大型系统在线问题诊断与定位
- - 掘金 架构本文是武汉 gopher meetup 的分享内容整理而成,分享内容在 “无人值守” 的两篇和其它社区分享中亦有提及. (也就是说你看过那两篇,这个可以不用看了). 混口饭吃也是不容易,既然有问题了,我们还是要解决的. 要先看看有没有现成的思路可以借鉴. Google 在 这篇论文里提到过其内部的线上 profile 流程:.
本文是武汉 gopher meetup 的分享内容整理而成,分享内容在 “无人值守” 的两篇和其它社区分享中亦有提及。(也就是说你看过那两篇,这个可以不用看了)
老板说:

队友说:

外组同事说:

底层团队说:

你:

混口饭吃也是不容易,既然有问题了,我们还是要解决的。要先看看有没有现成的思路可以借鉴?
Google 在 这篇论文里提到过其内部的线上 profile 流程:
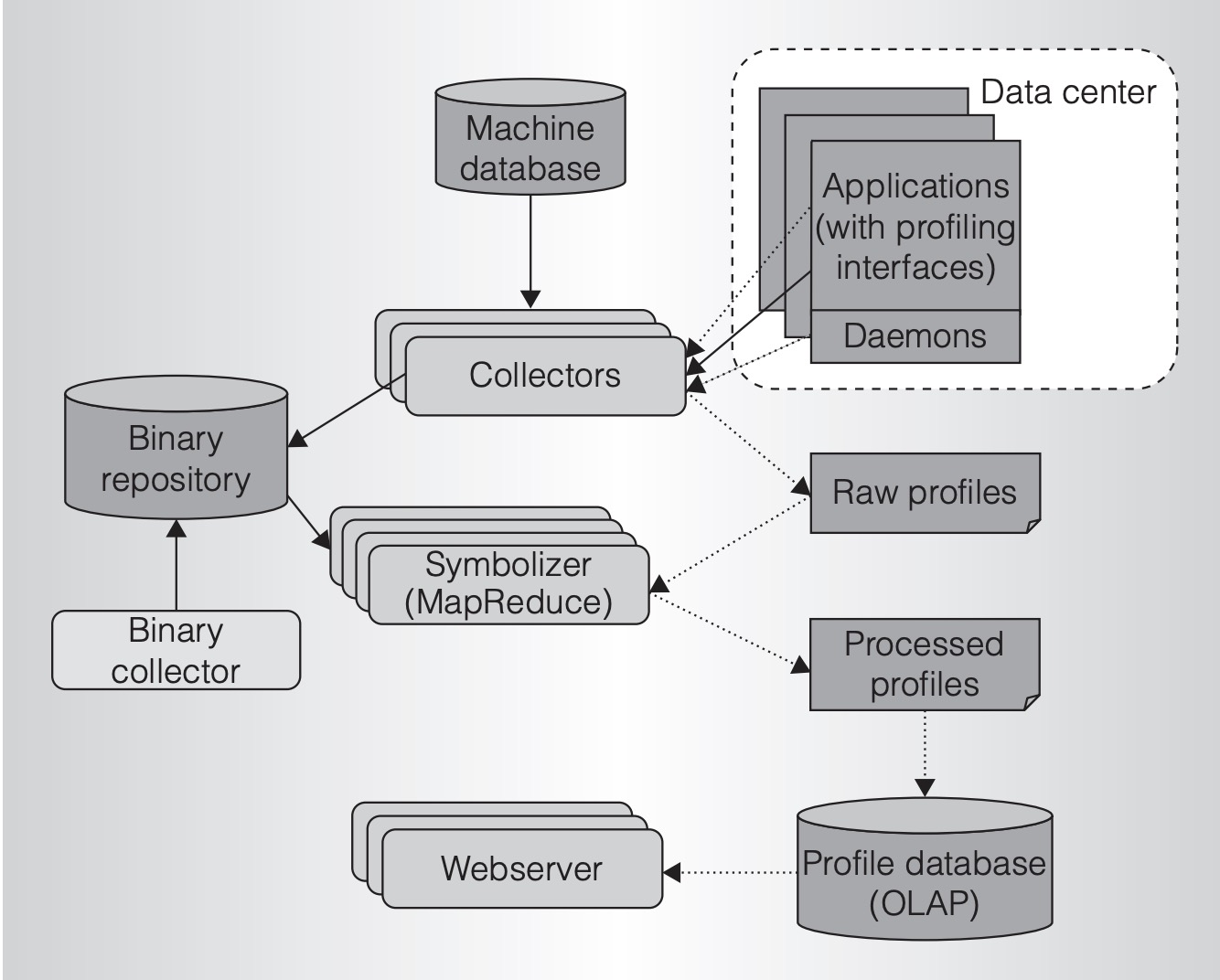
架构图已经比较简单了,线上应用暴露 profile 接口,collector 定时将 profile 信息采集到二进制存储,由统一的在线平台展示。
这篇论文催生了一些开源项目和创业公司,例如在 这篇文章 中,对 continuous profiling 有很不错的解释。
我们日常的 CI 和 CD 流水线可以高频次发布线上系统,当线上有 continuous profiling 系统在运行时,每次发布我们都能够得到实时的性能快照,并与发布前的性能做快速对照。
系统的性能问题和其它技术问题一样,同样是发现得越早,解决起来就越快,损失越小。
Google Cloud 上也有 profiler 相关的 产品,是由 Go 原先的 pprof 开发者开发的,她在文章中声称每分钟对应用采集 10s 的 profile,大约有 5% 的性能损失,还是可以接受的。
简单来说,continuous profiling 带给我们的优势主要就是三点:
有了思路,再看看有没有具体的开源产品可以参考。
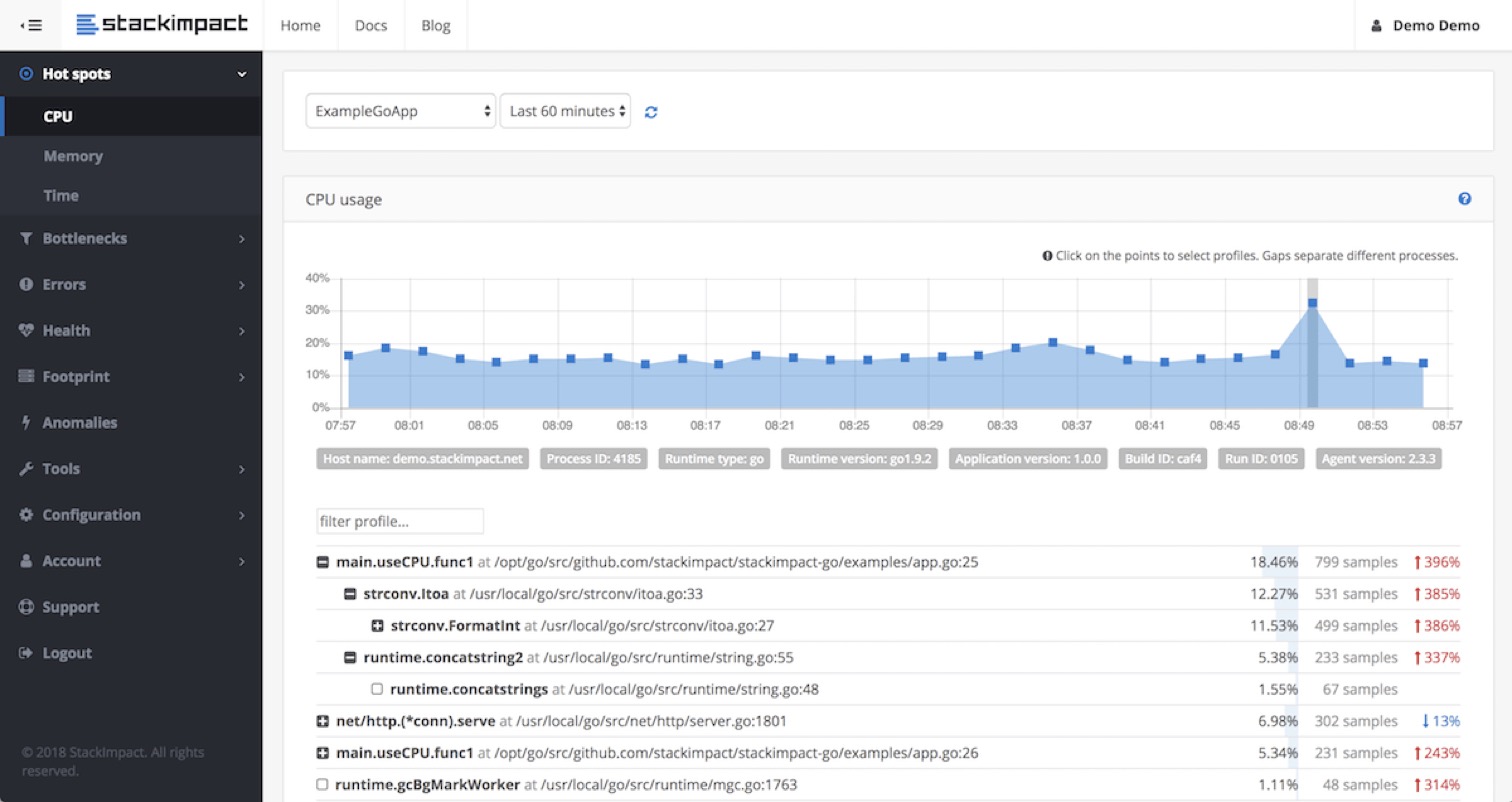
stackimpact-go 是社区比较早的开源项目了,不过只开源了 client 部分,所以 dashboard 和后端部分一直是一个谜,不过我们大概也能看出来,有这种曲线图形式的 profile 数据,有性能衰减时能及时发现。
conprof 其实也差不多。
profefe 也差不多。
看起来思路都一样,这个需求很简单,我们只要找监控团队帮忙做一套皮肤就可以了!
但监控团队也很无奈。

求人不如求己,我们需要定位的是抖动问题,那我们以 5s 为单位,把进程的 CPU 使用 (gopsutil),RSS(gopsutil),goroutine 数 (runtime.NumGoroutine),用 10 大小的环形数组保存下来,每次采集到新值时,与之前多个周期的平均值进行 diff 就可以了:
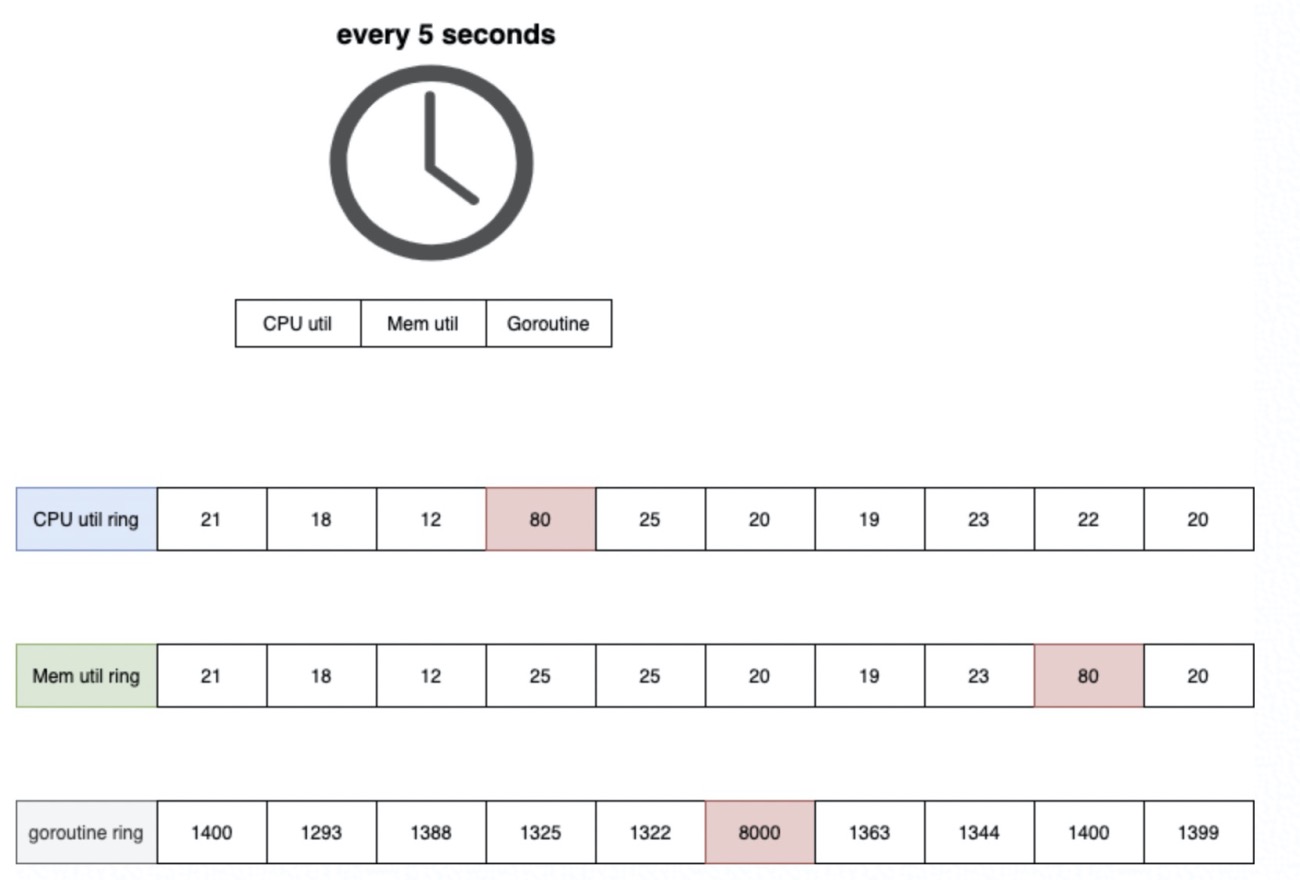
当波动率超过可以接受的范围,则认为当前进程发生了资源使用抖动,那么:
一套方案做下来,还挺简单的。当我们收到模块的 CPU、内存或 goroutine 数报警时,上线到相应的实例来查看即可。
某模块突然出现了 RSS 使用飚升,上线看之后发现自动 dump 文本的 profile 中,单个对象的 inuse_space 超过了 1GB:
// inuse_objects: inuse_space [alloc_objects : alloc_space]
1 : 1024000000 [1 : 1024000000] git.xxx.xxx
复制代码
这是很反常的,阅读代码后发现在 decode 中没有对这些情况进行一定的防御操作,有形如下面的代码:
var l = readLenFromPacket()
var list = make([]byte, l)
复制代码
虽然理论上 body 是可以传 1GB 的,不过内部的 RPC 框架,还是应该对这种情况进行一些限制。
有些在线系统是定时任务调用的,所以其访问峰值非常不平均,在定时任务触发后,会有一段时间 CPU 使用非常高,有了自动 CPU profile dump,就非常容易找到具体哪里使用的 CPU 很高了。
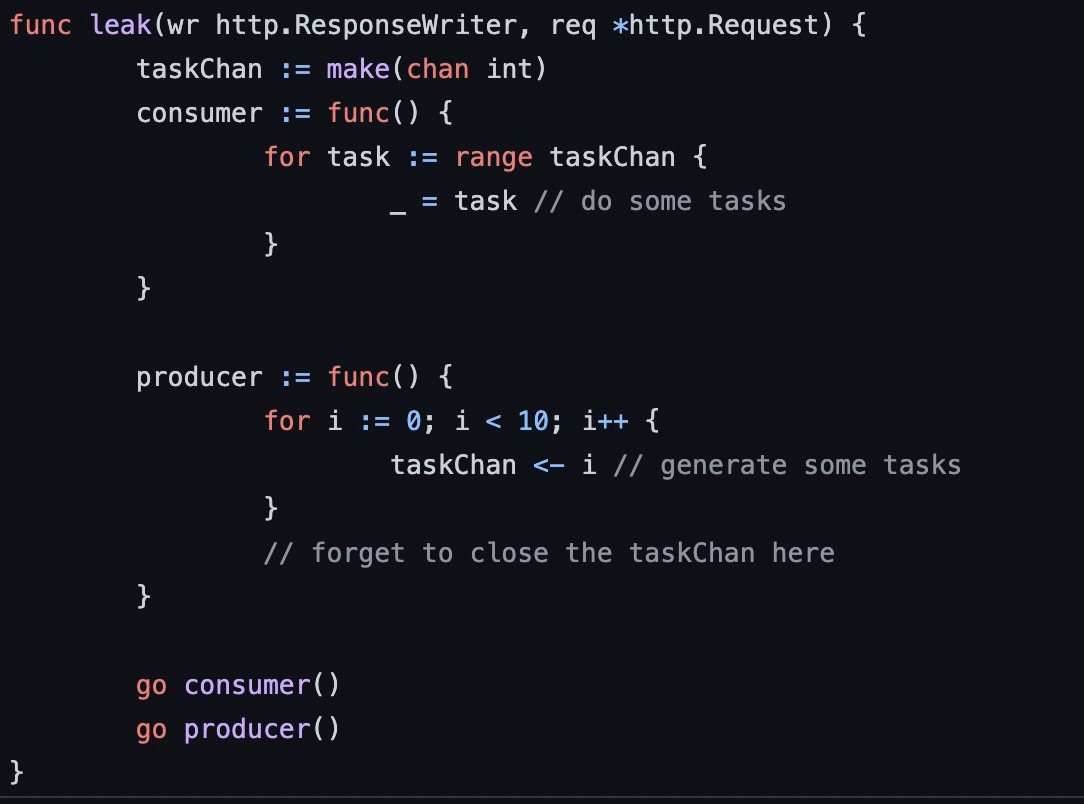
类似这样的 goroutine 泄露问题,也是可以很容易发现的。
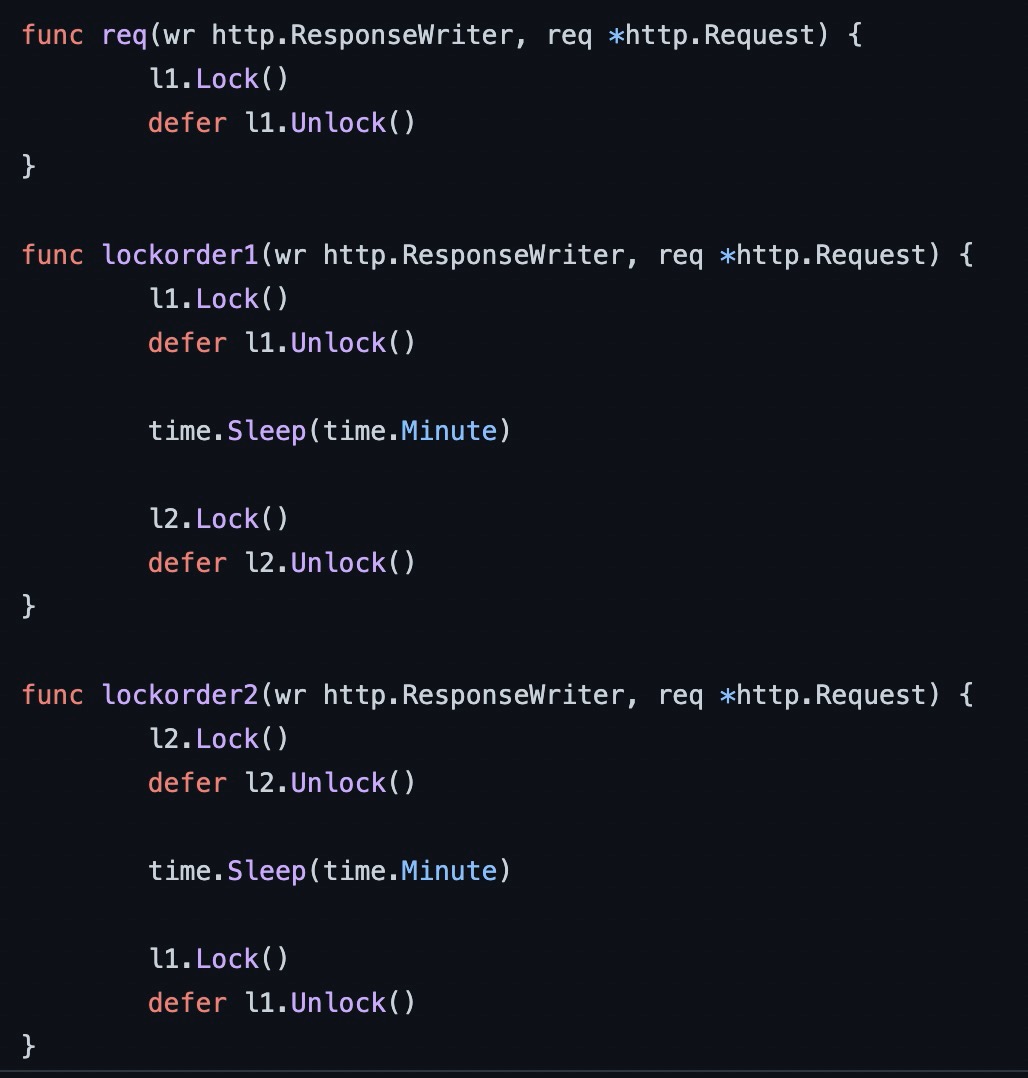
因为我们可以采集到所有 goroutine 的栈信息,所以理论上通过遍历我们可以发现哪些 goroutine 是持锁的,例如下列代码,当发生死锁时,我们可以直接把持锁的 goroutine dump 下来,就很容易发现死锁了:
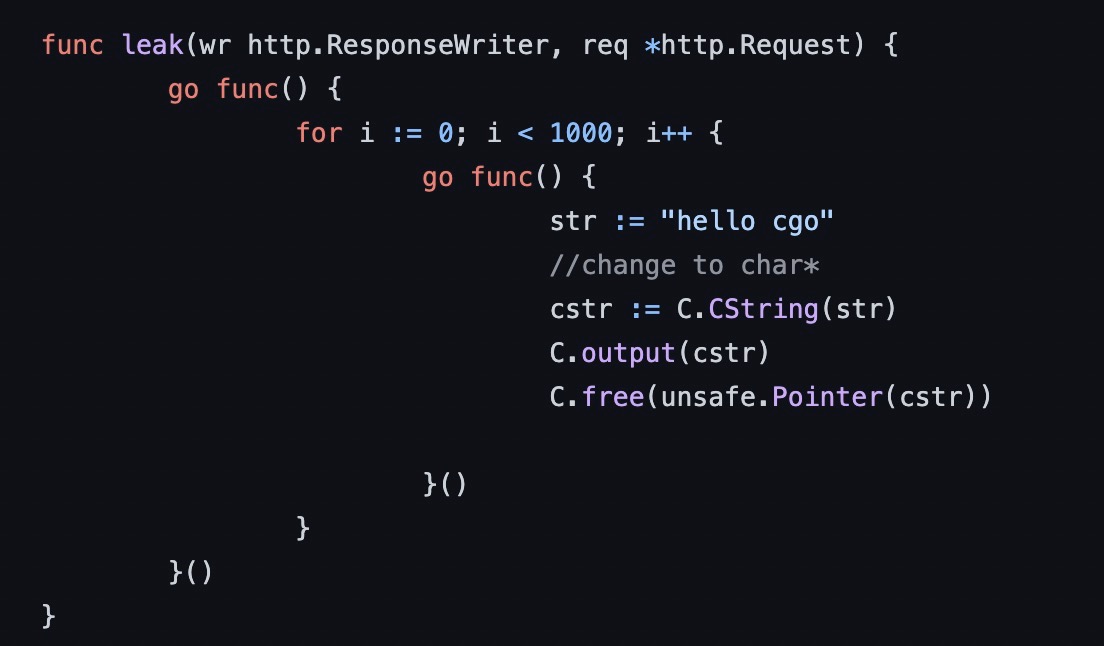 ,当线程因为调用 cgo 等原因发生了阻塞,会造成线程数暴涨,这时候我们可以将 goroutine 和 thread profile dump 下来,进行诊断。
,当线程因为调用 cgo 等原因发生了阻塞,会造成线程数暴涨,这时候我们可以将 goroutine 和 thread profile dump 下来,进行诊断。
有了自动化的工具,日子更好过了。