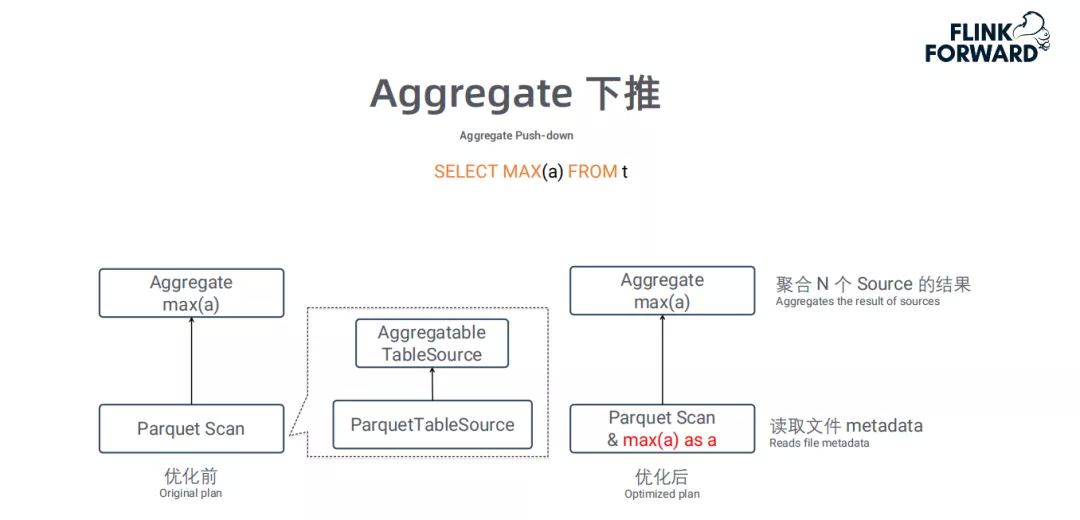
这个优化也是充分利用了TableSource的特性:例如Parquet文件的metadata中已经存储了每个RowGroup的统计信息 ( 如 max、min等 ),因此在做max、min这类聚合统计时,可直接读取metadata信息,而不需要先读取所有原始数据再计算。
③ 在没有统计信息场景下做的优化
消除CrossJoin:
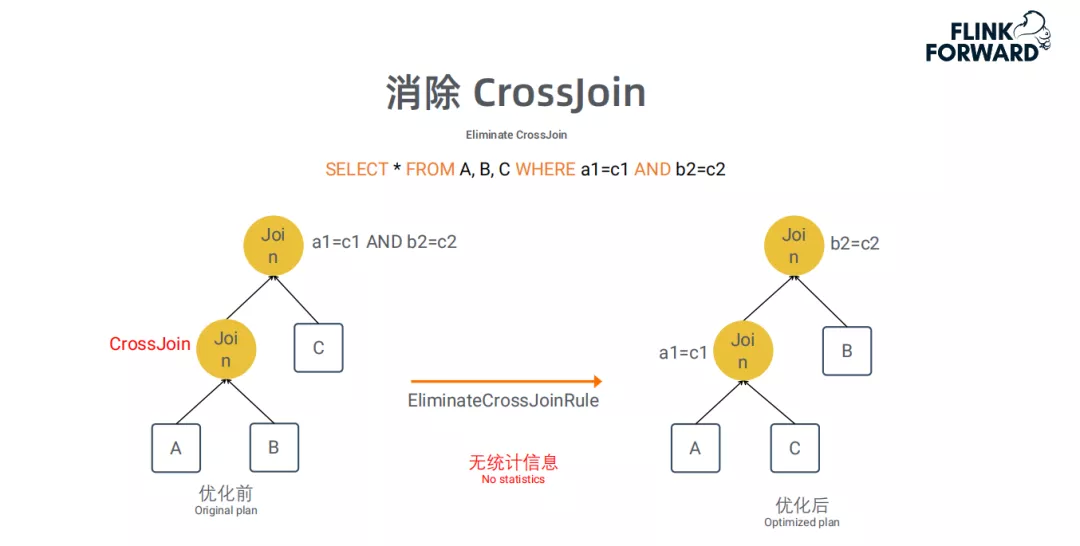
CrossJoin是没有任何Join条件,将Join的两张表的数据做笛卡尔积,导致Join的结果膨胀非常厉害,这类Join应该尽量避免。我们对含有CrossJoin的Plan进行改写:将有join条件的表格先做join ( 通常会因为一些数据Join不上而减少数据 ),从而提高执行效率。这是一个确定性的改写,即使在没有统计信息的情况下,也可以使用该优化。
自适应的Local Aggregate:
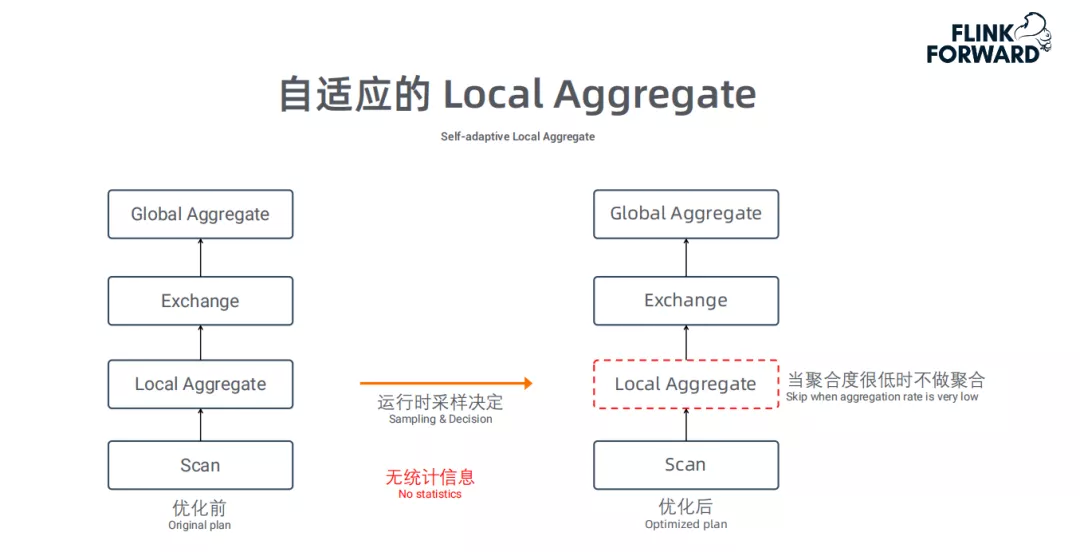
通常情况下,两阶段的Aggregate是非常高效的,因为LocalAggregate能聚合大量数据,导致Shuffle的数据量会变少。但是当LocalAggregate的聚合度很低的时候, Local聚合操作的意义不大,反而会浪费CPU。在没有任何统计信息的情况下,优化器没法决定是否要产生LocalAggregate算子;因此,我们采用运行时采样的方式来判断聚合度,如果聚合度低于设定的阈值,我们将关闭聚合操作,改为仅做数据转发;经我们测试,部分场景有30% 的性能提升。
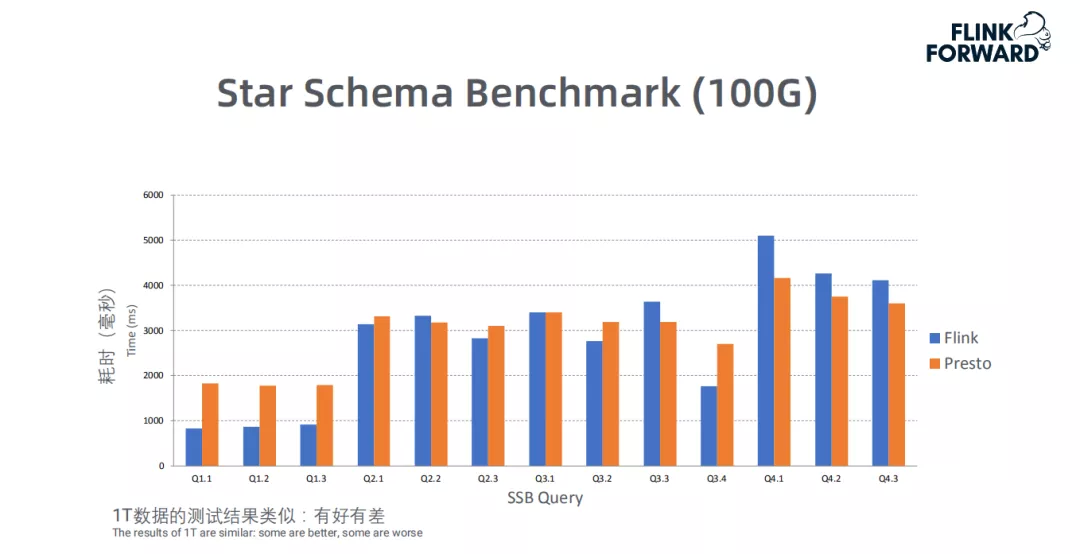
上图是Flink和Presto基于1T数据做的SSB ( Star Schema Benchmark ) 测试,从图中可以看出 Flink和Presto整体上不相上下,甚至有些Query Flink性能优于Presto。注:Flink OLAP从开始到嘉宾分享时,只有3个月时间。
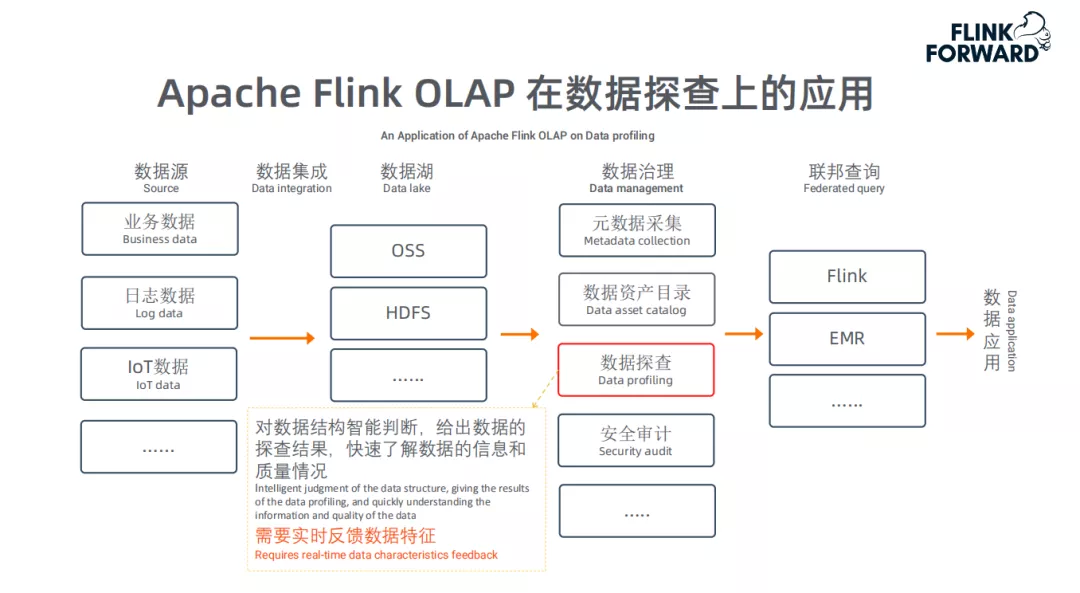
上图描述了一个数据湖应用的完整架构,Flink OLAP主要用于"数据探查"。数据探查是对数据结构做智能判断,给出数据的探查结果,快速了解数据的信息和质量情况。即用户可以在管控平台上了解数据湖中任意一份数据的数据特性。用户通过Web交互操作选择相应的表和指标后立即展示相关结果指标,因此要求低延迟、实时反馈。而且数据湖中很多数据没有任何统计信息;前述的各种查询、聚合层面的优化,主要为这类场景服务。
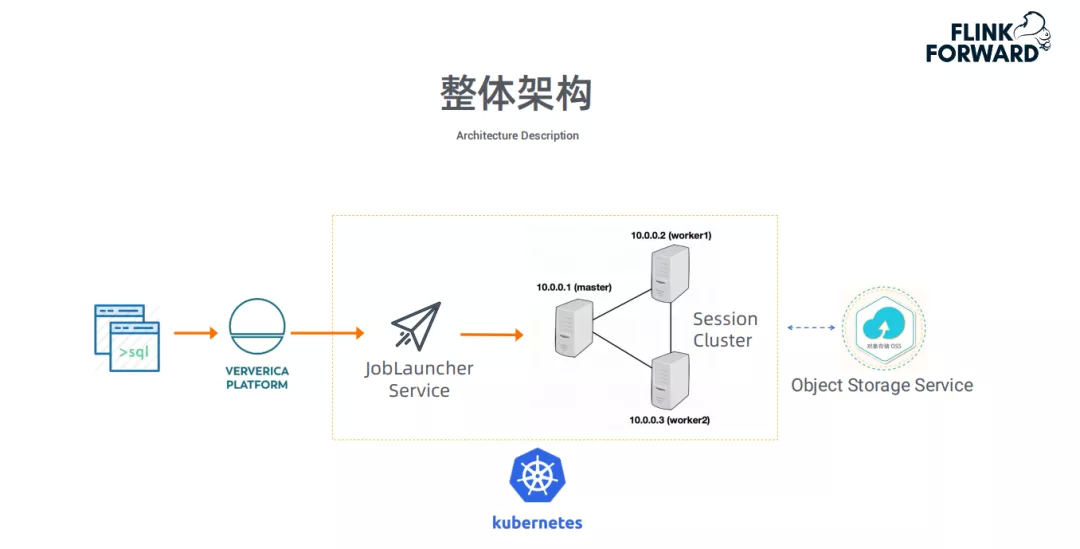
上图是这类应用的整体架构。整套服务托管到Kubernetes上,最终访问的数据是OSS;目前这套架构正在阿里云上做公测,邀请广大用户试用。
本次的分享就到这里,谢谢大家。
本文来自 DataFunTalk
原文链接: