实践k8s istio熔断 - fat_girl_spring - 博客园
- -熔断主要是无感的处理服务异常并保证不会发生级联甚至雪崩的服务异常. 在微服务方面体现是对异常的服务情况进行快速失败,它对已经调用失败的服务不再会继续调用,如果仍需要调用此异常服务,它将立刻返回失败. 与此同时,它一直监控服务的健康状况,一旦服务恢复正常,则立刻恢复对此服务的正常访问. 这样的快速失败策略可以降低服务负载压力,很好地保护服务免受高负载的影响.
熔断主要是无感的处理服务异常并保证不会发生级联甚至雪崩的服务异常。在微服务方面体现是对异常的服务情况进行快速失败,它对已经调用失败的服务不再会继续调用,如果仍需要调用此异常服务,它将立刻返回失败。与此同时,它一直监控服务的健康状况,一旦服务恢复正常,则立刻恢复对此服务的正常访问。这样的快速失败策略可以降低服务负载压力,很好地保护服务免受高负载的影响。
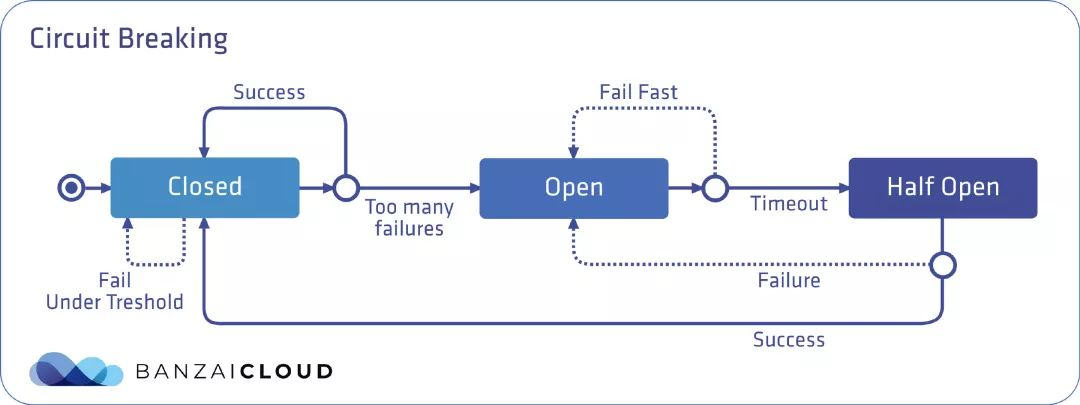
一个熔断器可以有三种状态:关闭、打开和半开,默认情况下处于关闭状态。在关闭状态下,无论请求成功或失败,到达预先设定的故障数量阈值前,都不会触发熔断。而当达到阈值时,熔断器就会打开。当调用处于打开状态的服务时,熔断器将断开请求,这意味着它会直接返回一个错误,而不去执行调用。通过在客户端断开下游请求的方式,可以在生产环境中防止级联故障的发生。在经过事先配置的超时时长后,熔断器进入半开状态,这种状态下故障服务有时间从其中断的行为中恢复。如果请求在这种状态下继续失败,则熔断器将再次打开并继续阻断请求。否则熔断器将关闭,服务将被允许再次处理请求。
Hystrix是Netflix OSS的一部分,是微服务领域的领先的熔断工具。Hystrix可以被视为白盒监控工具,而Istio可以被视为黑盒监控工具,主要是因为Istio从外部监控系统并且不知道系统内部如何工作。另一方面,每个服务中有Hystrix来获取所需的数据。
Istio是无缝衔接服务,istio可以在不更改应用程序代码的情况下配置和使用。Hystrix的使用需要更改每个服务来引入Hystrix libraries。
Istio提高了网格中服务的可靠性和可用性。但是,应用程序需要处理错误并有一定的fall
back行为。例如当负载平衡池中的所有服务实例都出现异常时,Envoy将返回HTTP 503。当上游服务返回 HTTP 503
错误,则应用程序需要采取回退逻辑。与此同时,Hystrix也提供了可靠的fall back实现。它允许拥有所有不同类型的fall
backs:单一的默认值、缓存或者去调用其他服务。
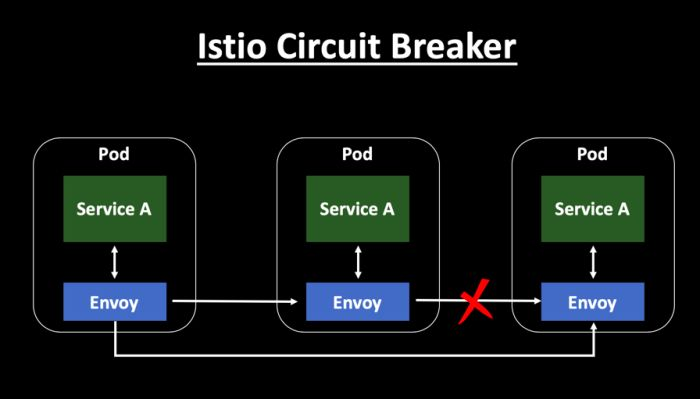
envoy对应用程序来说几乎完全无感和透明。Hystrix则必须在每个服务调用中嵌入Hystrix库。
Istio的熔断应用几乎无语言限制,但Hystrix主要针对的是Java应用程序。
Istio是使用了黑盒方式来作为一种代理管理工具。它实现起来很简单,不依赖于底层技术栈,而且可以在部署后也可以进行配置和修改。Hystrix需要在代码级别处理断路器,可以设置级联和一些附加功能,它需要在开发阶段时做出降级决策,后期优化配置成本高。
Istio无需对代码进行任何更改就可以为应用增加熔断和限流功能。Istio中熔断和限流在DestinationRule的CRD资源的TrafficPolicy中设置,一般设置连接池(ConnectionPool)限流方式和异常检测(outlierDetection)熔断方式。两者ConnectionPool和outlierDetection各自配置部分参数,其中参数有可能存在对方的功能,并没有很严格的区分出来,如主要进行限流设置的ConnectionPool中的maxPendingRequests参数,最大等待请求数,如果超过则也会暂时的熔断。
连接池(ConnectionPool)设置
ConnectionPool可以对上游服务的并发连接数和请求数进行限制,适用于TCP和HTTP。ConnectionPool又称之是限流。
官方定义的属性

设置在DestinationRule中的配置如下图:
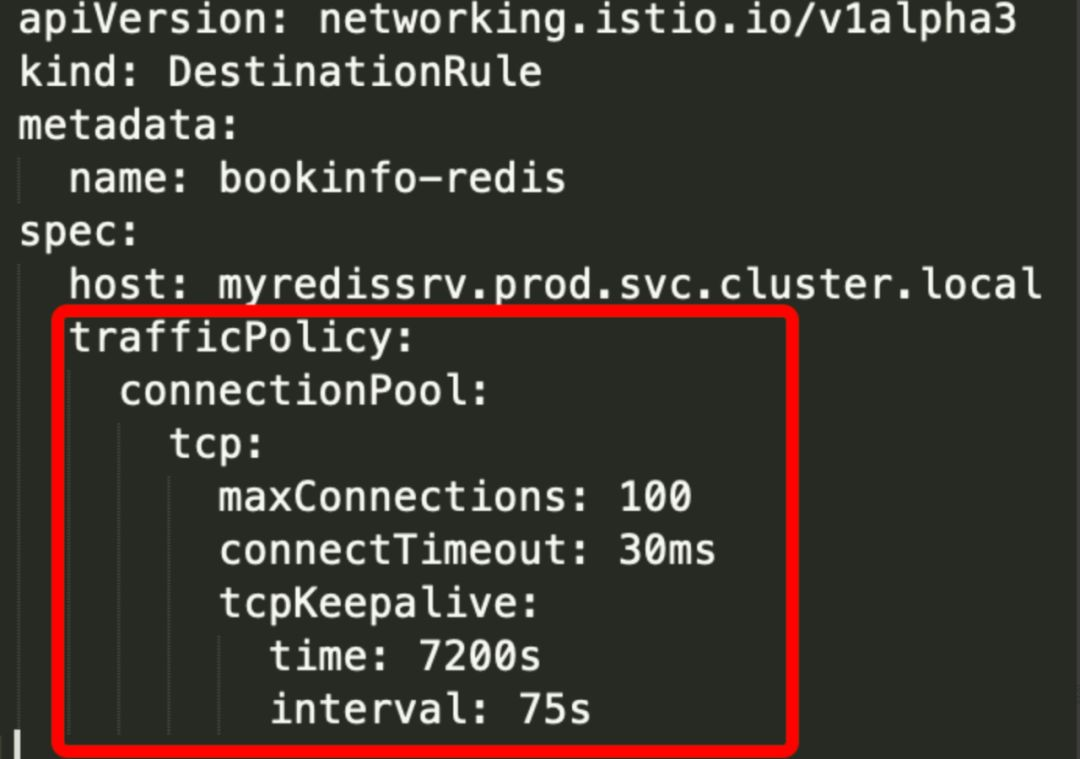
连接池相关参数解析
TCP设置
Tcp连接池设置http和tcp上游连接的设置。相关参数设置如下:

maxConnections:到目标主机的HTTP1/TCP最大连接数量,只作用于http1.1,不作用于http2,因为后者只建立一次连接。
connectTimeout:tcp连接超时时间,默认单位秒。也可以写其他单位,如ms。
tcpKeepalive:如果在套接字上设置SO_KEEPALIVE可以确保TCP 存活
TCP的TcpKeepalive设置:
Probes:在确定连接已死之前,在没有响应的情况下发送的keepalive探测的最大数量。默认值是使用系统级别的配置(除非写词参数覆盖,Linux默认值为9)。
Time:发送keep-alive探测前连接存在的空闲时间。默认值是使用系统的配置(除非写此参数,Linux默认值为7200s(即2小时)。
interval:探测活动之间的时间间隔。默认值是使用系统的配置(除非被覆盖,Linux默认值为75秒)。
HTTP设置
http连接池设置用于http1.1/HTTP2/GRPC连接。
http1MaxPendingRequests:http请求pending状态的最大请求数,从应用容器发来的HTTP请求的最大等待转发数,默认是1024。
http2MaxRequests:后端请求的最大数量,默认是1024。
maxRequestsPerConnection:在一定时间内限制对后端服务发起的最大请求数,如果超过了这个限制,就会开启限流。如果将这一参数设置为 1 则会禁止 keepalive 特性;
idleTimeout:上游连接池连接的空闲超时。空闲超时被定义为没有活动请求的时间段。如果未设置,则没有空闲超时。当达到空闲超时时,连接将被关闭。注意,基于请求的超时意味着HTTP/2ping将无法保持有效连接。适用于HTTP1.1和HTTP2连接;
maxRetries:在给定时间内,集群中所有主机都可以执行的最大重试次数。默认为3。
熔断和限流是分布式系统的重要组成部分,优点是快速失败并迅速向下游反馈。 Istio是通过Envoy Proxy 来实现熔断和限流机制的,Envoy 强制在网络层面配置熔断和限流策略,这样就不必为每个应用程序单独配置或重新编程。Envoy支持各种类型的全分布式(不协调)限流。
IstioConnectionPool与 Envoy 的限流参数对照表:
Envoy paramether Envoy upon object Istio parameter Istio upon ojbect max_connections cluster.circuit_breakers maxConnections TCPSettings max_pending_requests cluster.circuit_breakers http1MaxPendingRequests HTTPSettings max_requests cluster.circuit_breakers http2MaxRequests HTTPSettings max_retries cluster.circuit_breakers maxRetries HTTPSettings connect_timeout_ms cluster connectTimeout TCPSettings max_requests_per_connection cluster maxRequestsPerConnection HTTPSettings
maxConnections: 表示在任何给定时间内,Envoy 与上游集群建立的最大连接数,限制对后端服务发起的 HTTP/1.1 连接数。该配置仅适用于 HTTP/1.1 协议,因为HTTP/2 协议可以在同一个 TCP 连接中发送多个请求,而 HTTP/1.1 协议在同一个连接中只能处理一个请求。如果超过了这个限制(即断路器溢出),集群的upstream_cx_overflow计数器就会增加。
maxPendingRequests: 表示待处理请求队列的长度,如果超过了这个限制,就会开启限流。因为HTTP/2 是通过单个连接并发处理多个请求的,因此该策略仅在创建初始 HTTP/2 连接时有用,之后的请求将会在同一个 TCP 连接上多路复用。对于HTTP/1.1 协议,只要没有足够的上游连接可用于立即分派请求,就会将请求添加到待处理请求队列中,因此该断路器将在该进程的生命周期内保持有效。如果该断路器溢出,集群的upstream_rq_pending_overflow计数器就会增加。
maxRequestsPerConnection: 表示在任何给定时间内,上游集群中主机可以处理的最大请求数,限制对后端服务发起的HTTP/2 请求数。实际上,这适用于仅 HTTP/2 集群,因为 HTTP/1.1 集群由最大连接数断路器控制。如果该断路器溢出,集群的upstream_rq_pending_overflow 计数器就会递增。
maxRetries:在任何给定时间内,集群中所有主机都可以执行的最大重试次数。一般情况下,建议对偶尔的故障积极地进行断路重试,因为总体重试容量不会爆炸并导致大规模级联故障。如果这个断路器溢出,则集群的upstream_rq_retry_overflow计数器将增加。
envoy新加参数(后期istio可能会增加)
maximumconcurrent connection pools:可以并发实例化的连接池的最大数量。一些特性,比如Original SrcListener Filter,可以创建无限数量的连接池。当集群耗尽其并发连接池时将会回收空闲连接。如果不能回收,断路器就会溢出。这与连接池中的集群最大连接不同,连接池中的连接通常不会超时。Connections自动清理;连接池不需要。注意,为了使连接池发挥作用,它至少需要一个上游连接,因此这个值应该小于集群最大连接。
在上游集群和优先级上针对不同的组件,都可以分别进行单独的配置参数进行请求限制。通过统计可以观察到这些断路器的状态,包括断路器打开前剩余数量的断路器。注意,在HTTP请求下将会重新设置路由过滤器的x-envoy-overloaded报头。
Istio的 熔断 可以在 流量策略 中配置。Istio的 自定义资源Destination Rule里,TrafficPolicy字段下有两个和熔断相关的配置:ConnectionPoolSettings 和 OutlierDetection。
ConnectionPoolSettings可以为服务配置连接的数量。OutlierDetection用来控制从负载均衡池中剔除不健康的实例。
例如,ConnectionPoolSettings控制请求的最大数量,挂起请求,重试或者超时;OutlierDetection 设置服务被从连接池剔除时发生错误的请求数,可以设置最小逐出时间和最大逐出百分比。有关完整的字段列表,请参考文档
启动 Httpbin样例程序。
如果您启用了 Sidecar 自动注入,通过以下命令部署 httpbin服务:
kubectl apply -f samples/httpbin/httpbin.yaml
创建一个 目标规则,在调用 httpbin服务时应用熔断设置:
kubectl apply -f - <<EOF
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
tcp:
maxConnections:1http:
http1MaxPendingRequests:1maxRequestsPerConnection:1outlierDetection:
consecutiveErrors:1interval: 1s
baseEjectionTime: 3m
maxEjectionPercent:100EOF验证目标规则是否已正确创建:
kubectl get destinationrule httpbin -o yaml
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: httpbin
...
spec:
host: httpbin
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests:1maxRequestsPerConnection:1tcp:
maxConnections:1outlierDetection:
baseEjectionTime:180.000s
consecutiveErrors:1interval:1.000s
maxEjectionPercent:100使用ConnectionPoolSettings字段中的这些设置,在给定的时间内只能和notifications 服务建立一个连接:每个连接最多只能有一个挂起的请求。如果达到阈值,熔断器将开始阻断请求。
OutlierDetection部分的设置用来检查每秒调用服务是否有错误发生。如果有,则将服务从负载均衡池中逐出至少三分钟(100%最大弹出百分比表示,如果需要,所有的服务实例都可以同时被逐出)。
在手动创建Destination Rule资源时有一件事需要特别注意,那就是是否为该服务启用了mTLS。如果是的话,还需要在Destination Rule中设置如下字段,否则当调用movies服务时,调用方可能会收到503错误:
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
还可以为特定namespace 或特定服务启用全局的mTLS。你应该了解这些设置以便确定是否把trafficPolicy.tls.mode设置为 ISTIO_MUTUAL。更重要的是,当你试图配置一个完全不同的功能(例如熔断)时,很容易忘记设置此字段。
提示:在创建Destination Rule前总是考虑mTLS!
为了触发熔断,让我们同时从两个连接来调用 notifications服务。maxConnections字段被设置为1。这时应该会看到503与200的响应同时到达。
当一个服务从客户端接收到的负载大于它所能处理的负载(如熔断器中配置的那样),它会在调用之前返回503错误。这是防止错误级联的一种方法。
创建客户端程序以发送流量到 httpbin服务。这是一个名为 Fortio的负载测试客户端,它可以控制连接数、并发数及发送 HTTP 请求的延迟。通过 Fortio 能够有效的触发前面 在 DestinationRule中设置的熔断策略。
向客户端注入 Istio Sidecar 代理,以便 Istio 对其网络交互进行管理:
kubectl apply -f samples/httpbin/sample-client/fortio-deploy.yaml
登入客户端 Pod 并使用 Fortio 工具调用 httpbin服务。 -curl参数表明发送一次调用:
$ export FORTIO_POD=$(kubectl get pods -l app=fortio -o 'jsonpath={.items[0].metadata.name}')
$ kubectl exec"$FORTIO_POD" -c fortio -- /usr/bin/fortio curl -quiet http://httpbin:8000/getHTTP/1.1 200OK
server: envoy
date: Tue,25 Feb 2020 20:25:52GMT
content-type: application/json
content-length: 586access-control-allow-origin: *access-control-allow-credentials:truex-envoy-upstream-service-time: 36{"args": {},"headers": {"Content-Length": "0","Host": "httpbin:8000","User-Agent": "fortio.org/fortio-1.3.1","X-B3-Parentspanid": "8fc453fb1dec2c22","X-B3-Sampled": "1","X-B3-Spanid": "071d7f06bc94943c","X-B3-Traceid": "86a929a0e76cda378fc453fb1dec2c22","X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/default/sa/httpbin;Hash=68bbaedefe01ef4cb99e17358ff63e92d04a4ce831a35ab9a31d3c8e06adb038;Subject=\"\";URI=spiffe://cluster.local/ns/default/sa/default"},"origin": "127.0.0.1","url": "http://httpbin:8000/get"}可以看到调用后端服务的请求已经成功!接下来,可以测试熔断。
在 DestinationRule配置中,您定义了 maxConnections: 1和 http1MaxPendingRequests: 1。 这些规则意味着,如果并发的连接和请求数超过一个,在 istio-proxy进行进一步的请求和连接时,后续请求或 连接将被阻止。
发送并发数为 2 的连接( -c 2),请求 20 次( -n 20):
kubectl exec -it $FORTIO_POD -c fortio -- /usr/bin/fortio load -c 2 -qps 0 -n 20 -loglevel Warning http://httpbin:8000/getFortio 0.6.2 running at 0 queries per second, 2->2 procs,for5s: http://httpbin:8000/getStarting at max qps with 2 thread(s) [gomax 2]forexactly 20 calls (10 per thread + 0)23:51:10 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503) Ended after106.474079ms : 20 calls. qps=187.84Aggregated Function Time : count20 avg 0.010215375 +/- 0.003604 min 0.005172024 max 0.019434859 sum 0.204307492# range, mid point, percentile, count>= 0.00517202 <= 0.006 , 0.00558601 , 5.00, 1 > 0.006 <= 0.007 , 0.0065 , 20.00, 3 > 0.007 <= 0.008 , 0.0075 , 30.00, 2 > 0.008 <= 0.009 , 0.0085 , 40.00, 2 > 0.009 <= 0.01 , 0.0095 , 60.00, 4 > 0.01 <= 0.011 , 0.0105 , 70.00, 2 > 0.011 <= 0.012 , 0.0115 , 75.00, 1 > 0.012 <= 0.014 , 0.013 , 90.00, 3 > 0.016 <= 0.018 , 0.017 , 95.00, 1 > 0.018 <= 0.0194349 , 0.0187174 , 100.00, 1# target50% 0.0095# target75% 0.012# target99% 0.0191479# target99.9% 0.0194062Code200 : 19 (95.0 %) Code503 : 1 (5.0 %) Response Header Sizes : count20 avg 218.85 +/- 50.21 min 0 max 231 sum 4377Response Body/Total Sizes : count 20 avg 652.45 +/- 99.9 min 217 max 676 sum 13049All done20 calls (plus 0 warmup) 10.215 ms avg, 187.8 qps
有趣的是,几乎所有的请求都完成了! istio-proxy确实允许存在一些误差。
Code 200 : 19 (95.0 %) Code503 : 1 (5.0 %)
将并发连接数提高到 3 个:
kubectl exec -it $FORTIO_POD -c fortio -- /usr/bin/fortio load -c 3 -qps 0 -n 30 -loglevel Warning http://httpbin:8000/getFortio 0.6.2 running at 0 queries per second, 2->2 procs,for5s: http://httpbin:8000/getStarting at max qps with 3 thread(s) [gomax 2]forexactly 30 calls (10 per thread + 0)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503)23:51:51 W http.go:617> Parsed non ok code 503 (HTTP/1.1 503) Ended after71.05365ms : 30 calls. qps=422.22Aggregated Function Time : count30 avg 0.0053360199 +/- 0.004219 min 0.000487853 max 0.018906468 sum 0.160080597# range, mid point, percentile, count>= 0.000487853 <= 0.001 , 0.000743926 , 10.00, 3 > 0.001 <= 0.002 , 0.0015 , 30.00, 6 > 0.002 <= 0.003 , 0.0025 , 33.33, 1 > 0.003 <= 0.004 , 0.0035 , 40.00, 2 > 0.004 <= 0.005 , 0.0045 , 46.67, 2 > 0.005 <= 0.006 , 0.0055 , 60.00, 4 > 0.006 <= 0.007 , 0.0065 , 73.33, 4 > 0.007 <= 0.008 , 0.0075 , 80.00, 2 > 0.008 <= 0.009 , 0.0085 , 86.67, 2 > 0.009 <= 0.01 , 0.0095 , 93.33, 2 > 0.014 <= 0.016 , 0.015 , 96.67, 1 > 0.018 <= 0.0189065 , 0.0184532 , 100.00, 1# target50% 0.00525# target75% 0.00725# target99% 0.0186345# target99.9% 0.0188793Code200 : 19 (63.3 %) Code503 : 11 (36.7 %) Response Header Sizes : count30 avg 145.73333 +/- 110.9 min 0 max 231 sum 4372Response Body/Total Sizes : count 30 avg 507.13333 +/- 220.8 min 217 max 676 sum 15214All done30 calls (plus 0 warmup) 5.336 ms avg, 422.2 qps
现在,您将开始看到预期的熔断行为,只有 63.3% 的请求成功,其余的均被熔断器拦截:
Code 200 : 19 (63.3 %) Code503 : 11 (36.7 %)
查询 istio-proxy状态以了解更多熔断详情:
kubectl exec $FORTIO_POD -c istio-proxy -- pilot-agent request GET stats | grep httpbin |grep pending cluster.outbound|80||httpbin.springistio.svc.cluster.local.upstream_rq_pending_active: 0cluster.outbound|80||httpbin.springistio.svc.cluster.local.upstream_rq_pending_failure_eject: 0cluster.outbound|80||httpbin.springistio.svc.cluster.local.upstream_rq_pending_overflow: 12cluster.outbound|80||httpbin.springistio.svc.cluster.local.upstream_rq_pending_total: 39
可以看到 upstream_rq_pending_overflow值 12,这意味着,目前为止已有 12 个调用被标记为熔断
参考:
https://blog.csdn.net/weixin_38754564/article/details/102386272
https://preliminary.istio.io/latest/zh/docs/tasks/traffic-management/circuit-breaking/
https://www.kubernetes.org.cn/5556.html