在容器里有两个非常重要的概念,一个是 namespace用来进行对容器里所有进程的隔离;另一个就是 cgroup,用来对容器资源进行限制。那 cgroup又是如何实现对进行资源的限制呢,今天我们来了解一下它的实现原理。
什么是cgroup
cgroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离 ` 进程组` 所使用的物理资源(如 cpu、memory、磁盘IO等等) 的机制,被 LXC、 docker 等很多项目用于实现进程资源控制。cgroup 是将任意进程进行分组化管理的 Linux 内核功能。
cgroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。 一定要切记,这里的限制单元为 进程组,而不是进程。
子系统
上面提到的具体的资源管理功能统称为 cgroup 子系统,所有子系统列表可以通过 cat /proc/cgroups 命令查看,主要有以下几大子系统:
# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 4 7 1
cpu 2 89 1
cpuacct 2 89 1
blkio 3 86 1
memory 7 150 1
devices 6 84 1
freezer 5 7 1
net_cls 10 7 1
perf_event 12 7 1
net_prio 10 7 1
hugetlb 8 7 1
pids 9 94 1
rdma 11 1 1
-
cpuset:如果是多核心的CPU, 这个子系统会为 cgroup 任务分配单独的CPU和内存。 -
cpu:使用调度程序为cgroup任务提供CPU的访问。 -
cpuacct:产生cgroup 任务的CPU资源报告 -
blkio:设置限制每一个块设备的输入输出控制。例如:磁盘,光盘以及usb 等等。 -
memory: 设置每一个cgroup 的内存限制以及产生内存资源报告。 -
devices:容许或拒绝cgroup任务对设备的访问。 -
freezer:暂停和恢复cgroup任务。 -
net_cls: 标记每一个网络包以供cgroup 方便使用。 -
ns:命名空间子系统,能够设置一个子系统的上限配额。 -
perf_event: 增加了对每一个group 的监测跟踪的能力,能够监测属于某个特定的group 的全部线程以及运行在特定,监控能力超出限制则进行终止。 -
net_prio 设置cgroup中进程产生的网络流量的优先级 -
hugetlb 限制使用的内存页数量 -
pids 限制任务的数量
目前 docker 只是用了其中一部分子系统,实现对资源配额和使用的控制。如可以使用 ` freezer` 子系统对 `进行组` 进行挂起和恢复。
cgroup组件术语
-
task:在cgroup中,任务就是系统的一个进程 -
subsystem:一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。 -
control group:控制族群就是按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制; -
hierarchy:树形结构的 CGroup 层级,每个子 CGroup 节点会继承父 CGroup 节点的子系统配置,每个 Hierarchy 在初始化时会有默认的 CGroup(Root CGroup); - 控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。比如一组task进程通过cgroup1限制了CPU使用率,然后其中一个日志进程还需要限制磁盘IO,为了避免限制磁盘IO影响到其他进程,就可以创建cgroup2,使其继承cgroup1并限制磁盘IO,这样这样cgroup2便继承了cgroup1中对CPU使用率的限制并且添加了磁盘IO的限制而不影响到cgroup1中的其他进程;
组件关系
- 每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup,此 cgroup 在创建层级时自动创建,后面在该层级中创建的 cgroup 都是此 cgroup 的后代)的初始成员;
- 一个 subsystem 最多只能附加到一个层级 hierarchy;
- 一个层级 hierarchy 可以附加多个子系统 subsystem;
- 一个任务 task 可以是多个 cgroup 的成员,但是这些 cgroup 必须在不同的层级hierarchy;
- 系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的 cgroup。
- 一个进程fork出子进程时,该子进程默认自动成为父进程所在的cgroup的成员,也可以根据情况将其移动到到不同的cgroup中.
如图所示,CPU 和 Memory 两个子系统有自己独立的层级系统,而又通过 Task Group 取得关联关系
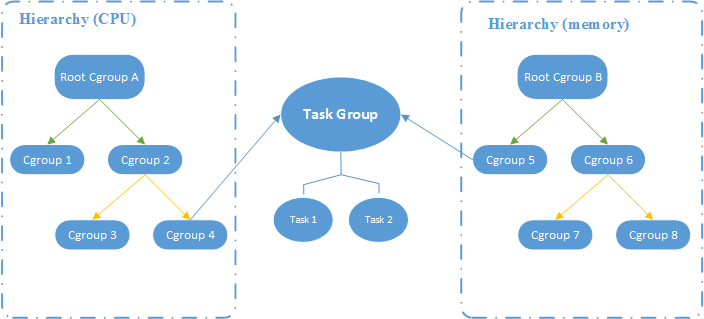
cgroup关联图
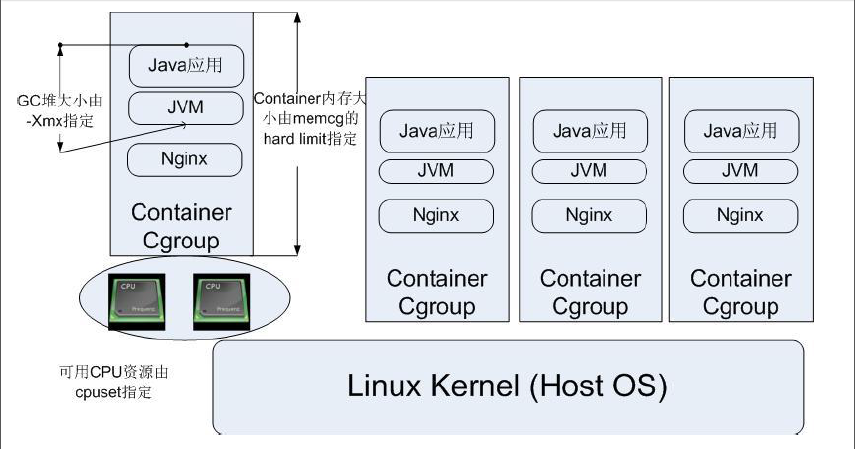
CGroup 典型应用架构图
CGroup 技术可以被用来在操作系统底层限制物理资源,起到 Container 的作用。上图中每一个 JVM 进程对应一个 Container Cgroup 层级,通过 CGroup 提供的各类子系统,可以对每一个 JVM 进程对应的线程级别进行物理限制,这些限制包括 CPU、内存等等许多种类的资源。
cgroup实战
在 Linux 中,cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。在 Ubuntu 16.04 机器里,可以用 mount 指令把它们展示出来:
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
它的输出是一些文件系统目录,这些目录名就是当前系统所支持的子系统,这些子系统都在 /sys/fs/cgroup/ 目录内,如对于cpu子系统来说,相关的几个配置文件为
$ ls /sys/fs/cgroup/cpu
aegis cgroup.procs cpu.cfs_quota_us cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys kubepods.slice system.slice user.slice
assist cgroup.sane_behavior cpu.shares cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user notify_on_release tasks
cgroup.clone_children cpu.cfs_period_us cpu.stat cpuacct.usage_all cpuacct.usage_percpu_user init.scope release_agent test
其中 ` cpu.cfs_quota_us` 和 ` cpu.cfs_period_us` 是经常使用的两个配置项,两者必须组合使用,表示一个进程组在 `cpu.cfs_period_us` 段时间内,分配给CPU的时间比例为 ` cpu.cfs_quota_us`。
另外输出结果中包含一些子目录,如 aegis、 assist、 kubepods.slice、 system.slice、 user.slice、 test 和 init.scope。
现在我们看下这些子系统配置文件如何使用,首先我们在 /sys/fs/cgroup/cpu/ 目录下创建一个目录 mycontainer,这个目录称为cgroup,即”控制组”。
$ cd /sys/fs/cgroup/cpu/
$ mkdir mycontainer
$ sys/fs/cgroup/cpu# ls mycontainer/
cgroup.clone_children cpu.cfs_period_us cpu.shares cpu.uclamp.max cpuacct.stat cpuacct.usage_all cpuacct.usage_percpu_sys cpuacct.usage_sys notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.stat cpu.uclamp.min cpuacct.usage cpuacct.usage_percpu cpuacct.usage_percpu_user cpuacct.usage_user tasks
会发现mycontainer目录时会自动出现一些cpu配置文件,有些配置文件内容为-1,表示不限制,其中tasks文件里表示要控制的进程pid。
我们现在做个实现执行一下死循环脚本,便其完全占用CPU达到100%,然后再对此PID进行CPU限制,看下效果如果。
$ while : ; do : ; done &
[1] 1626025
执行top查看
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1626025 root 20 0 12724 1768 0 R 100.0 0.0 0:28.60 bash
发现这个进程的CPU已经达到了100%,下面我们对其进行一下限制。先将进程PID写到 mycontainer 控制组下的tasks文件里,然后限制cpu使用率
$ echo 1626025 > /sys/fs/cgroup/cpu/mycontainer/tasks
$ cat /sys/fs/cgroup/cpu/mycontainer/tasks
1626025
现在我们已成功将其进程号写入tasks文件。上面我们提到过对cpu的限制主要使用两个文件,分别为cpu.cfs_quota_us 和 cpu.cfs_quota_us, 先看一下他们的默认值。
$ cat /sys/fs/cgroup/cpu/mycontainer/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/mycontainer/cpu.cfs_period_us
100000
表示在100ms内分配给cpu的机会为不限制,也就是表示100%的资源。我们要做一下限制,让其在100ms时间内,只分配给 20% 的cpu机会
$ echo 20000 > /sys/fs/cgroup/cpu/mycontainer/cpu.cfs_quota_us
然后再执行一下top命令发现cpu使用率立即降下来了,最多为20%左右,可能会有一点点的超出,这个很正常。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1626025 root 20 0 12724 1768 0 R 20.0 0.0 12:43.38 bash
这里我们只对cpu做了限制,你也可以做内在memory做一下限制,由于这里的脚本只会占用cpu,所以不再演示。对于我们经常使用 docker run 命令启动一个容器的时候,其实都有一个配置参数与配置文件相对应,如
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
如果你到容器目录查看配置文件会发现相应 cpu.cfs_period_us 和 cpu.vfs_quota_us 的值都已被修改。
参考资料