基于Binlog的实时同步功能——debezium、canel、databus技术选型 | holmofy
- -去年的一篇文章大致地讲了我对MQ的一些认识,事实上Kafka在内的现代MQ,功能远不止这些. 后面整理好自己的思路,肯定会再写一篇文章来讲讲. 这篇文章的主角就是与MQ息息相关的CDC技术. CDC全称叫:change data capture,是一种基于数据库数据变更的事件型软件设计模式. 比如有一张订单表trade,订单每一次变更录入到一张trade_change的队列表.
去年的一篇文章大致地讲了我对MQ的一些认识,事实上Kafka在内的现代MQ,功能远不止这些。后面整理好自己的思路,肯定会再写一篇文章来讲讲。这篇文章的主角就是与MQ息息相关的CDC技术。
CDC全称叫:change data capture,是一种基于数据库数据变更的事件型软件设计模式。
比如有一张订单表trade,订单每一次变更录入到一张trade_change的队列表。然后另外一个调度线程可以消费trade_change这张队列表来做一些数据统计,如每日的付款用户统计、每日的下单用户统计等。
这就是我毕业入职的第一家公司的报表统计逻辑。这个设计在订单量小的时候是看不出问题的,而一旦某一时刻订单量增多。基于MySQL的队列表由于B+树的写入吞吐量不够,导致MySQL CPU经常飙升。比如双十一,618这样的大促,程序员就得在颤颤巍巍中度过。
其次,从MySQL同步到ElaticSearch是根据 last_modify_time时间扫索引增量同步的,这就要求表上必须创建 last_modify_time索引,Scheduler一多也会无形地增加MySQL的读取负担。
B+的写入性能肯定是不如直接顺序写文件的,B+树的本质就是牺牲写性能,换取磁盘上的随机读的查找结构,所以大部分数据库都会设计 Buffer Pool来管理B+树脏页,以避免频繁的随机IO。
同时为了防止Buffer数据丢失同时为了保证事务的ACID,所以就有了 Redo-log来进行崩溃恢复, Undo-log来做未提交事务的撤销。这些日志都是顺序写入,远比B+树的随机写性能高。
Binlog是MySQL 3.23.14引进的, 它包含所有的描述数据库修改的事件——DML(增删改)、DDL(表结构定义与修改)操作。
与InnoDB中的 redo-log、 undo-log不同,binlog和 slow_query_log一样是server层的日志,所以InnoDB和MyISAM等各种存储引擎的数据修改都会记录到这个日志中。
MySQL拥有分层架构,支持可插拔的存储引擎,所以服务层的binlog与 InnoDB引擎的redo-log是不同的两个事物,这也是为什么MySQL支持以
STATEMENT格式直接将sql语句存入binlog。而像PostgreSQL这样的数据库, WAL日志除了作为redo-log用于保证事务的持久性外,WAL日志在Replica过程中也扮演着与MySQL的binlog相同的角色, 但是需要用 Logical Decoding将WAL日志解析成数据流或SQL语句。

对于CDC的架构设计,在大数据量的分布式场景下,我们都是使用binlog来做事件源。
一方面,将binlog复制到Kafka,再由Kafka下游的消费者处理这些事件不影响数据库的核心业务,可以降低系统的耦合度;
另一方面,binlog和Kafka都是基于日志的顺序写入,Kafka的吞吐量远比B+树高,系统的整体性能也能得到改善。
目前基于binlog的CDC技术已经很成熟了,在github上也有很多实现,通过 Change Data Capture、 replication、 binlog等关键词可以搜索到相关项目。在此列举一下:
| Project | Language | Description |
|---|---|---|
alibaba/Canal  | Java | 阿里巴巴 MySQL binlog 增量订阅&消费组件 |
debezium/debezium  | Java | Debezium is an open source distributed platform for change data capture. Replicates from MySQL to Kafka. Uses mysql-binlog-connector-java. Kafka Connector. A funded project supported by Redhat with employees working on it full time. |
linkedin/databus  | Java | Precursor to Kafka. Reads from MySQL and Oracle, and replicates to its own log structure. In production use at LinkedIn. No Kafka integration. Uses Open Replicator. |
zendesk/Maxwell  | Java | Reads MySQL event stream, output events as JSON. Parses ALTER/CREATE TABLE/etc statements to keep schema in sync. Written in java. Well maintained. |
noplay/python-mysql-replication  | Python | Pure python library that parses MySQL binary logs and lets you process the replication events. Basically, the python equivalent of mysql-binlog-connector-java |
shyiko/mysql-binlog-connector-java  | Java | Library that parses MySQL binary logs and calls your code to process them. Fork/rewrite of Open Replicator. Has tests. |
confluentinc/bottledwater-pg  | C | Change data capture from PostgreSQL into Kafka |
uber/storagetapper  | Go | StorageTapper is a scalable realtime MySQL change data streaming, logical backup and logical replication service |
moiot/gravity  | Go | A Data Replication Center |
whitesock/open-replicator  | Java | Open Replicator is a high performance MySQL binlog parser written in Java. It unfolds the possibilities that you can parse, filter and broadcast the binlog events in a real time manner. |
mardambey/mypipe  | Scala | Reads MySQL event stream, and emits events corresponding to INSERTs, DELETEs, UPDATEs. Written in Scala. Emits Avro to Kafka. |
Yelp/mysql_streamer  | Python | MySQLStreamer is a database change data capture and publish system. It’s responsible for capturing each individual database change, enveloping them into messages and publishing to Kafka. |
actiontech/dtle  | Go | Distributed Data Transfer Service for MySQL |
krowinski/php-mysql-replication  | PHP | Pure PHP Implementation of MySQL replication protocol. This allow you to receive event like insert, update, delete with their data and raw SQL queries. |
dianping/puma  | Java | 本系统还会实现数据库同步(同构和异构),以满足数据库冗余备份,数据迁移的需求。 |
JarvusInnovations/Lapidus  | Javascript | Streams data from MySQL, PostgreSQL and MongoDB as newline delimited JSON. Can be run as a daemon or included as a Node.js module. |
这里只讨论Java语言的几个实现。首先 whitesock/open-replicator和 shyiko/mysql-binlog-connector-java是专门用来解析MySQL binlog的库,后者也是在前者的基础上重构的。 debezium/debezium、 linkedin/databus、 zendesk/Maxwell三个中间件binlog解析都是基于这两个库。
优点:
缺点:
优点:
缺点:
有意思的是阿里开源的 Flink流处理系统也是使用Debezium来做CDC,当然它还支持Canel、Maxwell
Kafka创始人创办的 confluentinc刚开始开源了 bottledwater-pg,最后也投入了debezium的怀抱,有官方的认可。
优点:
缺点:
Kafka最早是 Jay Kreps在领英创建并开源的,可能是Jay Kreps觉得Kafka在大数据领域大有可图,所以就带着Linkedin的几个工程师一起创立了 Confluent专注于Kafka生态的开发与维护。
在Kafka文档 Log-Compact一节可以看到这段话:
This functionality is inspired by one of LinkedIn’s oldest and most successful pieces of infrastructure—a database changelog caching service called Databus. Unlike most log-structured storage systems Kafka is built for subscription and organizes data for fast linear reads and writes. Unlike Databus, Kafka acts as a source-of-truth store so it is useful even in situations where the upstream data source would not otherwise be replayable.
可以看出Databus是Linkedin非常老的一个基础服务,Kafka的Log Compact的一些设计也源自于Databus。
优点:
缺点:
文档是英文的,不过好在maxwell相对简单。
没啥明显缺点。非要说个缺点,就是和前三者比身份不够显赫,zendesk这家美国公司没怎么听过。
综合下来,Debezium是最佳选择。
要使用debezium需要 预先对mysql服务进行配置。
1)创建单独的用户,并授予debezium需要的权限
1 | mysql>CREATEUSER'user'@'localhost'IDENTIFIEDBY'password'; |
MySQL提供的权限: https://dev.mysql.com/doc/refman/8.0/en/privileges-provided.html
debezium需要几个权限的作用:
| Keyword | Description |
|---|---|
SELECT | SELECT查询权限。只被用在初始化阶段。 |
RELOAD | 执行 FLUSH语句清除重新加载内部缓存。只被用在初始化阶段。 |
SHOW DATABASES | 执行 SHOW DATABASE语句。只被用在初始化阶段。 |
REPLICATION SLAVE | 读取MySQL binlog。 |
REPLICATION CLIENT | 执行 SHOW MASTER STATUS、 SHOW SLAVE STATUS、 SHOW BINARY LOGS等语句。 |
2)开启MySQL服务的binlog功能
1 | server-id=223344 |
各项配置的作用:
| Property | Description |
|---|---|
server-id | 在MySQL集群中每个server和replication的 server-id必须是唯一的。Debezium是作为MySQL的replication,启动后也会分配一个 server-id给debezium-connector。 |
log_bin | binlog文件的前缀 |
binlog_format | binlog-format必须设置成 ROW模式。 |
binlog_row_image | binlog_row_image必须设置成 FULL。 ROW模式下binlog需要记录所有的列。 |
expire_logs_days | binlog的过期时间。默认位 0, 意味着不会自动删除。这个值可根据自己的环境需求进行设置。 |
mysql的 binlog有三种模式:
STATEMENT模式只记录SQL语句,从节点通过执行同步过来的sql在从库中再执行一遍。STATEMENT模式的问题是有些语句(比如update t set num=num+1 limit 1)可能会产生不一致性,而且STATEMENT模式下sql发给异构系统将会无法使用。
ROW模式会直接复制修改的数据行,但是有可能会导致日志量过大,比如执行一条update t set num=num+1,修改了一万行就会有一万行日志,肯定没有STATEMENT模式来的快。
MIXED模式,则将两者结合,默认情况下使用statement,某些情况会切换为基于行的复制。
具体可以参考 这个回答
还有几项可选配置项:
- 开启全局事务ID(GTIDs)方便确认主从备份切换时之间的数据一致性。MySQL有主从切换就不能用binlog物理位置来标识binlog消费offset了,此时需要用 全局的gtid。
- 配置MySQL会话超时时间用于大表的快照读阶段。
- 开启原始SQL语句的记录用于查看每条binlog记录的原始SQL。
1)下载Debezium: https://debezium.io/releases/
2)配置Kafka-connect插件路径,并将Debezimu插件解压到该目录
1 | plugin.path=/kafka/connect |
3)启动Kafka-connect进程:
Kafka-connect可以用 单机版( standalone)和分布式版( distributed)两种启动方式:
standalone模式下,启动时直接提供 properties文件来创建Connector任务。distributed模式下,提供 REST接口对Connector任务进行增删改查。在 distributed模式下可以,调用 POST /connectors接口创建Debezium的Connector任务,任务的基本配置如下:
1 | { |
这个配置主要是数据库的用户名密码,需要同步的数据库和相关数据表,以及kafka地址和数据库schema变更存储的topic。
Debezium-Connector的所有配置: https://debezium.io/documentation/reference/1.4/connectors/mysql.html#mysql-connector-properties
binlog的 ROW模式下类似于csv是没有shema的,我们将 row_image设置成full模式,不管update操作只涉及几列,都会把完整的行数据写入到binlog。
数据库客户端查询数据库的时候,客户端拿到的都是数据库当前的schema。因为schema随时可以改变,这意味着主从备份的时候,debezium不能只使用当前的schema,因为debezium可能正在处理较旧的事件。
比如,有一张trade_info表,在某个时间点T添加了payment字段,在T之前的binlog是没有payment字段的,T之后的binlog才有payment。那Debezium生成事件也应该是在T之前有payment字段,T之后没有payment字段。
MySQL在binlog中不仅包含行级修改,还包括了数据库的DDL语句。当Debezium的Connector读取binlog并遇到这些DDL语句时,它会解析这些DDL并更新内存中每个表shema。Debezium使用这个shema就能标识每次增删改操作的结构从而生成事件。
崩溃或正常重启后,怎么还原schema,如果使用数据库当前的schema会怎样呢:
很明显,不能直接查数据库当前的schema来为之前的binlog生成事件。Debezium和Canal都有自己的解决方案:
Debezium会把所有DDL语句以及DDL在binlog的位置单独存在一个 history的topic中,这个topic可以用 database.history.kafka.topic进行配置。
当Debezium的Connector崩溃或正常停止重启后,Connector重新从原来的位置读取binlog。但是存在内存里的schema已经没有了,所以它会重新解析history中的DDL语句重建表结构。
alibaba/canal提供了 TableMetaTSDB的功能可以存储表结构的时序数据。
因为Debezium会重新解析history topic的DDL语句,我们希望DDL语句能按正常顺序解析,但是Kafka无法保证多个partition的消费顺序,所以history的topic的partition个数必须设置成1。
Debezium不希望用户直接使用history topic。因为里面包含了binlog中的所有ddl语句。
如果用户想要消费自己关心的表的DDL语句,Debezium提供了 schema change topic,这个topic名字被命名为 serverName,这个serverName通过 database.server.name配置。
debezium配置起来还是比较简单的,但是这么复杂的项目,坑还是比较多的。
Debezium的Connector第一次启动时,会给你的数据库执行一次 快照初始化。
因为对于老项目,早期的binlog肯定已经被删掉了,这个时候Debezium会帮你把数据库的所有数据都写到Kafka里,这次快照之后的增删改操作通过解析binlog写入kafka。这也是为什么Debezium需要获取数据库 SELECT权限的原因。
但是快照读有这么几个问题:
SELECT * FROM table扫描全表实现的,没有记录进度,非常粗暴。可以通过
snapshot.locking.mode属性配置是否获取全局读锁,snapshot.locking.mode=none即可关闭。
snapshot只适合在备份从库上执行,否则可能会影响正常用户的使用,通过 snapshot.mode可以对初始化进行配置,这个选项支持以下几个配置值:
initial(default)- 只有当binlog的offset没有记录的时候才会执行一次快照初始化。
when_needed- 有需要时就会执行,比如第一次offset没有记录,或者Connector停了很久早期的binlog被删掉了,当前的offset已经不可用了,或者GTID对不上的时候。
never- 从不执行初始化。第一次启动Connector时就从binlog头部开始读取。需要注意,这种配置需要binlog包含所有的历史记录。
schema_only- Connector初始化时只读取表的 schame而不读取数据。如果你只需要Connector启动后的数据库变更,那这个配置很有用。
schema_only_recovery- 用于恢复重启后丢失的schema, 但是这个只能用在自上次提交binlog-offset后,schema没有发生任何变更。
initial_only- 这个配置在文档里没有, 代码里可以看到,这个是只用来执行快照的。
用一句话总结一下:
initial先全量后增量同步,schema_only和never是只增量同步,initial_only是只全量同步。
Debezium默认的行为是将一张表上的 INSERT、 UPDATE、 DELETE操作记录到一个topic。Topic命名规则是 <serverName>.<databaseName>.<tableName>
如果进行分库了,比如 server0上有 db01和 db02两个逻辑库, server1上有 db11和 db12两个逻辑库,这四个逻辑库上都有一张 order表。那此时就会有4个topic。
如果我们想把它们路由到同一个topic上,就需要用到 Kafka-Connect提供的SMT功能了:
1 | transforms=route |
Kafka-Connect提供了一个 RegexRouter、 TimestampRouter、 MessageTimestampRouter几个SMT让我们修改数据存入的topic。这里的RegexRouter,允许我们用正则表达式来对 Debezium默认的topic进行修改。
对于MySQL中的 decimal类型的数据,Java里会转成 BigDecimal,但是以json格式存入kafka的时候就会丢失精度。
毕竟json出自JS, JS中只支持number数值类型,对应到Java就是double类型。
Debezium支持 decimal.handling.mode选项可以将decimal配置成 string类型。
Debezium底层的binlog解析用的是 shyiko/mysql-binlog-connector-java。这中间做了很多转换:
| mysql(Asia/Shanghai) | binlog-connector | debezium | debezium schema |
|---|---|---|---|
| date (2021-01-28) | LocalDate (2021-01-28) | Integer (18655) | io.debezium.time.Date |
| time (17:29:04) | Duration (PT17H29M4S) | Long (62944000000) | io.debezium.time.MicroTime |
| timestamp (2021-01-28 17:29:04) | ZonedDateTime (2021-01-28T09:29:04Z) | String (2021-01-28T09:29:04Z) | io.debezium.time.ZonedTimestamp |
| datetime (2021-01-28 17:29:04) | LocalDateTime (2021-01-28T17:29:04) | Long (1611854944000) | io.debezium.time.Timestamp |
date类型,最后在Debezium中会调用 LocalDate.toEpochDay转成了基于1970年的天数。
time类型,在binlog解析库中,被转成了Duration,在Debezium中最后被转成了毫秒值。
timestamp类型,最后在Debezium中被转成了一个ISO格式的字符串,但是时区默认是UTC时区。
datetime类型,最后在Debezium中被转成了一个long类型,时区是写死的UTC时区。
文档里有MySQL时间类型与存入Kafka类型的映射表
总之,Debezium时间的处理混乱不堪。所以我为Debezium写了一个 datetime-converter的补丁可以将这四种类型转成字符串。配置如下:
1 | converters=datetime |
Debezium会生成5种事件:
createevents:对应MySQL种的INSERT语句。
1 | { |
此时payload种的before字段为null,after字段为新增的记录值。
updateevents:对应MySQL种的UPDATE语句。
1 | { |
此时payload中,before为更新前的数据,after为更新后的数据。
Primary key updates:修改主键的操作,会生成一个 DELETE事件和 CREATE事件:
DELETE事件会有 __debezium.newkey的消息头。这个值是更新后的新主键。CREATE事件会有 __debezium.oldkey的消息头。这个值是更新前的老主键。deleteevents:对应MySQL的DELTE语句。
1 | { |
此时payload中,before为删除前的数据,after为null。
Tombstone events:Debezium会为删除操作生成一条key与DELETE事件相同、value为null的空消息(墓碑事件)。
墓碑事件主要用于 Kafka的compact——Kafka会删除具有相同key的早期事件。但是要让Kafka删除所有具有相同key的消息,需要将消息指设置成null。
需要特别注意,墓碑事件的消息value为null,需要为这个事件做特殊处理。
Kafka-Connect为了保证每条消息是可以自我描述的,所以都会带schema。如果我们使用了 JsonConverter进行序列化,默认情况下,kafka中的消息格式是这样的:
1 | { |
这里面的schema会包含下面payload里每个字段的类型解释,会导致Kafka中存储的消息非常臃肿。可以在Kafka-Connect中将Key和Value的schema禁用掉:
1 | key.converter=org.apache.kafka.connect.json.JsonConverter |
更好的解决方案是使用中心化的Schema Registry。Debezium也推荐使用这种方式。
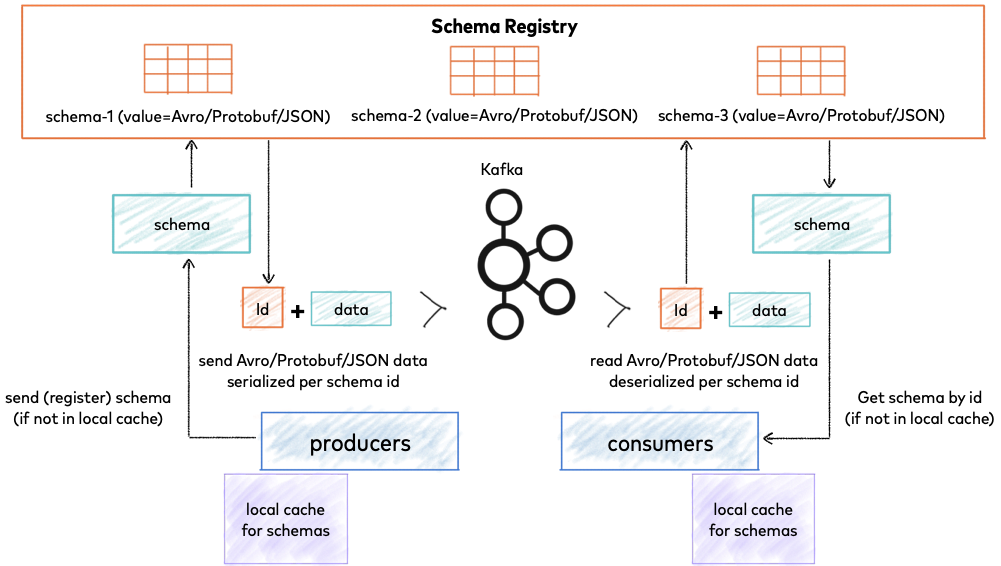
在github搜索 schema registry关键词查找相关项目。 Debezium在文档中推荐 Apicurio API and Schema Registry和 Confluent Schema Registry这两种SchemaRegistry。
没有shema的时候,Debezium默认生成的数据格式是这样的:
1 | { |
消息体中 before表示变更前的数据, after表示变更后的数据, source表示来源于哪个数据库、哪张表、哪个事务(GTID)。
为了方便与其他Connector集成,比如让 kafka-connect-jdbc把消息都写到另一个数据库中。那这个时候我们只想要 after里面的数据了。
Debezium提供了一个 Event-Flat的SMT,我们只需要和上面的RegexRouter一样配置一下就可以了:
1 | transforms=unwrap,... |
那如果是删除操作呢,删除操作会生成两个事件,一个delete事件有before没有after,还有一个和delete事件key相同的墓碑事件消息体为null。ExtractNewRecordState可以配置怎么处理 delete记录:
1 | transforms=unwrap,... |
delete.handling.mode指定delete记录的处理模式,默认为 drop也就是delete记录将会被ExtractNewRecordState丢弃。 drop.tombstones指定要不要丢弃墓碑事件。
更多配置可以参考 官方文档
kafka broker本身有个配置 auto.create.topics.enable默认为true——当发送消息到一个不存在的topic时,kafka会自动创建这个topic,这些自动创建的topic会使用 num.partitions和 default.replication.factor指定的partition数和replicas数创建topic。生产环境一般是不建议使用kafka broker中的自动创建主题的,因为这可能会带来很大的维护成本,我们希望不同情况使用不同的主题配置。
另外,kafka-connect启动时默认会创建三个 connect内部使用的topic,这三个topic名字由 config.storage.topic、 offset.storage.topic、 status.storage.topic三个配置指定,它们分别存储connector的配置和offset以及当前的状态。
如果想要对这三个自动创建的topic进行一些配置,可以参考 connect的文档
如果你是手动创建需要注意:
offset和kafka内建的 __consumer_offsets类似,如果要支持更大的kafka-connect集群,可以把partition设大一点。
这三个topic的 cleanup.policy都必须设置成compacted模式。
如果是source connector内部要自动创建topic,可以使用connector的一些配置,具体可以参考:
Configuring Auto Topic Creation for Source Connectors
Customization of Kafka Connect automatic topic creation
Refs:
^ Debezium Document: https://debezium.io/documentation/reference/1.4/
^ Debezium FAQ: https://debezium.io/documentation/faq/
^ Confluent Document: https://docs.confluent.io/platform/current/overview.html
^ Aliyun DTS服务原理: https://www.alibabacloud.com/help/zh/doc-detail/176085.htm
^ Aliyun DTS应用场景: https://www.alibabacloud.com/help/zh/doc-detail/176086.htm