网易分布式数据库多活架构的演进与实践
- -大家好,今天给大家分享一些网易近几年在数据库多活方向上的工作. 我将简单介绍下为什么我们要做数据库多活,再从三个阶段介绍网易在数据库多活上做的工作. 数据库多活的目标包括“容灾”和“提升处理能力”两方面. 容灾可以简单理解为当系统由于外部或内部原因出现部分不可用时,仍然能在短时间内恢复可用. 而容灾最常用的手段即是备份,在数据库领域不仅需要对计算能力做备份也要对数据做备份.
大家好,今天给大家分享一些网易近几年在数据库多活方向上的工作。
我将简单介绍下为什么我们要做数据库多活,再从三个阶段介绍网易在数据库多活上做的工作。

一、数据库多活的目标
数据库多活的目标包括“容灾”和“提升处理能力”两方面。
容灾可以简单理解为当系统由于外部或内部原因出现部分不可用时,仍然能在短时间内恢复可用。而容灾最常用的手段即是备份,在数据库领域不仅需要对计算能力做备份也要对数据做备份。容灾级别可以划分为宿主机级别的容灾、机房级别的容灾和跨城的容灾。
要提升数据库的处理能力,一般有读写分离和单元化两种方式,读写分离将数据库的备份节点的读能力提供出来,其实提升了系统的利用率,而单元化则是当整个机房的资源无法容纳业务的增长时,加入更多的机房资源,扩展业务的处理能力的方法。

二、网易的产品特性
网易成立23年以来,孵化了大量的产品,不同的产品特性、产品发展到不同阶段对数据库多活都有不一样的需求。

像音乐、新闻这类的泛娱乐产品,它们每日要处理大量的请求,同时也会产生大量的数据,而由于其产品的独特性,它们对数据的一致性要求往往不是特别高,但对可用性要求比较高。
而严选这样的电商类应用,由于其独有的交易类数据,对数据一致性要求是比较高的,流量一般小于娱乐性应用,对可用性同样很高。
而最为极端的支付类应用,由于所有的业务都和钱挂钩,对数据一致性要求极高,流量反而最小,可用性要求同样很高。
对一致性要求的不同会导致不同的产品在选择数据库多活方案时有不一样的选择,而互联网产品对可用性的要求往往是一致的,都无法接受产品长时间不可用。
三、网易数据库使用现状
我从DBA同事那边要到了一份网易当前的数据库选型分布数据。
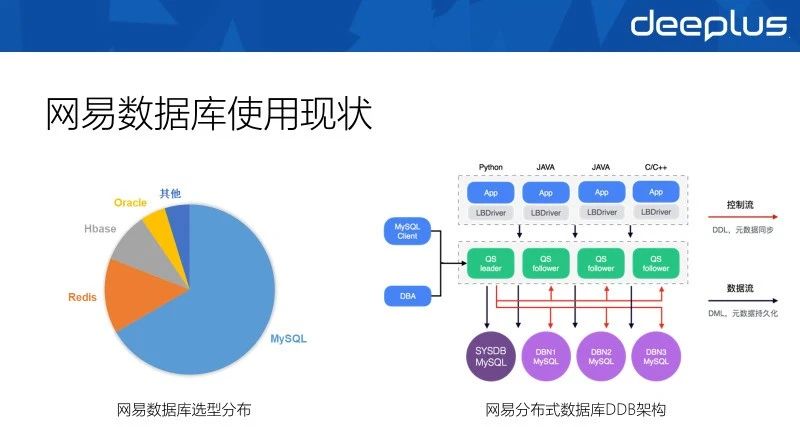
由于其稳定性和开源的特性,超过一半的数据库实例是MySQL。而缓存则是Redis使用最广,数据量较大时会选用HBase。Oracle仍然在一些老的系统内有使用,而其他一些NewSQL数据库则还在测试验证阶段。
单实例的MySQL处理能力有限,无法满足网易内各个产品的使用需求,所以网易内大量的MySQL实际是挂在了自研的分布式数据库DDB的下面,DDB封装了分库分表的能力,对外提供了可扩展的数据库处理能力。DDB的实现思路和开源的MyCat、ShardingSphere很像,这里就不赘述了。
文章后续的多活方案都以MySQL作为对象描述。
四、机房内的多活
机房内的数据库多活其实是单机房内数据库的高可用方案。一个主节点提供读写能力,一个高可用从作为主实例的备份,还有一个只读从对外提供只读的能力。这里三节点的部署方式能够保证任何一个节点不可用时,都有备用节点接替其提供服务,而整个系统的处理能力不会下降。
这个方案适用发展初期的业务,提供了宿主机级别的容灾能力与读写分离的能力。
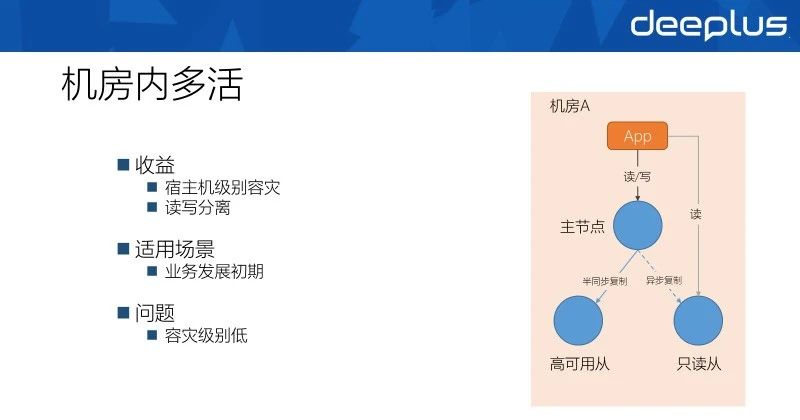
除了异步复制、半同步复制外,MySQL从5.7之后便提供了MySQL Group Replication这种新型的复制模式,相较于传统的主从方案,MGR提供了自动选主、数据强一致和主从皆可写入等能力。MGR在网易内部大量产品上都有不错的推广。

无论是主从复制还是MGR都逃不开一个复制延迟的问题,MySQL复制的是Binlog,Binlog发送到从节点到Binlog在从节点上回放执行有一段时间差,这就是复制延迟。
在主从切换时,从节点必须回放完堆积的Binlog才能对外提供服务,所以过大的复制延迟会导致不可控的主从切换时间。另外只读节点上复制延迟过大,也会导致业务读到过时的数据,可能影响到业务的正确性。
MySQL后续版本提升了其并行复制的能力,但仍然没能完全解决复制延迟过高的问题,我们的做法是监控各个实例的TPS情况,当达到可能触发复制延迟时就对集群做水平拆分(通过DDB的扩容完成)。
业务上的话DDB提供了LOADBALANCE这样的hint语法,允许业务指定SQL能容忍的复制延迟,如果延迟超过设定的阈值,则会调度到主节点执行。

五、跨机房多活
如果业务有跨机房容灾的需求,或单一机房内资源已经无法满足业务的发展需求时就有跨机房多活的需求了。最完善的方案是使用单元化来做,但是单元化对业务的改造代价过大,所以出现了一种折中的跨机房多活方案。
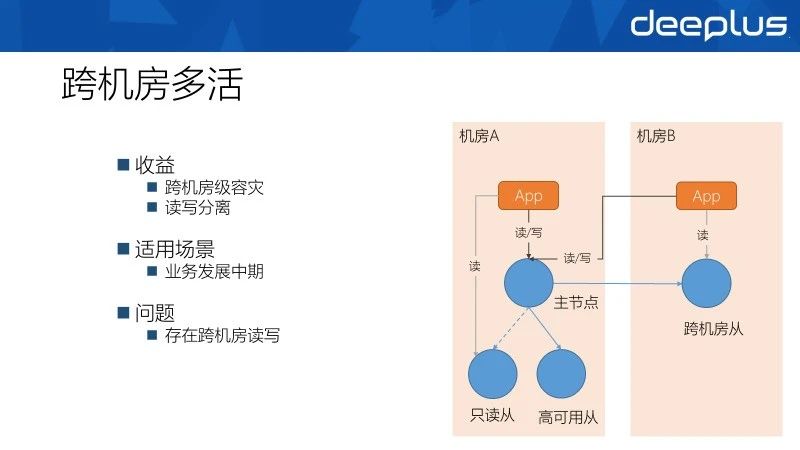
此方案中业务层代码还是在每个机房部署一套,但是在数据库的写操作和对一致性要求较高的读请求会路由到主机房,而每个机房都有自己的只读实例提供一致性要求不太高的读请求。
此方案提供了简单的跨机房容灾能力,但是跨机房的读写会造成较大的延迟,且对机房间的稳定性要求也较高。
分享前我简单搭了一个实验环境,测试了在相同的并发下不同的延迟对数据库性能的影响。
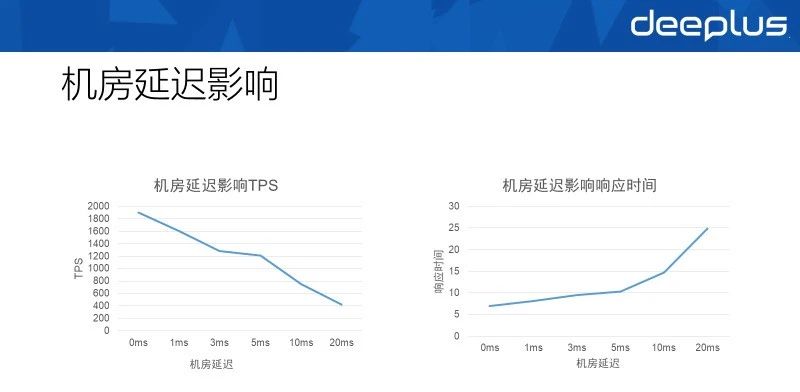
当延迟上升到3ms时,数据库性能下降在30%+,当延迟上升到20ms时,数据库性能下降在75%+。而3ms和20ms刚好是同城多机房和跨城多机房的一个延迟标准。
从数据上看,同城情况下,强一致的同步方案仍然是可行的,而跨城的情况下,基本只能用异步的同步方案了。
六、跨机房单元化
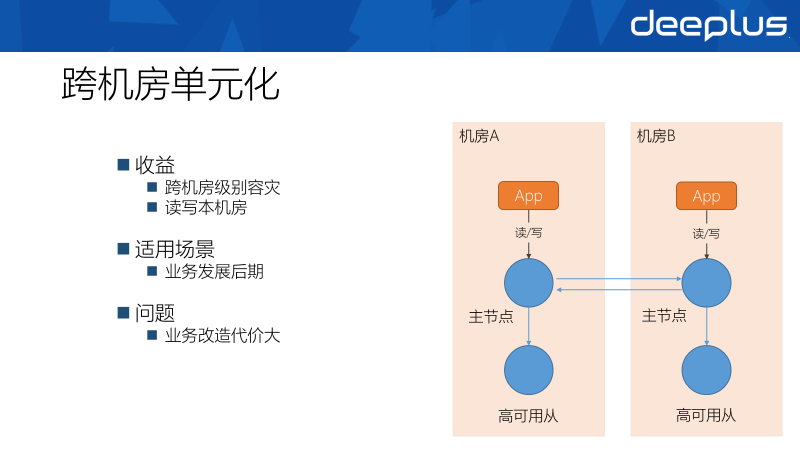
应用仍然在每个机房对立部署,但是机房内的应用只读写本机房的数据库,为了避免多写带来的数据冲突,每个机房只写自己负责的数据,这就是跨机房单元化多活。这个方案中最重要的就是对流量的路由,每个机房负责了一部分业务流量,常见的划分方式为按照ID Hash划分,或者按照地域划分。
此方案解决了上面方案跨机房读写的延迟问题,并且具有更好的水平扩展性,唯一的弊端是业务改造代价较大。数据库层要提供较好的数据同步能力,缓存、消息队列、RPC等组件都要做对应的改造。
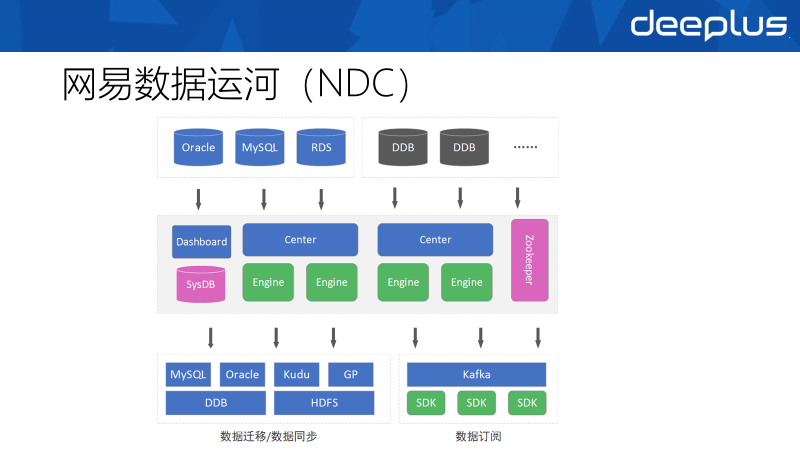
不同单元的数据库双向同步工作我们使用自研的网易数据运河(NDC)来完成。NDC对外主要提供了数据迁移/数据同步和数据订阅的能力,数据同步将关系型数据库的数据实时同步到异构的对端数据库或数仓中,数据订阅则将数据库的增量变更推送进消息队列,供业务方或流计算任务消费。
数据库单元化场景下主要用到NDC的双向同步能力。
七、解决回环复制
双向同步第一个要解决的问题即是回环复制。如果对同步的数据不加过滤仍由其在不同单元的数据库中来回复制必然消耗大量的网络带宽,最终还会导致数据不一致。
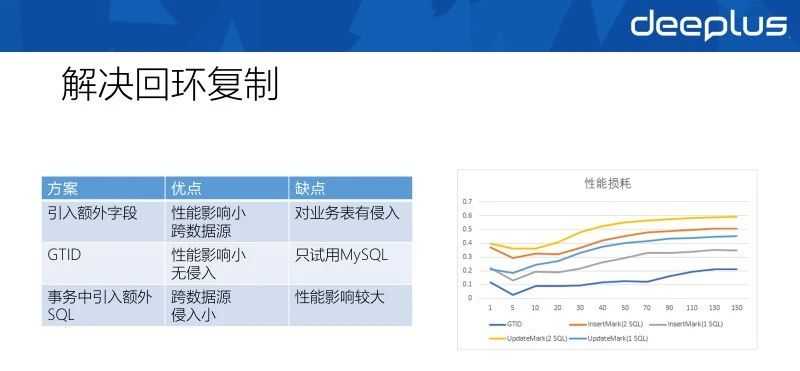
解决回环复制的核心是如何给每个增量变更标注其发生的机房,然后在同步时避免将其同步回发生的机房,就能解决回环复制的问题了。这里总结了三种解决回环复制的方案:
引入额外字段:给每个同步的表加入额外字段标注上一次对其操作的机房信息,此方案对同步的性能影响最小,切可以做到跨不同数据库类型使用,但是对业务的表有侵入。
GTID:使用MySQL自己的GTID来标注事务的机房信息,这也是MySQL原生复制解决回环复制的方案,其对同步的性能影响较小,完全无侵入,但是只能用于MySQL之间的双向同步。
事务中引入额外SQL:在业务的事务中加入额外的SQL来标注此事物产生的机房,此方案也能做到跨数据源,对业务侵入较小,但是对同步的性能影响较大。
三种方案都有各自的优缺点,实现上根据需要选择即可。NDC对三种方案都做了实现,在单元化场景下实际选择的是方案一,主要是其使用的额外字段同时是另外一个功能需要的字段,算是重复利用,没有引入额外开销。
八、解决数据冲突
正常情况下,每个单元都写自己负责的数据,不存在数据冲突,但是当某个单元不可用,要做流量切换的时候,就会出现多个单元同时写入同一行数据的情况,从而产生数据冲突。数据冲突不可避免,我们需要一个机制保证产生冲突的数据最终能保证一致。
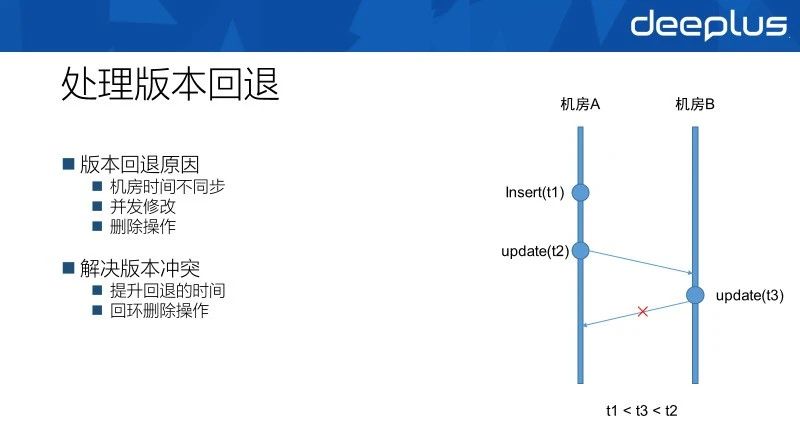
解决数据冲突的核心思路是给每个变更赋予一个版本信息,当产生数据冲突时总是保留高版本的数据即可保证最终一致性。NDC采用了最简单的物理时间作为变更的版本信息,在进行数据同步时,只有当对端版本低于(或等于)同步的变更时,才同步到对端。

这样的数据冲突解决方案能解决99%以上的数据冲突,保证数据的最终一致。但是在一些特殊情况下可能失效,一个比较典型的例子就是机房间由于物理时间基准不一致,某个后发生的变更它的版本却更小,这样这个变更无法同步到对端机房,最终导致数据不一致。
解决这个问题的办法是将这种特殊数据版本信息给提升到发生变更之前的版本,保证变更能同步到其他机房。
在实践中我们发现单个机房内对同一行数据的并发修改也可能造成版本后退,当删除和插入操作同时进行时也可能出现版本未知的情况,对于这样的特殊场景都只能通过调整特殊的同步手段最终来确保数据的一致性。
九、实时数据校验
数据校验对一个数据同步系统是一个可选但又是必须的功能。在单元化的双向同步功能中我们不仅使用定期的全量校验发现系统中存在的不一致风险,还提过了实时数据校验功能更实时地发现数据不一致的风险。数据校验的覆盖范围和对数据库的性能影响是一个相悖的问题,更大的校验覆盖范围必将导致更大的数据库性能开销。产品上我们允许用户选择实时数据校验的范围,可选的范围包括:
双写数据校验:所有在多个单元都发生了写入的数据都进行校验。
冲突数据校验:产生了数据冲突的双写数据才进行校验。
风险数据校验:存在版本回退这样的特殊数据才进行数据校验。
数据校验的实现比较简单,将需要校验的数据放入队列中,校验线程不断地去取需要校验的数据,并比对源和目标的数据是否一致即可。
十、总结
网易数据库多活经历了机房内多活、跨机房多活和跨机房单元化多活三个阶段。在数据库多活上积累了一些经验,之后也还有更长的路要走。希望这些经验能够给各位一些启发,也期待和大家在数据库多活的话题上有更多的交流。