线性回归实战:波士顿房价预测
- - 标点符了解线性回归的原理后,为了更好的掌握相关的技能,需要进入实战,针对线性回归常见的方法有:Scikit和Statsmodels. 美国波士顿房价的数据集是sklearn里面默认的数据集,sklearn内置的数据集都位于datasets子模块下. 一共506套房屋的数据,每个房屋有13个特征值. ZN: 住宅用地所占比例.
了解线性回归的原理后,为了更好的掌握相关的技能,需要进入实战,针对线性回归常见的方法有:Scikit和Statsmodels。
美国波士顿房价的数据集是sklearn里面默认的数据集,sklearn内置的数据集都位于datasets子模块下。一共506套房屋的数据,每个房屋有13个特征值。

from sklearn.datasets import load_boston boston_dataset = load_boston() print(boston_dataset.keys()) print(boston_dataset.feature_names) print(boston_dataset.DESCR)
输出内容:
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
.. _boston_dataset:
Boston house prices dataset
---------------------------
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of black people by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
.. topic:: References
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
CRIM ZN INDUS CHAS NOX ... RAD TAX PTRATIO B LSTAT
0 0.00632 18.0 2.31 0.0 0.538 ... 1.0 296.0 15.3 396.90 4.98
1 0.02731 0.0 7.07 0.0 0.469 ... 2.0 242.0 17.8 396.90 9.14
2 0.02729 0.0 7.07 0.0 0.469 ... 2.0 242.0 17.8 392.83 4.03
3 0.03237 0.0 2.18 0.0 0.458 ... 3.0 222.0 18.7 394.63 2.94
4 0.06905 0.0 2.18 0.0 0.458 ... 3.0 222.0 18.7 396.90 5.33
字段解释:
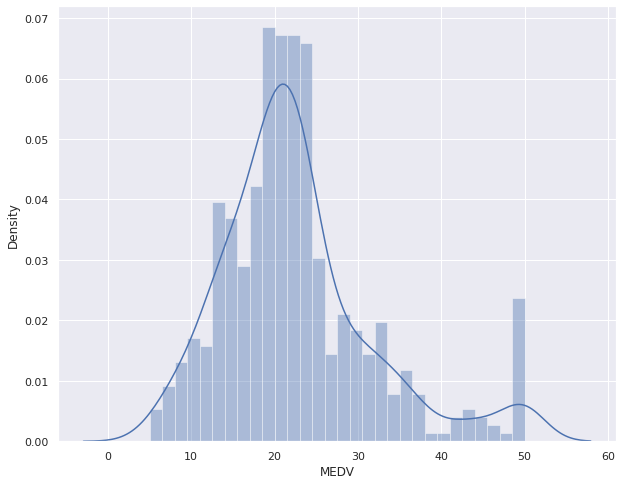
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names) boston['MEDV'] = boston_dataset.target plt.figure(figsize=(10,8)) sns.distplot(boston['MEDV'], bins=30) plt.show()
correlation_matrix = boston.corr().round(2) sns.heatmap(data=correlation_matrix, annot=True) plt.show()
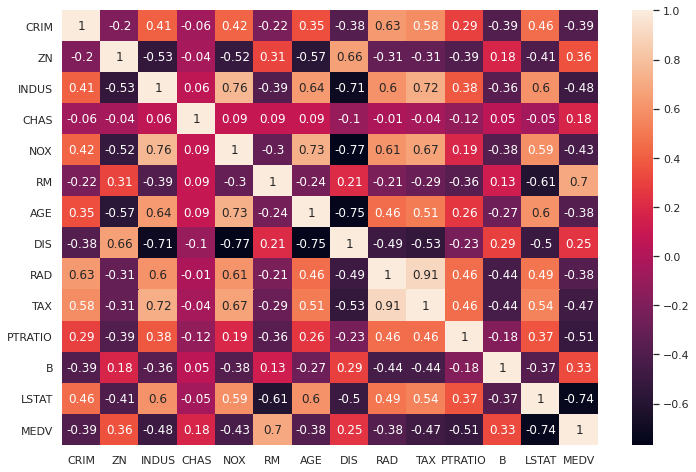
可以看到与房价相关度比较高的字段为’LSTAT’和’RM’。绘制图片,看是否存在线性关系:
plt.figure(figsize=(20, 5))
features = ['LSTAT', 'RM']
target = boston['MEDV']
for i, col in enumerate(features):
plt.subplot(1, len(features) , i+1)
x = boston[col]
y = target
plt.scatter(x, y, marker='o')
plt.title(col)
plt.xlabel(col)
plt.ylabel('MEDV')
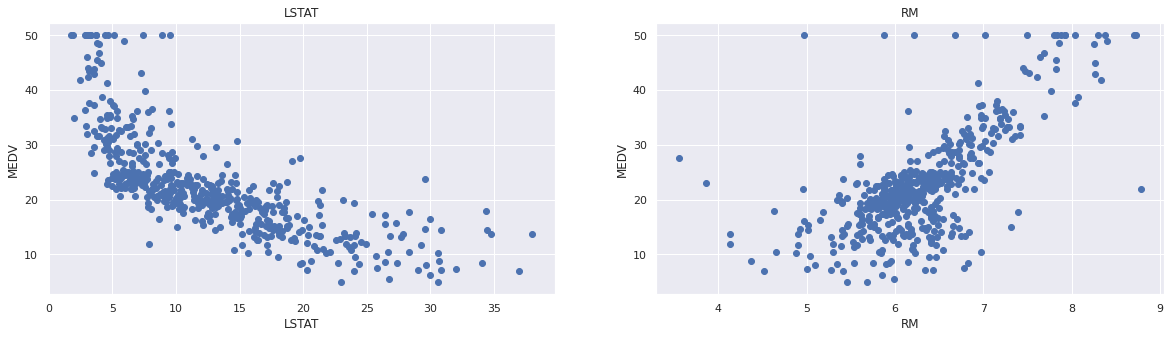
数据准备:
from sklearn.model_selection import train_test_split X = boston[['LSTAT','RM']] y = boston['MEDV'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=5)
示例代码:
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score from sklearn.datasets import load_boston boston_dataset = load_boston() boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names) boston['MEDV'] = boston_dataset.target X = boston[['LSTAT', 'RM']] y = boston['MEDV'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5) lr = LinearRegression() lr.fit(X_train, y_train) # 打印截距 print(lr.intercept_) # 打印模型系数 print(lr.coef_) y_test_predict = lr.predict(X_test) rmse = np.sqrt(mean_squared_error(y_test, y_test_predict)) r2 = r2_score(y_test, y_test_predict) print(rmse, r2)
Statsmodels的OSL是回归模型中最常用的最小二乘法求解法。
import pandas as pd from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split import statsmodels.api as sm boston_dataset = load_boston() boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names) boston['MEDV'] = boston_dataset.target X = boston[['LSTAT', 'RM']] y = boston['MEDV'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5) result = sm.OLS(y_train, X_train).fit() print(result.params) print(result.summary())
这里需要重要介绍的是如何读懂报告。
OLS Regression Results
=======================================================================================
Dep. Variable: MEDV R-squared (uncentered): 0.947
Model: OLS Adj. R-squared (uncentered): 0.947
Method: Least Squares F-statistic: 3581.
Date: Fri, 06 Aug 2021 Prob (F-statistic): 6.67e-257
Time: 16:07:31 Log-Likelihood: -1272.2
No. Observations: 404 AIC: 2548.
Df Residuals: 402 BIC: 2556.
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
LSTAT -0.6911 0.036 -19.367 0.000 -0.761 -0.621
RM 4.9699 0.081 61.521 0.000 4.811 5.129
==============================================================================
Omnibus: 121.894 Durbin-Watson: 2.063
Prob(Omnibus): 0.000 Jarque-Bera (JB): 389.671
Skew: 1.370 Prob(JB): 2.42e-85
Kurtosis: 6.954 Cond. No. 4.70
==============================================================================
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
如何解读报告?来看一些名词解释: