Django 优化数据库查询的一些经验
- - 卡瓦邦噶!ORM 帮我们节省了很多工作,基本上不用写 SQL,就可以完成很多 CRUD 操作,而且外键的关联也会自动被 ORM 处理好,使得开发的效率非常高. 我觉得 Django 的 ORM 在 ORM 里面算是非常好用的了,尤其是自带的 Django-admin,可以节省很多工作,甚至比很多公司内部开发的后台界面都要优秀.
ORM 帮我们节省了很多工作,基本上不用写 SQL,就可以完成很多 CRUD 操作,而且外键的关联也会自动被 ORM 处理好,使得开发的效率非常高。我觉得 Django 的 ORM 在 ORM 里面算是非常好用的了,尤其是自带的 Django-admin,可以节省很多工作,甚至比很多公司内部开发的后台界面都要优秀。
但是 ORM 也带来了一些问题,最严重的就是,这些外键关联会去自动 Fetch,导致非常容易写出来 N + 1 查询,加上如果使用 django-rest-framework, Serializer 可以帮助你很方便地去渲染关联的外键,就更容易写出 N + 1 查询了。也是因为这个原因,之前在蚂蚁工作的时候,公司基本上是禁止(有一些小范围的内部项目还是可以使用)使用类似于 Hibernate 这种自动关联外键 ORM 的,都需要手写 SQL map,自己去 Join。但其实,我觉得这是一种非常粗暴的做法,用大量的人力换取降低错误出现的几率。这个问题是非常好解决的,我们只要对接口 Profile,看一下完成一次请求到底进行了哪些 SQL 查询即可,如果发现了 N + 1 就去解决。
这篇文章介绍 Django 中去 debug 和优化数据库查询的一些方法,其实对于其他的语言和框架,也差不多类似,也有同类的工具。
让我们从头开始思考,如何提升网站的性能。首先,最接近于用户的就是前端的代码,我们可以从前端开始 perf,看哪一个页面渲染用的时间最长,是请求 Block 住了,还是前端的组件写的性能差。如果是非常重要的面向用户的页面,可以系统性地使用一些监控工具发现性能问题。如果是对内的,其实只要自己去每一个页面点几下试试就可以发现性能问题了。如果自己没觉得卡顿,基本上就足够了。
对于内部的系统来说,如果前端不是写的出奇的差的话,性能问题一般都是由 API 慢引起的。所以本文就不过多介绍前端性能的优化了。
Django 有一个 Prometheus 的 exporter 库, django-prometheus,可以使用这个库将 metrics 暴露出来,然后在 Grafana 上绘制每一个 view 的 P99/P95 等,发现耗时长的 API,然后针对性地进行优化,去 Debug 到底是慢在了哪里。
Django 的 django-debug-toolbar 是一个非常好用的工具。安装之后,设置好 debug 用的 IP,使用这个 IP 去访问的时候,它会自动对整个请求做 Profile,包括使用的 Cache,Template,Signal 等等。最有用的就是 SQL Profile 了。
它会把一个请求涉及的所有 SQL 都列出来,包括:
如下所示:
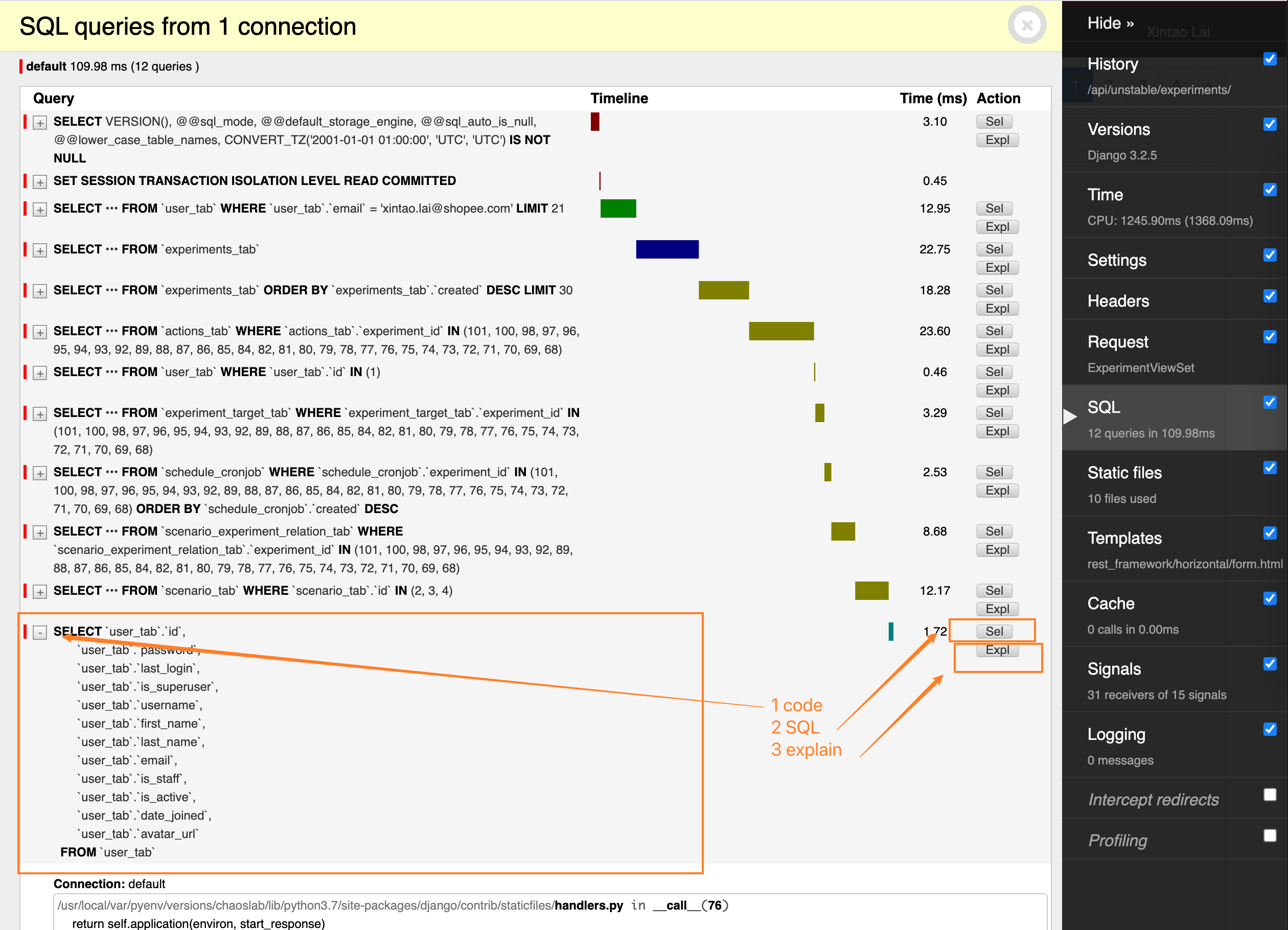
然后就可以针对慢的 API 进行优化了。
N + 1 查询是造成 API 慢的最常见的原因。比如这样一个需求:我们有一个列表页,对于列表中的每一个 Item,都要展示它相关的 Tag。如果使用 djagno-rest-framework 的 Nested relationships 的话,实际的查询会:
这就是 N + 1 查询。
解决的方法很简单,就是使用 Django 的 prefetch_related(),它的原理是使用 in 一次性将所有的外键关联的数据查询出来,然后在内存中使用 Python 做 “join”,这样就只会产生两个查询:
参考一个官方文档中的例子:每一个 Pizze 都有不同的 Topping(浇头?)。
from django.db import models
class Topping(models.Model):
name = models.CharField(max_length=30)
class Pizza(models.Model):
name = models.CharField(max_length=50)
toppings = models.ManyToManyField(Topping)
def __str__(self):
return "%s (%s)" % (
self.name,
", ".join(topping.name for topping in self.toppings.all()),
) 下面这个查询就是一个 N + 1,要先查出来所有的 Pizze,然后对于每一个 Pizza 去查询它的 Toppings:
>>> Pizza.objects.all() ["Hawaiian (ham, pineapple)", "Seafood (prawns, smoked salmon)"...
如果使用 prefetch 的话,就会只有 3 次查询(因为是一个 many-to-many 关系,所以要有一次是查询中间表的):
>>> Pizza.objects.all().prefetch_related('toppings')
注意只能使用 .all()
prefetch 其实是缓存了一个 queryset(), 如果查询条件改变了,Django 就必须重新发起查询。以下这个用法,就不会用到 prefetch 的 cache:
>>> pizzas = Pizza.objects.prefetch_related('toppings')
>>> [list(pizza.toppings.filter(spicy=True)) for pizza in pizzas] 因为 prefetch 已经把所有的数据查询到内存里面了,所以我们应该这么用,就不会触发新的查询了:
>>> pizzas = Pizza.objects.prefetch_related('toppings')
>>> [pizza for pizza in pizzas
if any(topping.spicy==True for topping in pizza.toppings)
]
Prefetch()
prefetch_related() 所接收的参数,除了可以是一个 string 外,也可以是一个 Prefetch() 对象,可以用来更精确地控制 cache 的 queryset. 比如排序:
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas__toppings', queryset=Toppings.objects.order_by('name'))) 也可以一次性 prefetch 多个外键(顺序很重要, 参考文档), Prefetch() 和 string 可以混用:
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas__toppings', queryset=Toppings.objects.order_by('name')),
... "address")
many-to-many 和嵌套外键
对于嵌套的外键,可以用 __ 将 Model 的属性名字联合起来,比如这样:
>>> Restaurant.objects.prefetch_related('pizzas__toppings') 这样 pizzas 和 toppings 都会被 prefetch.
select_related()
select_related() 也是有类似作用的一个功能,只不过他和 prefetch 的区别是:
prefetch_related() 是用 in 然后用代码 joinselect_related() 是用 SQL 直接 join显然, select_related() 触发的查询更少,一次查询就可以解决问题。但是它的功能也有限,不能支持嵌套的外键查询。
prefetch_related_objects()
以上的两个方法是用于 queryset 的,如果是对 object 的话,可以使用这个函数。
比如,我们要查询最近的一个订单关联的数据的话,可以这么使用:
latest_order = self.orders.order_by("-id").first()
models.prefetch_related_objects(
[last_group],
"item",
"user_address",
)
Django 提供了一很实用的装饰器 @cached_property ,用这个替换 @property 的话,一个对象在读取这个 property 的时候只会计算一次,同一个对象在第一次之后来读取这个 property 都会使用缓存。
有点类似于 Python 中的 @lru_cache。
无论是 Cache 还是 prefetch 的方法,都是有一些复杂的。如果前端用户到一些字段,就没有必要一次性返回。
刚开始写 DRF 中的 Serializer 的时候,倾向于每一个 Model 都有一个 Serializer,然后这些 Serializer 都互相关联。最终,导致查询一个列表页的时候,每一个 item 相关的数据,以及这些数据相关的数据,都被一次性展示出来了。即使优化过后也难以维护。
后来总结出来一个比较好的实践,是每一个 Model 都有两个 Serializer:
in 就可以了这样的好处是我们可以按需进行 prefetch,List 页面的 API 只需要 prefetch 直接关联的外键就可以了,Detail 的 API 可以按需进行级联 prefetch. 总体的原则就是尽量避免多重外键的 prefetch.
值得一提的是在 django-rest-framework 中,是可以在同一个 ModelViewSet 里面,针对不同的 API,使用不同的 Serializer 的:
def get_serializer_class(self):
if self.action == "list":
return ExperimentListSerializer
return super().get_serializer_class()
现在存储已经很便宜了,在合适的场景下,可以考虑直接将 fields 多存几份,节省查询。
比如我的一个场景是:一个 group 里面有个并行执行的 Execution,如果所有的 Execution 都执行完了,这个 group 就可以被认为是执行完了。
之前的实现是在 group 上定义一个 is_running 的字段,返回 group.execution_set.filter(is_running=True).exists()。这样每次都需要查询外键。
其实可以在 group 上保存一个 is_running 的字段,然后当 Execution 结束的时候顺便更新 group.is_running. ( Signal 其实不太好维护,我比较喜欢显式调用)。
这样的好处是:
缺点是:
随着数据越来越多,即使开发的环境中发现 API 造成的请求都很少,也很快,但是线上环境跑着跑着可能就有问题了。
所以最好对线上的 SQL 也进行观测。方法很简单,只要将查询时间 >1秒(或者其他时间)的 SQL log 出来就可以了。可以通过针对 Django ORM 设置 logging 配置来完成这件事:
添加一个新的 logger,然后 filter 类似于一下设置:
"filters": {
"slow_sql_above_50ms": {
"()": "django.utils.log.CallbackFilter",
"callback": lambda record: not hasattr(record, "duration")
or record.duration > 0.05, # output slow queries only
},
}, 就可以将 SQL 日志过滤出来,然后只 log 请求时间 >50ms 的。
最后,以 Django 中的一句话作为结尾:
Always profile for your use case!
The post Django 优化数据库查询的一些经验 first appeared on 卡瓦邦噶!.