


全链路压测体系建设方案的思考与实践
- - IT瘾-dev日前杭州笨马CTO童庭坚接受了软件质量效能社区的邀请,与行业同仁分享了关于全链路压测体系建设方案的思考与实践. 在金融、零售快消、物流、新能源等传统行业,通常都会有一个相对独立的测试团队,其中包括了性能测试. 过去性能测试通常是开发自测、或以项目需求驱动的方式实施,也就是根据需求在测试环境验证相应的性能目标,出具性能验收报告后就算结束.
日前杭州笨马CTO童庭坚接受了软件质量效能社区的邀请,与行业同仁分享了关于全链路压测体系建设方案的思考与实践。以下为本场直播的核心内容:
在金融、零售快消、物流、新能源等传统行业,通常都会有一个相对独立的测试团队,其中包括了性能测试。
过去性能测试通常是开发自测、或以项目需求驱动的方式实施,也就是根据需求在测试环境验证相应的性能目标,出具性能验收报告后就算结束。但随着业务系统的迭代速度不断加快,这种做法也会存在诸多不足:
首先,测试环境得出的测试结果,可以验证程序级问题,但因环境和数据的差异,无法验证或获得业务系统在生产环境的性能指标。
其次,随着业务需求变更的频率不断加快,发布周期随之缩短,很多紧急项目直接跳过性能测试就上生产。也造就了一个行业误区:功能一定要测,性能可以不测。举个例子,比如说变更数据库连接数则是一个反例。
第三,据了解过的大多企业,为了生产系统的安全,日常水位很低,比如CPU利用率不到10%,高峰时期可能达到20%。之所以资源利用率低,也是因为对生产容量的不确定性所造成。
另外,以项目需求驱动测试的做法,测试结果将会是数据孤岛,很难做到可持续的性能基线跟踪和风险识别,容易引发累积雪崩性问题。
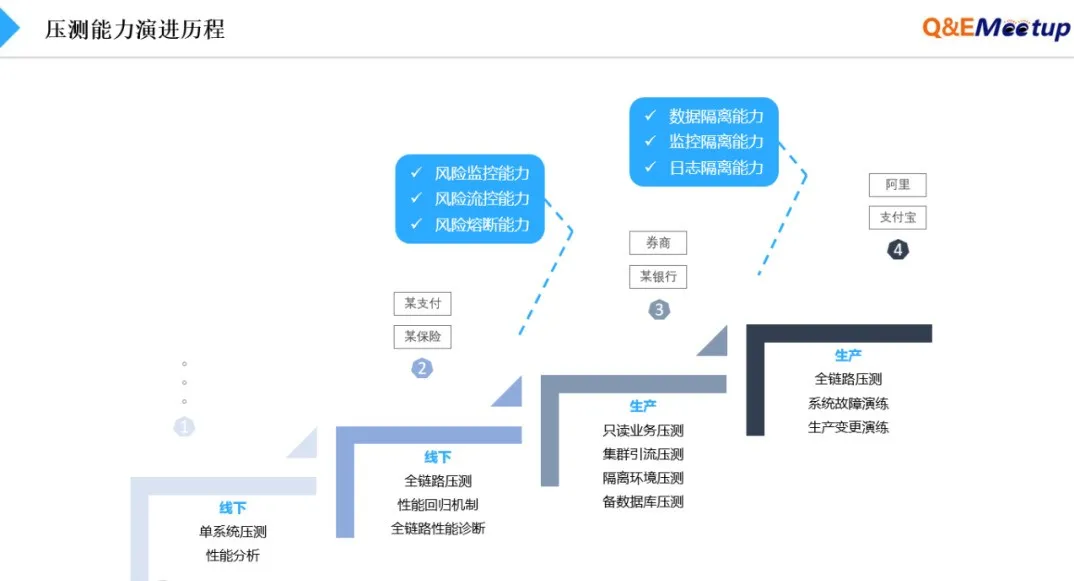
目前业内并没有针对性能评测的成熟度的评估模型,根据过往的行业实践经验,大致可将其定位为五个阶段。
第一阶段,以开发自测为主,初创型企业在该阶段居多,没有独立的性能测试团队,系统开发完成后,开发人员自行用开源工具针对核心接口进行压测,缺乏专业的测试方法。
第二阶段,以项目需求驱动为主,测试团队被动领活干,测试团队基于项目需求设计测试场景对被测系统进行相应评测,测试需求与测试目标大多依赖人工评审。
第三阶段,以瀑布模式为主,拥有独立的性能测试团队,并制定统一的的性能准入/准出标准和规范,通过组织形式推广整个IT部门,实施规范化的性能测试验收过程。
第四阶段,化被动为主动,用平台化方式对关键业务变更形成一套完整的性能回归体系,打通持续集成,依托迭代性能评测数据建立可持续的性能基线跟踪机制,识别频繁迭代变更带来的性能隐患。
第五阶段,测试左右赋能,向左赋能于研发,提前识别潜在性能风险,向右赋能于运维,为生产容量、稳定性提供有效保障手段。
从最初的线下单系统、单模块以及短链路压测,转变为生产全链路压测。
最早在蚂蚁金服,压力测试是在测试环境进行,且是针对一些重点项目,比如余额宝、花呗、借呗等明星型项目,由于项目的重要性,将会由专职的性能测试专家介入参与评估。后由于公司的核心业务日益增多,逐步开始在测试环境进行迭代变更回归测试,并形成多版本性能对比评估机制。这种测试手段,难以用测试环境得出的结果推导生产真实容量。
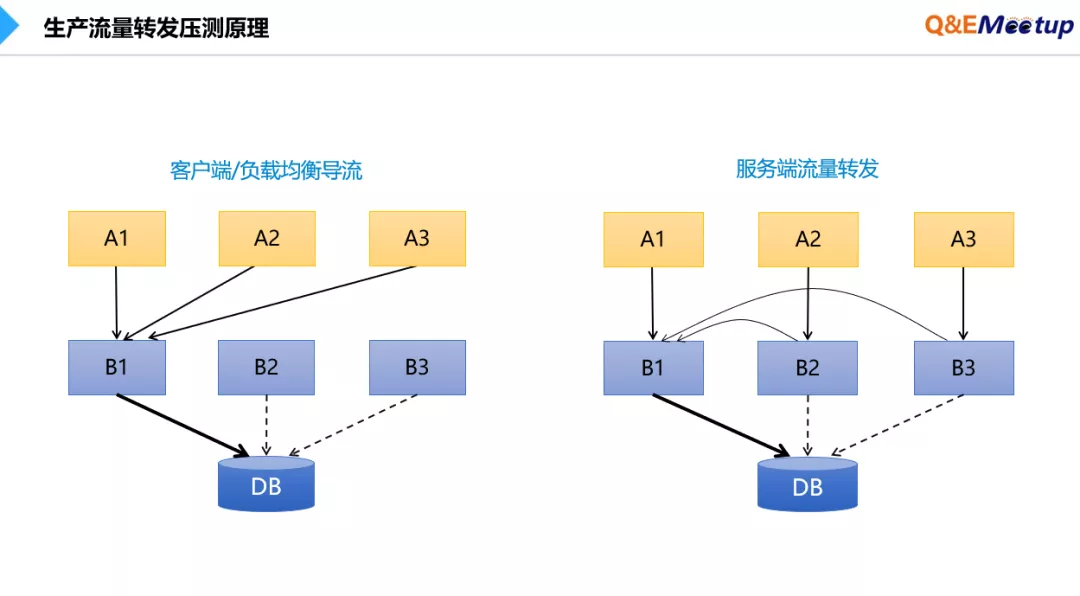
随着业务量的不断增长,考虑到线下测试结果的准确性,开始尝试生产压测,这种压测手段,我们称之为引流压测。事实上没有真正的模拟放大压力进行测试,而是一种通过缩小在线服务集群数的方式来放大单机处理量。比如一个业务系统的集群有100个节点,将其中90个节点模拟下线或转发流量到剩余的10个节点上实施压测,如图所示。
引流压测的弊端在于,DB承受压力不变,上下游系统的压力不变。压测结果仅能代表单个应用的性能,但往往无法识别链路和架构级的隐患,而且在引流过程中倘若出现异常或突如其来的业务高峰,很容易造成生产故障。
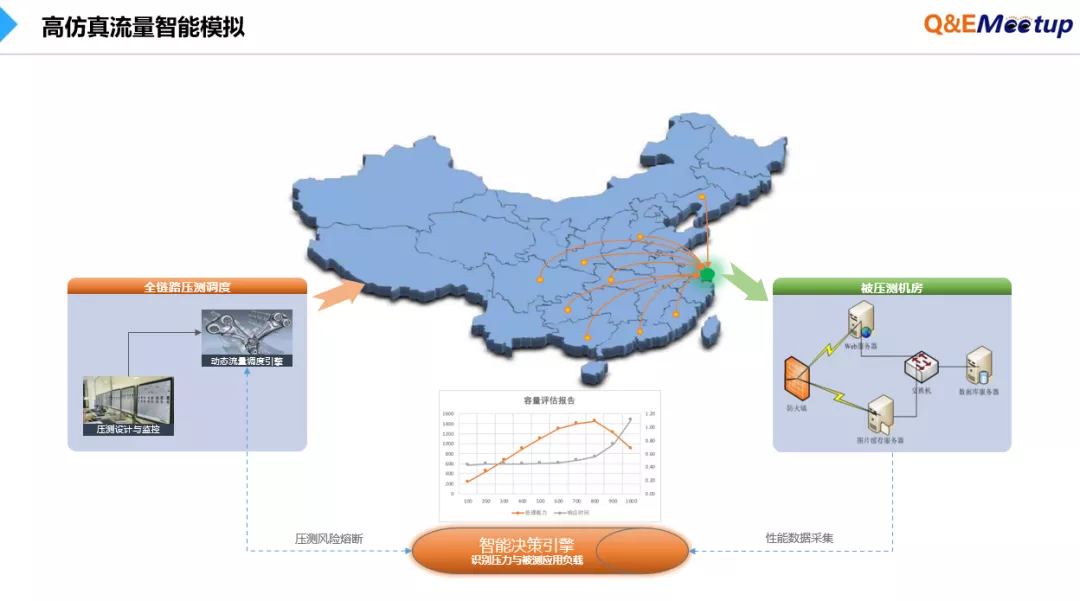
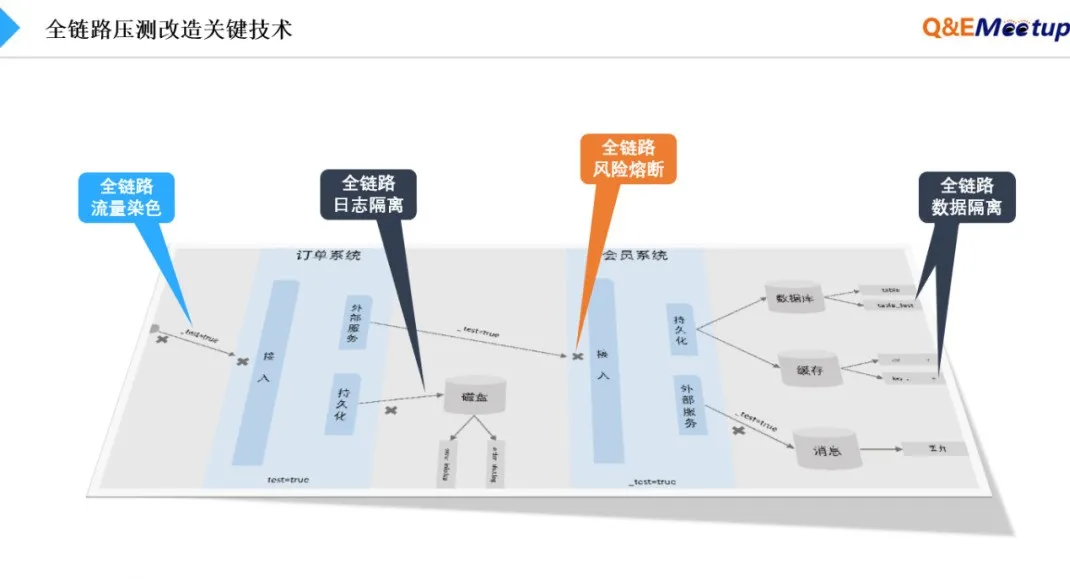
随着压测技术和手段的不断演进,在2014年初,全链路压测的方法开始诞生,其目标是希望在大型促销活动来临前,可以在生产环境上模拟路演进行验证整体容量和稳定性。由此,出现了全链路压测方法所涉及的公网多地域流量模拟、全链路流量染色、全链路数据隔离、全链路日志隔离、全链路风险熔断等关键技术。
多地域流量模拟技术是指,通过全国各地CDN节点模拟向生产系统施加压力,并在压测过程中对生产系统健康度进行实时监控,快速识别压测对生产业务带来的风险,立即作出流量调节或熔断决策。
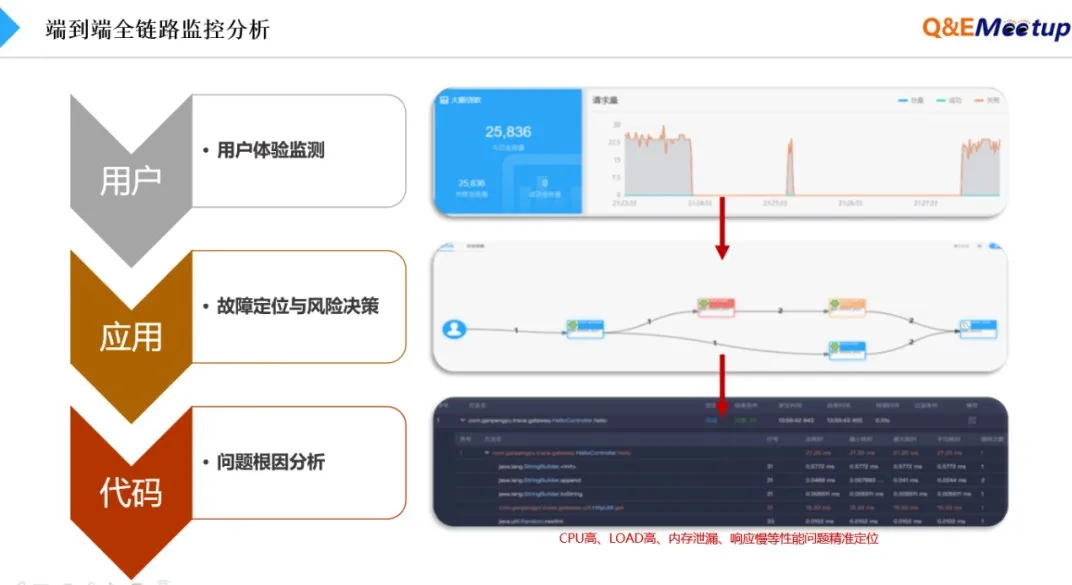
全链路的监控和分析包括三个层面。第一层是用户体验监测,在云压测平台中可以看到用户的感受,比如响应时间是否随着压力的加大而变长。假如耗时突增引发业务下跌,我们将进入第二层监控,快速从用户体验侧下钻到生产系统后端链路,并快速识别出现问题的服务节点或接口。
依托于以上监控信息,需要利用相关分析能力快速给出应急决策依据,比如通过重启解决会有何影响?同时,在故障发生过程中,分析系统将会保留现场,也会继续下钻到第三层分析,比如深度追踪某个接口或方法中的所有执行逻辑耗时,再比如为什么CPU会突然暴增、GC暂停时间长等。
三层分析能力的结合和联动,比传统APM相关技术监控粒度更深,同时具备分析和优化建议能力。同时,在生产环境的变更灰度、故障演练也都可以依托于压测流量进行,这样降低在生产流量下直接演练的风险。
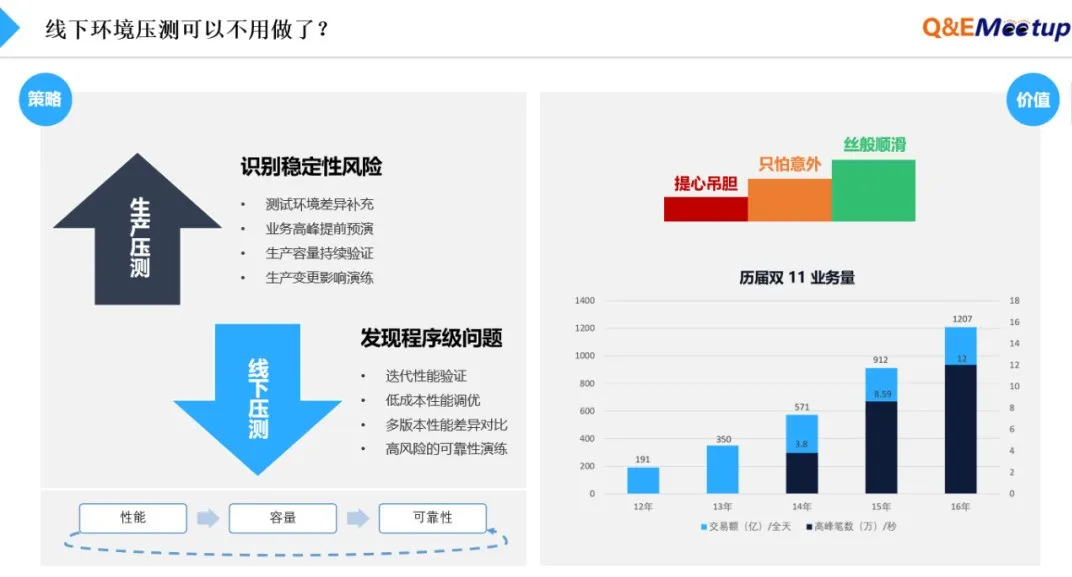
这一点,值得特别提出,2015年我们曾犯过一个错误:有了生产压测,线下压测基本不做了,就因为这种心态,导致:
很多程序变更所引起的一些基本的程序级问题没有得到验证。
导致生产压测过程中频繁出现故障。
因此,我们又重新把线下回归体系捡了起来,甚至花了较大精力去完善这个线下回归体系。
总而言之,线下压测是无风险发现程序级问题,线上压测是低风险实现线下补足和评估生产的容量。
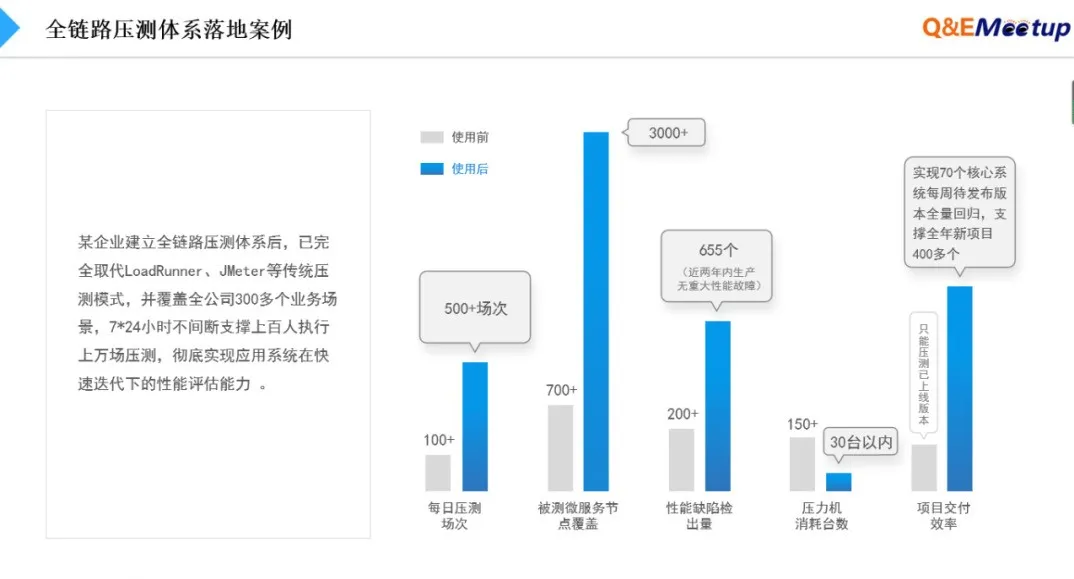
我们有个合作企业“性能评测体系建设”的案例:这个企业一开始属于前面讲过的成熟度阶段的5级中的第2-3级,每年大概有200个左右的项目,团队大,有几十个性能测试人员,回归业务量非常大,迭代周期是双周,当时用户最大的挑战是测试需求量大导致人力投入大,并且无法在发布前完成评测工作。在合作后,一方面依托平台化能力,另一方面优化组织协同模式、规范化、体系化,在为期不到半年时间组织能效提升4-6倍,同时一定程度上提升了压测环境资源的利用率,降低资源投入成本。
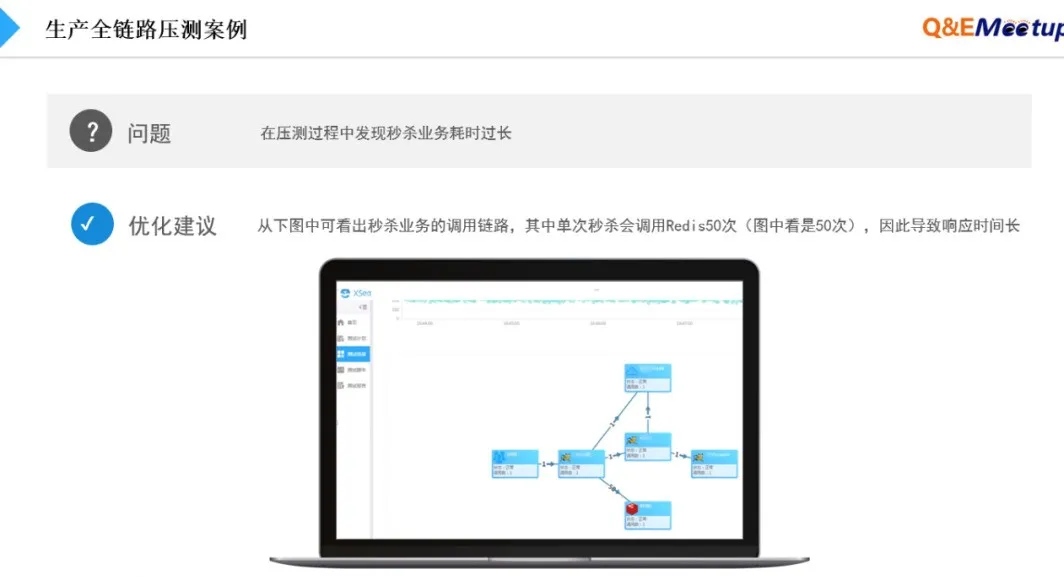
另外,还有一个生产全链路压测的案例:在为一个企业实施生产压测时,偶发性出现用户相应很慢,通过全链路下钻深度分析,发现这些特定的用户访问时,Redis调用非常频繁,当特定用户集中访问时,整个Redis达到容量瓶颈,最终影响到所有用户。
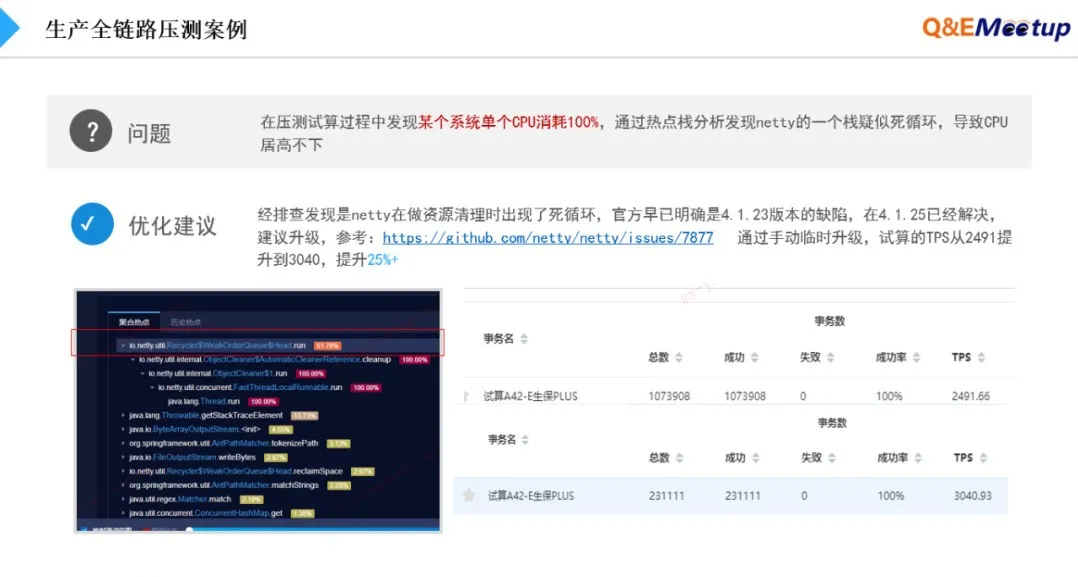
最后,我们再举一个因开源组件BUG导致的CPU使用暴增引发的故障。在一次压测过程中,我们发现一个服务节点上的某个CPU消耗100%,我们利用平台的深度热点方法分析能力,发现CPU利用率排在第一的方法是通讯框架Netty的内存清理逻辑。经排查,发现是Netty的BUG(高并发下出现死循环),我们本想修复,后发现在其官方4.1.25版本已修复,升级后CPU占满的情况完全消退。最终不仅解决了CPU利用率高的问题,业务的TPS也从2491提升到3040。
第一,不能有了生产全链路压测就不做线下压测;
第二,不是有了生产影子表能力,就可以在生产随意实施压测。比如日志也需要隔离,如果生产日志和测试日志混为一体,将会影响大数据分析(如用户行为分析)。同时生产压测本身是高风险的行为,所以压测前中后的生产稳定性风险防控能力也至关重要。
本次分享到这里,期待后续有更多机会和大家分享整套技术方案和体系化落地细节。