前言: 创建一个可随意插拔的插件式前端监控系统
一、数据采集
1.异常数据
1.1 静态资源异常
使用window.addEventListener('error',cb)
由于这个方法会捕获到很多error,所以我们要从中筛选出静态资源文件加载错误情况,这里只监控了js、css、img
// 捕获静态资源加载失败错误 js css img
window.addEventListener('error', e => {
const target = e.targetl
if (!target) return
const typeName = e.target.localName;
let sourceUrl = "";
if (typeName === "link") {
sourceUrl = e.target.href;
} else if (typeName === "script" || typeName === "img") {
sourceUrl = e.target.src;
}
if (sourceUrl) {
lazyReportCache({
url: sourceUrl,
type: 'error',
subType: 'resource',
startTime: e.timeStamp,
html: target.outerHTML,
resourceType: target.tagName,
paths: e.path.map(item => item.tagName).filter(Boolean),
pageURL: getPageURL(),
})
}
}, true)
1.2 js错误
通过 window.onerror 获取错误发生时的行、列号,以及错误堆栈
生产环境需要上传打包后生成的map文件,利用source-map 对压缩后的代码文件和行列号得出未压缩前的报错行列数和源码文件
// parseErrorMsg.js
const fs = require('fs');
const path = require('path');
const sourceMap = require('source-map');
export default async function parseErrorMsg(error) {
const mapObj = JSON.parse(getMapFileContent(error.url))
const consumer = await new sourceMap.SourceMapConsumer(mapObj)
// 将 webpack://source-map-demo/./src/index.js 文件中的 ./ 去掉
const sources = mapObj.sources.map(item => format(item))
// 根据压缩后的报错信息得出未压缩前的报错行列数和源码文件
const originalInfo = consumer.originalPositionFor({ line: error.line, column: error.column })
// sourcesContent 中包含了各个文件的未压缩前的源码,根据文件名找出对应的源码
const originalFileContent = mapObj.sourcesContent[sources.indexOf(originalInfo.source)]
return {
file: originalInfo.source,
content: originalFileContent,
line: originalInfo.line,
column: originalInfo.column,
msg: error.msg,
error: error.error
}
}
function format(item) {
return item.replace(/(\.\/)*/g, '')
}
function getMapFileContent(url) {
return fs.readFileSync(path.resolve(__dirname, `./dist/${url.split('/').pop()}.map`), 'utf-8')
}
1.3 自定义异常
通过console.error打印出来的,我们将其认为是自定义错误
使用 window.console.error 上报自定义异常信息
1.4 接口异常
- 当状态码异常时,上报异常
- 重写 onloadend 方法,当其 response 对象中 code 值不为 '000000' 时上报异常
- 重写 onerror 方法,当网络中断时无法触发 onload(end) 事件,会触发 onerror, 此时上报异常
1.5 监听未处理的promise错误
当Promise 被reject 且没有reject 处理器的时候,就会触发 unhandledrejection 事件
使用 window.addEventListener('unhandledrejection',cb)
2.性能数据
2.1 FP/FCP/LCP/CLS
chrome 开发团队提出了一系列用于检测网页性能的指标:
- FP(first-paint),从页面加载开始到第一个像素绘制到屏幕上的时间
- FCP(first-contentful-paint),从页面加载开始到页面内容的任何部分在屏幕上完成渲染的时间
- LCP(largest-contentful-paint),从页面加载开始到最大文本块或图像元素在屏幕上完成渲染的时间
- CLS(layout-shift),从页面加载开始和其 生命周期状态变为隐藏期间发生的所有意外布局偏移的累积分数
其中,前三个性能指标都可以直接通过 PerformanceObserver (PerformanceObserver 是一个性能监测对象,用于监测性能度量事件 )来获取。而CLS 则需要通过一些计算。
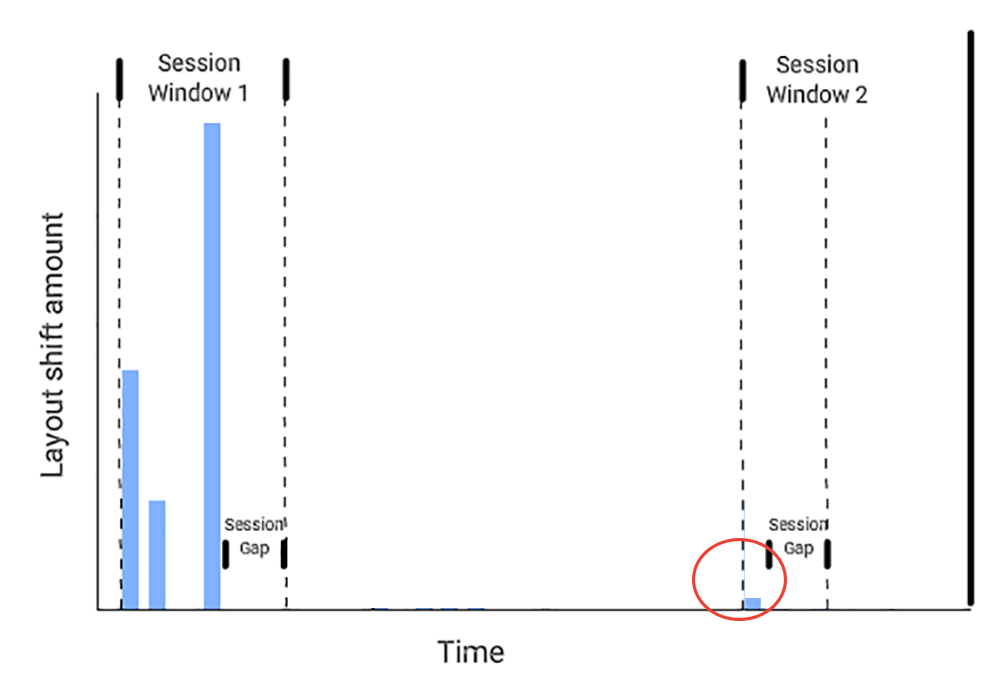
在了解一下计算方式之前,我们先了解一下会话窗口的概念:一个或多个布局偏移间,它们之间有少于1秒的时间间隔,并且第一个和最后一个布局偏移时间间隔上限为5秒,超过5秒的布局偏移将被划分到新的会话窗口。
Chrome 速度指标团队在完成 大规模分析后,将 所有会话窗口中的偏移累加最大值用来反映页面布局最差的情况(即CLS)。
如下图:会话窗口2只有一个微小的布局偏移,则会话窗口2会被忽略,CLS只计算会话窗口1中布局偏移的总和。
2.2 DOMContentLoaded事件 和 onload 事件
- DOMContentLoaded: HTML文档被加载和解析完成。在文档中没有脚本的情况下,浏览器解析完文档便能触发DOMContentLoaded;当文档中有脚本时,脚本会阻塞文档的解析,而脚本需要等位于脚本前面的css加载完才能执行。但是在任何情况下,DOMContentLoaded 都不需要等图片等其他资源的解析。
- onload: 需要等页面中图片、视频、音频等其他所有资源都加载后才会触发。
为什么我们在开发时强调把css放在头部,js放在尾部?
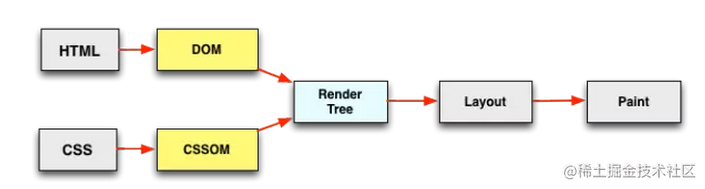
首先文件放置顺序决定下载的优先级,而浏览器为了避免样式变化导致页面重排or重绘,会阻塞内容的呈现,等所有css加载并解析完成后才一次性呈现页面内容,在此期间就会出现“白屏”。
而现代浏览器为了优化用户体验,无需等到所有HTML文档都解析完成才开始构建布局渲染树,也就是说浏览器能够渲染不完整的DOM tree和cssom,尽快减少白屏时间。
假设我们把js放在头部,js会阻塞解析dom,导致FP(First Paint)延后,所以我们将js放在尾部,以减少FP的时间,但不会减少 DOMContentLoaded 被触发的时间。
2.3 资源加载耗时及是否命中缓存情况
通过 PerformanceObserver 收集,当浏览器不支持 PerformanceObserver,还可以通过 performance.getEntriesByType(entryType) 来进行降级处理,其中:
- Navigation Timing 收集了HTML文档的性能指标
- Resource Timing 收集了文档依赖的资源的性能指标,如:css,js,图片等等
这里不统计以下资源类型:
- beacon: 用于上报数据,不统计
- xmlhttprequest:单独统计
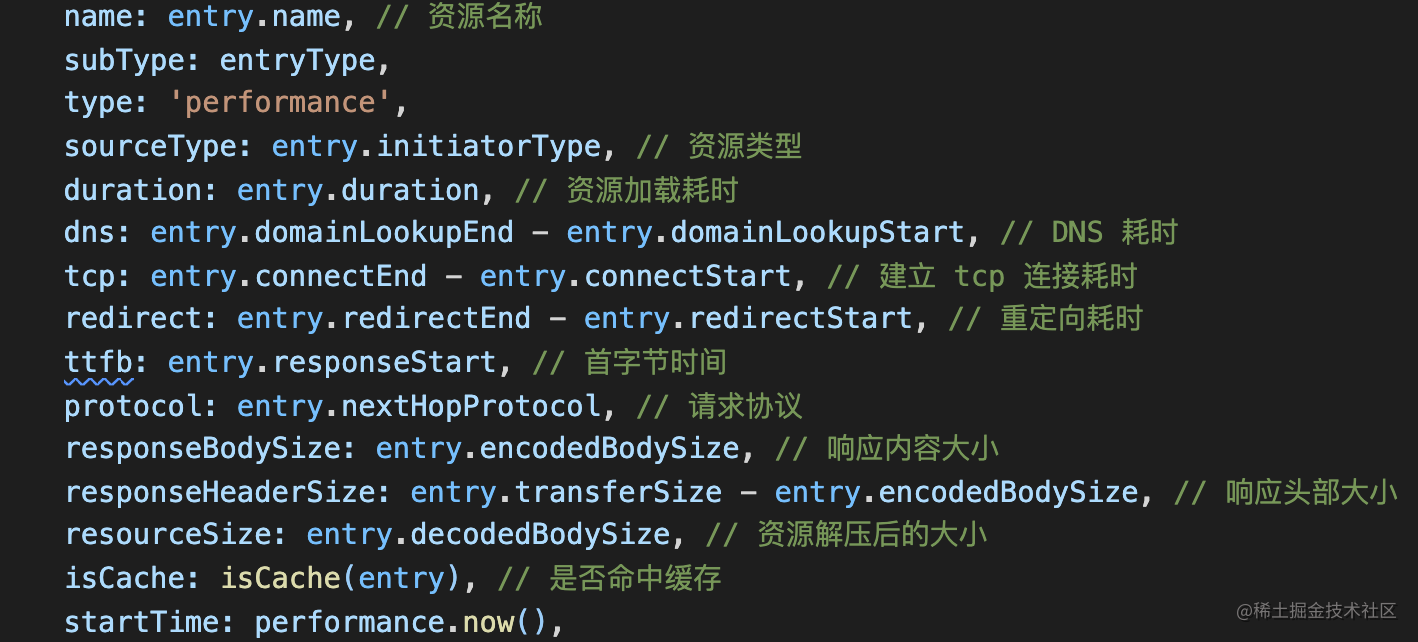
我们能够获取到资源对象的如下信息:
使用performance.now()精确计算程序执行时间:
- performance.now() 与 Date.now() 不同的是,返回了以微秒(百万分之一秒)为单位的时间,更加精准。并且与 Date.now() 会受系统程序执行阻塞的影响不同,performance.now() 的时间是以恒定速率递增的,不受系统时间的影响(系统时间可被人为或软件调整)。
- Date.now() 输出的是 UNIX 时间,即距离 1970 的时间,而 performance.now() 输出的是相对于 performance.timing.navigationStart(页面初始化) 的时间。
- 使用 Date.now() 的差值并非绝对精确,因为计算时间时受系统限制(可能阻塞)。但使用 performance.now() 的差值,并不影响我们计算程序执行的精确时间。
判断该资源是否命中缓存:
在这些资源对象中有一个 transferSize 字段,它表示获取资源的大小,包括响应头字段和响应数据的大小。如果这个值为 0,说明是从缓存中直接读取的(强制缓存)。如果这个值不为 0,但是 encodedBodySize 字段为 0,说明它走的是协商缓存(encodedBodySize 表示请求响应数据 body 的大小)。不符合以上条件的,说明未命中缓存。
2.4 接口请求耗时以及接口调用成败情况
对XMLHttpRequest 原型链上的send 以及open方法进行改写
import { originalOpen, originalSend, originalProto } from '../utils/xhr'
import { lazyReportCache } from '../utils/report'
function overwriteOpenAndSend() {
originalProto.open = function newOpen(...args) {
this.url = args[1]
this.method = args[0]
originalOpen.apply(this, args)
}
originalProto.send = function newSend(...args) {
this.startTime = Date.now()
const onLoadend = () => {
this.endTime = Date.now()
this.duration = this.endTime - this.startTime
const { duration, startTime, endTime, url, method } = this
const { readyState, status, statusText, response, responseUrl, responseText } = this
console.log(this)
const reportData = {
status,
duration,
startTime,
endTime,
url,
method: (method || 'GET').toUpperCase(),
success: status >= 200 && status < 300,
subType: 'xhr',
type: 'performance',
}
lazyReportCache(reportData)
this.removeEventListener('loadend', onLoadend, true)
}
this.addEventListener('loadend', onLoadend, true)
originalSend.apply(this, args)
}
}
export default function xhr() {
overwriteOpenAndSend()
}
二、数据上报
1. 上报方法
采用 sendBeacon 和 XMLHttpRequest 相结合的方式
为什么要使用sendBeacon?
统计和诊断代码通常要在 unload 或者 beforeunload (en-US) 事件处理器中发起一个同步 XMLHttpRequest 来发送数据。同步的 XMLHttpRequest 迫使用户代理延迟卸载文档,并使得下一个导航出现的更晚。下一个页面对于这种较差的载入表现无能为力。
navigator.sendBeacon() 方法可用于通过HTTP将少量数据异步传输到Web服务器,同时不会延迟页面的卸载或影响下一导航的载入性能。这就解决了提交分析数据时的所有的问题:数据可靠,传输异步并且不会影响下一页面的加载。
2. 上报时机
- 先缓存上报数据,缓存到一定数量后,利用 requestIdleCallback/setTimeout 延时上报。
- 在即将离开当前页面(刷新或关闭)时上报 (onBeforeUnload )/ 在页面不可见时上报(onVisibilitychange,判断document.visibilityState/ document.hidden 状态)