Knative serverless架构详解
- -服务器是一个高性能的 Web 和反向代理服务器. Nginx 在激烈的 Web 服务器竞争中依旧保持良好的发展势头,一度成为. Web 服务器市场的后期之秀,这一切跟 Nginx 的架构设计是分不开的. 来自于my.oschina.net,,由火龙果软件Alice编辑、推荐. 无服务器架构(serverless),则表示代码可以只在需要时运行,在不需要时就停止,从而让你的基础设施能在其他方面自由使用计算资源.
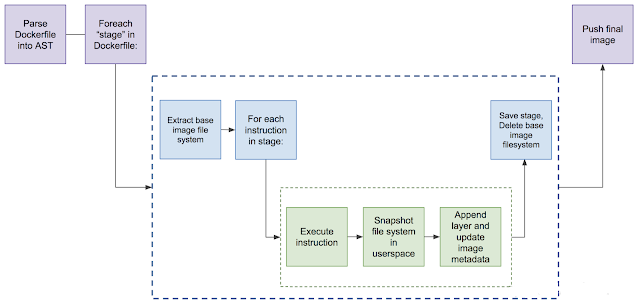
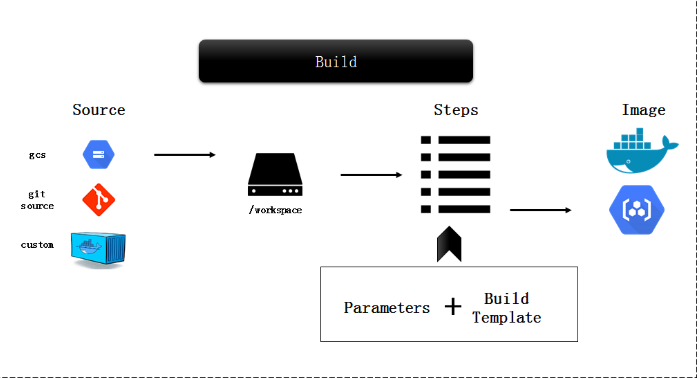
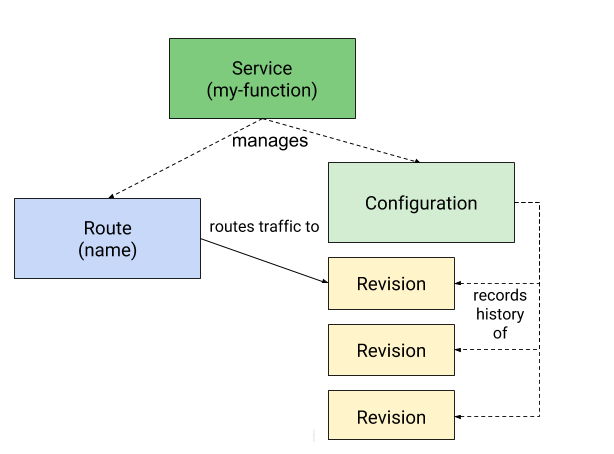
serverless 无服务器架构(serverless),则表示代码可以只在需要时运行,在不需要时就停止,从而让你的基础设施能在其他方面自由使用计算资源。 Kaniko Kaniko 是 Google 造的轮子之一,用于在 Kubernetes 上无需特权的构建 docker image,在 github中,是这样介绍的。 工作原理 传统的 Docker build 是 Docker daemon 根据 Dockerfile,使用特权用户(root)在宿主机依次执行,并生成镜像的每一层: 而 Kaniko 工作原理和此类似,也是按顺序执行每条命令,每条命令执行完毕后为文件系统做快照(snapshot)。并与上一个快照进行对比,如果发现任何不一致,变回创建一个新的层级,并将任何修改都写入镜像的元数据中。 什么是 Knative Knative 的目标是在基于 Kubernetes 之上为整个开发生命周期提供帮助。它的具体实现方式是:首先使你作为开发人员能够以你想要的语言和以你想要的方式来编写代码,其次帮助你构建和打包应用程序,最后帮助你运行和伸缩应用程序。 Knative 主要由 Build、Serving 和 Eventing 三大核心组件构成。Knative 正是依靠这三个核心组件,驱动着 Knative 这艘 Serverless 巨轮前行。下面让我们来分别介绍一下这三个核心组件。 build 通过灵活的插件化的构建系统将用户源代码构建成容器。目前已经支持多个构建系统,比如 Google 的 Kaniko,它无需运行 Docker daemon 就可以在 Kubernetes 集群上构建容器镜像。 Knative Build 是基于现有的 Kubernetes 能力之上,提供的一套标准化、可移植、可复用的容器镜像构建方式。通过在 Kubernetes 上运行复杂的构建任务,Knative Build 使你不必再单独开发和重复这些镜像构建过程, 从而通过系统化、工程化的方式,减少了镜像构建时间及成本。 Build 通过 Kubernetes 自定义资源定义(CRD)实现。 通过 Build 你可以自定义一个从运行到结束的构建流程。例如,可以使用 Knative Build 来获取、构建和打包代码。Build 具备以下功能: 支持 Source 源挂载,目前支持的 Source 源包括: �C git 代码仓库 �C 任意容器镜像 支持通过 BuildTemplate 创建可重复执行构建的模板 支持 K8s ServiceAccount 身份验证 虽然目前 Knative Build 并不提供完整的独立 CI/CD 解决方案,但它却提供了一个底层的构建模块,用户可单独使用该构建模块在大型系统中实现集成和利用。 Serving 基于负载自动伸缩,包括在没有负载时缩减到零。允许你为多个修订版本(revision)应用创建流量策略,从而能够通过 URL轻松路由到目标应用程序。 Knative 作为 Severless 框架最终是用来提供服务的, 那么 Knative Serving 应运而生。 Knative Serving 构建于 Kubernetes 和 Istio 之上,为 Serverless 应用提供部署和服务支持。其特性如下: 快速部署 Serverless 容器 支持自动扩缩容和缩到 0 实例 基于 Istio 组件,提供路由和网络编程 支持部署快照 Knative Serving 中定义了以下 CRD 资源: Service: 自动管理工作负载整个生命周期。负责创建 Route、Configuration 以及 Revision 资源。通过 Service 可以指定路由流量使用最新的 Revision 还是固定的 Revision Route:负责映射网络端点到一个或多个 Revision。可以通过多种方式管理流量。包括灰度流量和重命名路由 Configuration: 负责保持 Deployment 的期望状态,提供了代码和配置之间清晰的分离,并遵循应用开发的 12 要素。修改一次 Configuration 产生一个 Revision Revision:Revision 资源是对工作负载进行的每个修改的代码和配置的时间点快照。Revision 是不可变对象,可以长期保留 Configuration(配置)和 Revision(修订版本) Knative Serving 始于 Configuration。您可以在 Configuration 中为部署定义所需的状态。最小化 Configuration 至少包括一个配置名称和一个要部署容器镜像的引用。在 Knative 中,定义的引用为 Revision。Revision 代表一个不变的,某一时刻的代码和 Configuration 的快照。每个 Revision 引用一个特定的容器镜像和运行它所需要的任何特定对象(例如环境变量和卷)。然而,您不必显式创建 Revision。由于 Revision 是不变的,它们从不会被改变和删除,相反,当您修改 Configuration 的时候,Knative 会创建一个 Revision。这允许一个 Configuration 既反映工作负载的当前状态,同时也维护一个它自己的历史 Revision 列表。 例如:
其中默认情况下,Knative 将假定您的应用程序监听 8080 端口。 Configuration 可以指定一个已有的容器镜像,如示例 2-1 中所示。或者,它也可以选择指向一个 Build 资源以从源代码创建一个容器镜像。 Knative 转换 Configuration 定义为一些 Kubernetes 对象并在集群中创建它们。在启用 Configuration 后,可以看到相应的 Deployment、ReplicaSet 和 Pod。 现在我们有了用于运行我们应用的 Pod,但是我们怎么知道该向哪里发送请求?这正是 Route 用武之地。 Route(路由) Knative 中的 Route 提供了一种将流量路由到正在运行的代码的机制。它将一个命名的,HTTP 可寻址端点映射到一个或者多个 Revision。Configuration 本身并不定义 Route
这里展示了一个将流量发送到指定 Configuration 最新 Revision 的最基本路由定义。 这个定义中,Route 发送 100% 流量到由 configurationName 属性指定 Configuration 的最新就绪 Revision,该 Revision 由 Configuration YAML 中 latestReadyRevisionName 属性定义。您可以通过发送如下 curl 命令来测试这些 Route 和 Configuration :
你可以通过指定流量版本名称进行abtest
指定的 Revision 可以使用 v1 子域名访问,如下 curl 命令所示:
Knative 也允许以百分比的方式跨 Revision 进行流量分配。支持诸如增量发布、蓝绿部署或者其他复杂的路由场景 注意:Knative 默认使用 example.com 域名,但不适合生产使用。您会注意到在 curl 命令 (v1.knative-routing-demo.default.example.com) 中作为一个主机头传递的 URL 包含该默认值作为域名后缀。URL 格式遵循模式 {REVISION_NAME}.{SERVICE_NAME}.{NAMESPACE}.{DOMAIN} 。 在这个案例中,子域名中 default 部分指的是命名空间。 下面我们来看看如何改变这些值以及如何使用自定义域名。 Autoscaler(自动伸缩器)和 Activator(激活器) Serverless 的一个关键原则是可以按需扩容以满足需要和缩容以节省资源。Serverless 负载应当可以一直缩容至零。这意味着如果没有请求进入,则不会运行容器实例。Knative 使用两个关键组件以实现该功能。它将 Autoscaler 和 Activator 实现为集群中的 Pod。您可以看到它们伴随其他 Serving 组件一起运行在 knative-serving 命名空间中. Autoscaler 收集打到 Revision 并发请求数量的有关信息。为了做到这一点,它在 Revision Pod 内运行一个称之为 queue-proxy 的容器,该 Pod 中也运行用户提供的 (user-provided) 镜像。可以在相应 Revision Pod 上,通过运行 kubectl describe 命令可以看到这些容器
queue-proxy 检测该 Revision 上观察到的并发量,然后它每隔一秒将此数据发送到 Autoscaler。Autoscaler 每两秒对这些指标进行评估。基于评估的结果,它增加或者减少 Revision 部署的规模。 默认情况下,Autoscaler 尝试维持每 Pod 每秒平均 100 个并发请求。这些并发目标和平均并发窗口均可以变化。Autoscaler 也能够被配置为利用 Kubernets HPA (Horizontal Pod Autoscaler) 来替代该默认配置。 这将基于 CPU 使用率来自动伸缩但不支持缩容至零。这些设定都能够通过 Revision 元数据注解 (annotations) 定制。有关这些注解的详情,请参阅 Knative 文档。https://knative.dev/blog/ 例如,一个 Revision 每秒收到 350 个请求并且每次请求大约需要处理 0.5 秒。使用默认设置 (每 Pod 100 个并发请求),这个 Revision 将扩展至两个 Pod:
Autoscaler 也负责缩容至零。Revision 处于 Active (激活) 状态才接受请求。当一个 Revision 停止接受请求时,Autoscaler 将其置为 Reserve (待命) 状态,条件是每 Pod 平均并发必须持续 30 秒保持为 0 (这是默认设置,但可以配置)。 处于 Reserve 状态下,一个 Revision 底层部署缩容至零并且所有到它的流量均路由至 Activator。Activator 是一个共享组件,其捕获所有到待命 Revisios 的流量。当它收到一个到某一待命 Revision 的请求后,它转变 Revision 状态至 Active。然后代理请求至合适的 Pods。 Autoscaler 如何伸缩 Autoscaler 采用的伸缩算法针对两个独立的时间间隔计算所有数据点的平均值。它维护两个时间窗,分别是 60 秒和 6 秒。Autoscaler 使用这些数据以两种模式运作:Stable Mode (稳定模式) 和 Panic Mode (忙乱模式)。在 Stable 模式下,它使用 60 秒时间窗平均值决定如何伸缩部署以满足期望的并发量。 如果 6 秒窗口的平均并发量两次到达期望目标,Autoscaler 转换为 Panic Mode 并使用 6 秒时间窗。这让它更加快捷的响应瞬间流量的增长。它也仅仅在 Panic Mode 期间扩容以防止 Pod 数量快速波动。如果超过 60 秒没有扩容发生,Autoscaler 会转换回 Stable Mode。 serving 在 Knative 中,Service 管理负责的整个生命周期。包括部署、路由和回滚。(不要将 Knative Service 和 Kubernetes Service 混淆。它们是不同的资源。) Knative Service 控制一系列组成软件的 Route 和 Configuration。Knative Service 可以被看作是一段代码 ―― 您正在部署的应用或者函数。 一个 Service 注意确保一个应用有一个 Route、一个 Configuation,以及为每次 Service 更新产生的一个新 Revision。当创建一个 Service 时,您没有特别定义一个 Route,Knative 创建一个发送流量到最新 Revision 的路由。您可以选择一个特定的 Revision 以路由流量到该 Revision。 不要求您明确创建一个 Service。Route 和 Configuration 可以被分开在不同的 YAML 文件(如示例 2-1 和 示例 2-4)。在这种情形下,您可以应用每个单独的对象到集群。然而,推荐的方式使用一个 Service 来编排 Route 和 Configuration。
注意这个 service.yml 文件和 configuration.yml 非常相似。这个文件定义 Configuration 并且是最小化 Service 定义。由于这里没有 Route 定义,一个默认 Route 指向最新 Revision。Service 控制器整体追踪它所有的 configuration 和 Route 的状态。然后反映这些状态在它的 ConfigurationsReady 和 RoutesReady conditions 属性里。当通过 CLI 使用 kubectl get ksvc 命令请求 Knative Service 信息的时候,这些状态可以被看到。
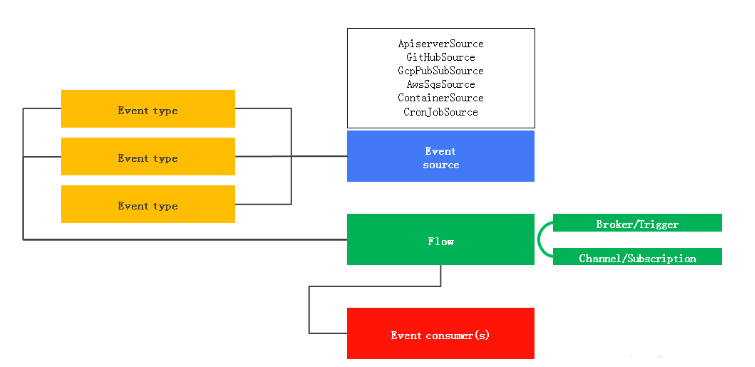
总结 至此已经向您介绍了 Service、Route、Configuration 和 Revision。Revision 是不变的并且只能经由 Configuration 改变而被创建。您可以分别单独创建 Configuration 和 Route,或者把它们组合在一起并定义为一个 Service。理解 Serving 组件的这些构建块是使用 Knative 的基础。您部署的应用均需要一个 Service 或者 Configuration 以在 Knative 中作为容器运行。 Eventing 使得生产和消费事件变得容易。抽象出事件源,并允许操作人员使用自己选择的消息传递层。 Knative Eventing 旨在满足云原生开发中通用需求, 以提供可组合的方式绑定事件源和事件消费者。其设计目标: Knative Eventing 提供的服务是松散耦合,可独立开发和部署。服务可跨平台使用(如 Kubernetes, VMs, SaaS 或者 FaaS) 事件的生产者和事件的消费者是相互独立的。任何事件的生产者(事件源)可以先于事件的消费者监听之前产生事件,同样事件的消费者可以先于事件产生之前监听事件 支持第三方的服务对接该 Eventing 系统 确保跨服务的互操作性 如上图所示,Eventing 主要由事件源(Event Source)、事件处理(Flow)以及事件消费者(Event Consumer)三部分构成。 事件源(Event Source) 当前支持以下几种类型的事件源: ApiserverSource:每次创建或更新 Kubernetes 资源时,ApiserverSource 都会触发一个新事件 GitHubSource:GitHub 操作时,GitHubSource 会触发一个新事件 GcpPubSubSource: GCP 云平台 Pub/Sub 服务会触发一个新事件 AwsSqsSource:Aws 云平台 SQS 服务会触发一个新事件 ContainerSource: ContainerSource 将实例化一个容器,通过该容器产生事件 CronJobSource: 通过 CronJob 产生事件 KafkaSource: 接收 Kafka 事件并触发一个新事件 CamelSource: 接收 Camel 相关组件事件并触发一个新事件 事件接收/转发(Flow) 当前 Knative 支持如下事件接收处理: 直接事件接收 通过事件源直接转发到单一事件消费者。支持直接调用 Knative Service 或者 Kubernetes Service 进行消费处理。这样的场景下,如果调用的服务不可用,事件源负责重试机制处理。 通过事件通道(Channel)以及事件订阅(Subscriptions)转发事件处理 这样的情况下,可以通过 Channel 保证事件不丢失并进行缓冲处理,通过 Subscriptions 订阅事件以满足多个消费端处理。 通过 brokers 和 triggers 支持事件消费及过滤机制 从 v0.5 开始,Knative Eventing 定义 Broker 和 Trigger 对象,实现了对事件进行过滤(亦如通过 ingress 和 ingress controller 对网络流量的过滤一样)。 通过定义 Broker 创建 Channel,通过 Trigger 创建 Channel 的订阅(subscription),并产生事件过滤规则。 事件消费者(Event Consumer) 为了满足将事件发送到不同类型的服务进行消费, Knative Eventing 通过多个 k8s 资源定义了两个通用的接口: Addressable 接口提供可用于事件接收和发送的 HTTP 请求地址,并通过status.address.hostname字段定义。作为一种特殊情况,Kubernetes Service 对象也可以实现 Addressable 接口 Callable 接口接收通过 HTTP 传递的事件并转换事件。可以按照处理来自外部事件源事件的相同方式,对这些返回的事件做进一步处理 当前 Knative 支持通过 Knative Service 或者 Kubernetes Service 进行消费事件。 另外针对事件消费者,如何事先知道哪些事件可以被消费? Knative Eventing 在最新的 0.6 版本中提供 Registry 事件注册机制, 这样事件消费者就可以事先通过 Registry 获得哪些 Broker 中的事件类型可以被消费。 总结 Knative 使用 Build 提供云原生“从源代码到容器”的镜像构建能力,通过 Serving 部署容器并提供通用的服务模型,同时以 Eventing 提供事件全局订阅、传递和管理能力,实现事件驱动。这就是 Knative 呈现给我们的标准 Serverless 编排框架。 |