DevOps 实战
- -DevOps 的 3 个支柱. 第 1 步:寻找合适的试点项目. 第 3 步:快速建立初期成功. 第 4 步:快速展示和持续改进. 第一阶段:每次提交触发完整的流水线. 第二阶段:每次流水线触发自动化测试. 第三阶段:出了问题可以在第一时间修复. 第二步:定义指标并达成一致. 第三步:建立自动化执行和检查能力.
维基百科的定义
DevOps(开发 Development 与运维 Operations 的组合词)是一种文化、一场运动或实践,强调在自动化软件交付流程及基础设施变更过程中,软件开发人员与其他信息技术(IT)专业人员彼此之间的协作与沟通。它旨在建立一种文化与环境,使构建、测试、软件发布得以快速、频繁以及更加稳定地进行。
DevOps 是通过平台(Platform)、流程(Process)和人(People)的有机整合,以C(协作)A(自动化)L(精益)M(度量)S(共享)文化为指引,旨在建立一种可以快速交付价值并且具有持续改进能力的现代化 IT 组织。
高效的软件交付方式
根据DevOps现状报告,可以得出 DevOps 的 4 个结果指标。
每年,这个报告都会基于这 4 个核心指标统计行业内高效能团队和低效能团队之间的差距。从去年的数据来看,与低效能团队相比,高效能团队的部署频率高了 46 倍,变更前置时间快了 2500 多倍,服务恢复时间也快了 2600 多倍,失败率低了 7 倍。
DevOps 状态报告中提到的四项结果指标,分别代表了软件交付的两个最重要的方面,也就是交付效率和交付质量。而且,从数据结果中,我们还能得到一个惊人的发现,那就是高效能的组织不仅做到了高效率,还实现了高质量,由此可见,鱼与熊掌可以兼得。
DevOps 状态报告合集 https://pan.baidu.com/s/1W7-_et-wulD7AueBU2KTow 提取码:mgl1
激发团队的创造力
实施 DevOps,一方面可以通过种种流程优化和自动化能力,改善软件开发团队的工作节奏,另一方面,也可以让大家关注同一个目标,彼此信任,高效协作,调动员工的积极性和创新能力,从而让整个团队进入一种积极创造价值的状态,而这所带来的影响远非建设一两个工具平台可比拟的。
一切软件交付过程中的手动环节,都是未来可以尝试进行优化的方向。即便在运维圈里面, ITIL(IT 基础架构库)一直是运维赖以生存的基石,也并不妨碍自动化的理念逐步深入到ITIL 流程之中,从而在受控的基础上不断优化流程流转效率。
工具平台的引入和建设就成为了 DevOps 打动人的关键因素之一。但是大量的引入这类工具,会造成企业内部的工具平台泛滥,很多同质化的工具在完成从0 到 1 的过程后就停滞不前,陷入重复的怪圈,显然也是一种资源浪费。也有很多公司引入了完整的敏捷项目管理工具,但是却以传统项目管理的方式来使用这套工具,效率跟以前相比并没有明显的提升。对于自研平台来说,也是同样的道理。如果仅仅是把线下的审批流程搬到线上执行,固然能提升一部分执行效率,但是对于企业期望的质变来说,却是相距甚远。
说到底,工具没法解决人的问题,这样一条看似取巧的路径,却没法解决企业的根本问题。这时候,就需要文化闪亮登场了。
首先要建立一套DevOps的机制,包括 OKR 指标的设定、关键指标达成后的激励、成立专项的工作小组、引入外部的咨询顾问,以及一套客观的评判标准,这一切都保证了团队走在正确的道路上。而承载这套客观标准的就是一套通用的度量平台,说到底,还是需要将 规则内建于工具之中,并通过工具来指导实践。
这样一来,当团队通过 DevOps 获得了实实在在的改变,那么 DevOps 所倡导的职责共担、持续改进的文化自然也会生根发芽。
所以你看,DevOps 中的文化和工具,本身就是一体两面,我们既不能盲目地奉行工具决定论,上来就大干快干地采购和建设工具,也不能盲目地空谈文化,在内部形成一种脱离实际的风气。
对工具和文化的体系化认知,可以归纳到 DevOps 的 3 个支柱之中,即 人(People)、流程(Process)和平台(Platform)。3 个支柱之间两两组合,构成了我们实施 DevOps的”正确姿势”,只强调其中一个维度的重要性,明显是很片面的。
人 + 流程 = 文化
在具体的流程之下,人会形成一套行为准则,而这套行为准则会潜移默化地影响软件交付效率和质量的方方面面。这些行为准则组合到一起,就构成了企业内部的文化。
指导 DevOps 落地发展的思想,就是 DevOps 的文化。
流程 + 平台 = 工具
平台的最大意义,就是承载企业内部的标准化流程。当这些标准化流程被固化在平台之中时,所有人都能够按照一套规则沟通,沟通效率显然会大幅提升。
平台上固化的每一种流程,其实都是可以用来解决实际问题的工具。很多人分不清工具和平台的关系,好像只要引入或者开发了一个工具,都可以称之为平台,也正因为这样,企业内部的平台比比皆是。
实际上,平台除了有 用户量、认可度、老板加持等因素之外,还会有 3 个显著特征。
平台 + 人 = 培训赋能
平台是标准化流程的载体,一方面可以规范和约束员工的行为,另一方面,通过平台赋能,所有人都能以相同的操作,获得相同的结果。这样一来,跨领域之间的交接和专家就被平台所取代,当一件事情不再依赖于个人的时候,等待的浪费就会大大降低,平台就成了组织内部的能力集合体。
但与此同时,当我们定义了期望达到的目标,并提供了平台工具,那么对人的培训就变得至关重要,因为只有这样,才能让工具平台发挥最大的效用。更加重要的是,通过最终的用户使用验证,可以发现大量的可改进空间,进一步推动平台能力的提升,从而带动组织整体的飞轮效应,加速组织的进化。
所以你看, 文化、工具和培训作为 DevOps 建设的 3 个重心,折射出来的是对 组织流程、平台和人的关注, 三位一体,缺一不可。
通过模型和框架,来帮助企业识别当前的 DevOps 能力水平并加以改进。
下列是DevOps的熟练度模型:
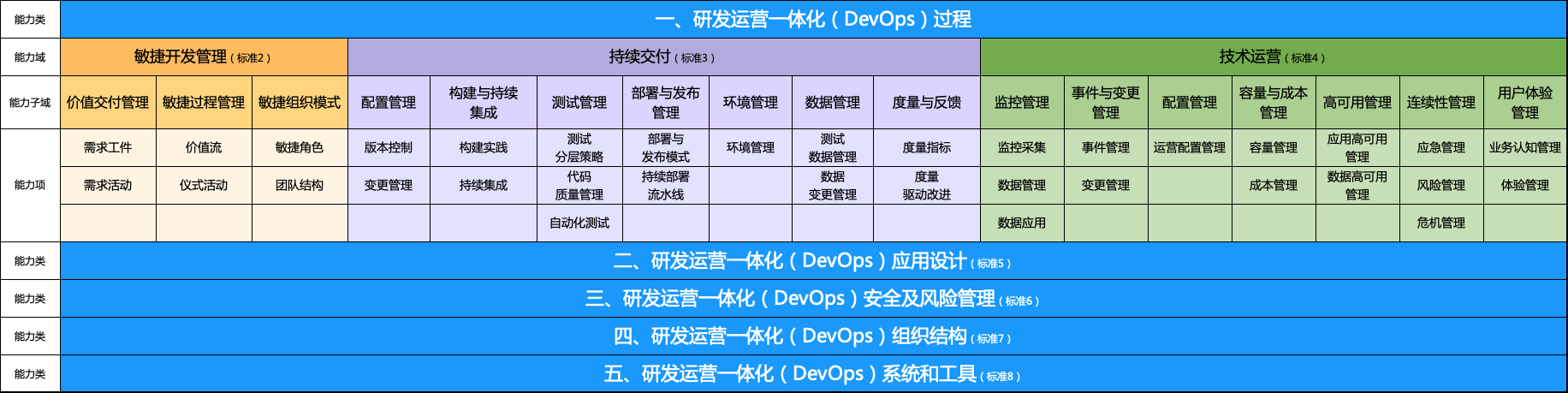
研发运营一体化(DevOps)能力成熟度模型
在实际参考模型和框架的时候,我认为应该尽量遵循以下步骤和原则:
下面是以模型为指导,对示例企业进行了全面梳理,汇总了一张大盘图
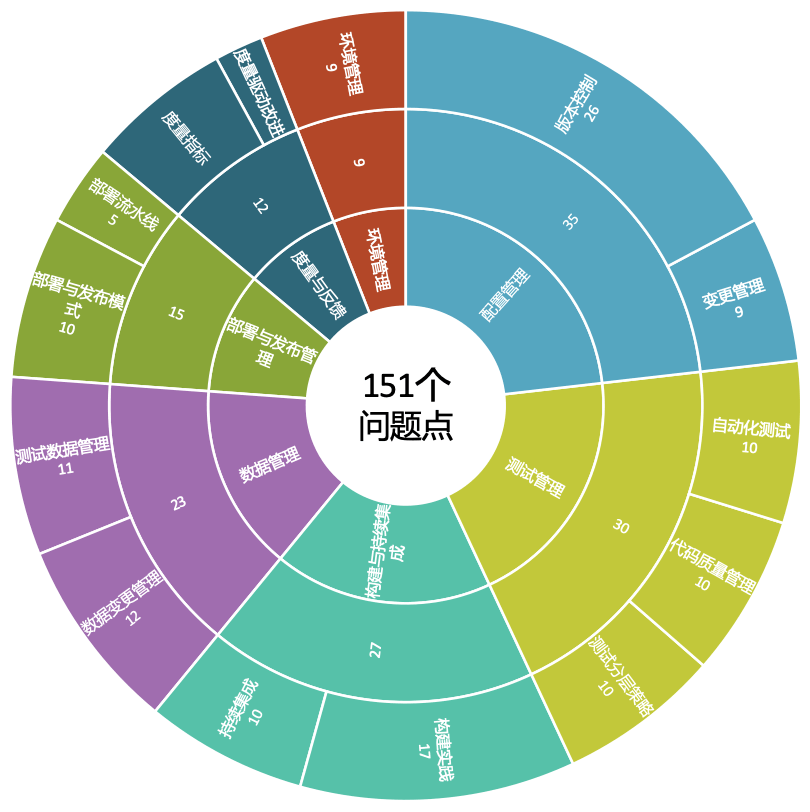
接下来,针对识别出来的这些差距点,找到需要改进的目标和预期效果,并分析哪些关键能力制约了交付效率的提升,对问题进行逐个优化。
由此可以看出, DevOps 的能力实践和能力框架模型相辅相成:能力实践定义了企业落地DevOps 的路线图和主要建设顺序,能力模型可以指导支撑方法的各类实践的落地建设;能力实践时刻跟随企业价值交付的导向,而能力模型的积累和沉淀,能够让企业游刃有余地面对未来的各种挑战。
至于 ITIL 和 CMMI,这些过往的框架体系自身也在跟随 DevOps 的大潮在持续演进,比如以流程合规为代表的 ITIL 最近推出了第 4 个版本。我们引用一下 ITIL V4 的指导原则,包括:关注价值、关注现状、交互式流程和反馈、协作和可视化、自动化和持续优化、极简原则和关注实践。
什么是价值?简单来说,价值就是 那些带给企业生存发展的核心资源,比如生产力、盈利能力、市场份额、用户满意度等。
VSM是 Value Stream Mapping 的缩写,也就是我们常说的 价值流图。它起源于传统制造业的精益思想,用于分析和管理一个产品交付给用户所经历的业务流、信息流,以及各个阶段的移交过程。
说白了,VSM 就是要说清楚在需求提出后,怎么一步步地加工原材料,进行层层的质量检查,最终将产品交付给用户的过程。通过观察完整流程中各个环节的流动效率和交付质量,识别不合理的、低效率的环节,进行优化,从而实现整体效率的提升。
通过使用价值流图对软件交付过程进行建模,使整个过程可视化,从而识别出交付的瓶颈和各个环节之间的依赖关系,这恰恰是“DevOps 三步工作法”的第一步“流动”所要解决的问题。
DevOps 三步工作法:
第一步:流动。通过工作可视化,限制在制品数量,并注入一系列的工程实践,从而加速从开发到运营的流动过程,实现低风险的发布。 第二步:反馈。通过注入流动各个过程的反馈能力,使缺陷在第一时间被发现,用户和运营数据第一时间展示,从而提升组织的响应能力。 第三步:持续学习和试验。没有任何文化和流程是天生完美的,通过团队激励学习分享,将持续改进注入日常工作,使组织不断进步。
关于前置时间,有很多种解释,一般建议采用需求前置时间和开发前置时间两个指标进行衡量
需求前置时间:从需求提出(创建任务),到完成开发、测试、上线,最终验收通过的时间周期,考查的是团队整体的交付能力,也是用户核心感知的周期。
开发前置时间:从需求开始开发(进入开发中状态),到完成开发、测试、上线,最终验收通过的时间周期,考查的是团队的开发能力和工程能力。
如何开展一次成功的 VSM 活动呢?一般来说,有 2 种方式。
选取改进项目对象中某个核心的业务模块,参加会议的人员需要覆盖软件交付的所有环节,包括工具平台提供方。而且,参会人员要尽量是相对资深的,因为他们对自身所负责的业务和上下游都有比较深刻的理解,比较容易识别出问题背后的根本原因。
通常来说,企业内部的DevOps 转型工作都会有牵头人,甚至会成立转型小组,那么可以由这个小组中的成员对 软件交付的各个环节的团队进行走访。这种方式在时间上是比较灵活的,但对走访人的要求比较高,最好是 DevOps 领域的专家,同时是企业内部的老员工,这样可以跟受访人有比较深入坦诚的交流。
沟通时,要建立一个问题列表,避免东拉西扯。
为了方便你更好地理解这些问题,我给你提供一份测试团队的访谈示例。
| 关键问题 | 参考答案 |
|---|---|
| 在价值交付的过程中,你所在团队的主要职责是什么? | 我们是软件质量的把关人,负责交付软件的功能质量验收工作,避免缺陷流入线上环节。 |
| 你所在团队的上下游团队有哪些? | 我们的上游是开发团队,下游是运维团队,另外还跟项目管理团队和安全团队有关系。 |
| 价值在当前环节的处理方式,时长是怎样的? | 从迭代需求开始,我们就会参与需求评审,并进行测试设计。研发提测后,我们就会按照测试计划和案例对功能进行验收,如果验收通过,就给出测试报告并流转下游,如果存在问题,就提出缺陷。—般来说,平均测试流转周期为2.5天。 |
| 有哪些关键系统支持了价值交付工作? | 包括研发提测系统,测试管理平台,缺陷系统。 |
| 是否存在等待和其他类型的浪费? | 开发提测后一般都需要开发人员在测试环境部署,有时候开发人员不在就要等待,另外每次申请测试环境也需要向环境部门申请,往往几天才能下来。 |
| 工作向下游流转后被打回的比例有多少? | 这个要看缺陷漏测率和线上缺陷逃逸率指标,我们有相关的数据,人概漏测率0.15%。 |
通过访谈交流,我们就可以对整个软件交付过程有一个全面的认识,并根据交付中的环节、上下游关系、处理时长、识别出来的等待浪费时长等,按照 VSM 模型图画出当前部门的价值流交付图,以及各个阶段的典型工具,如下图所示:
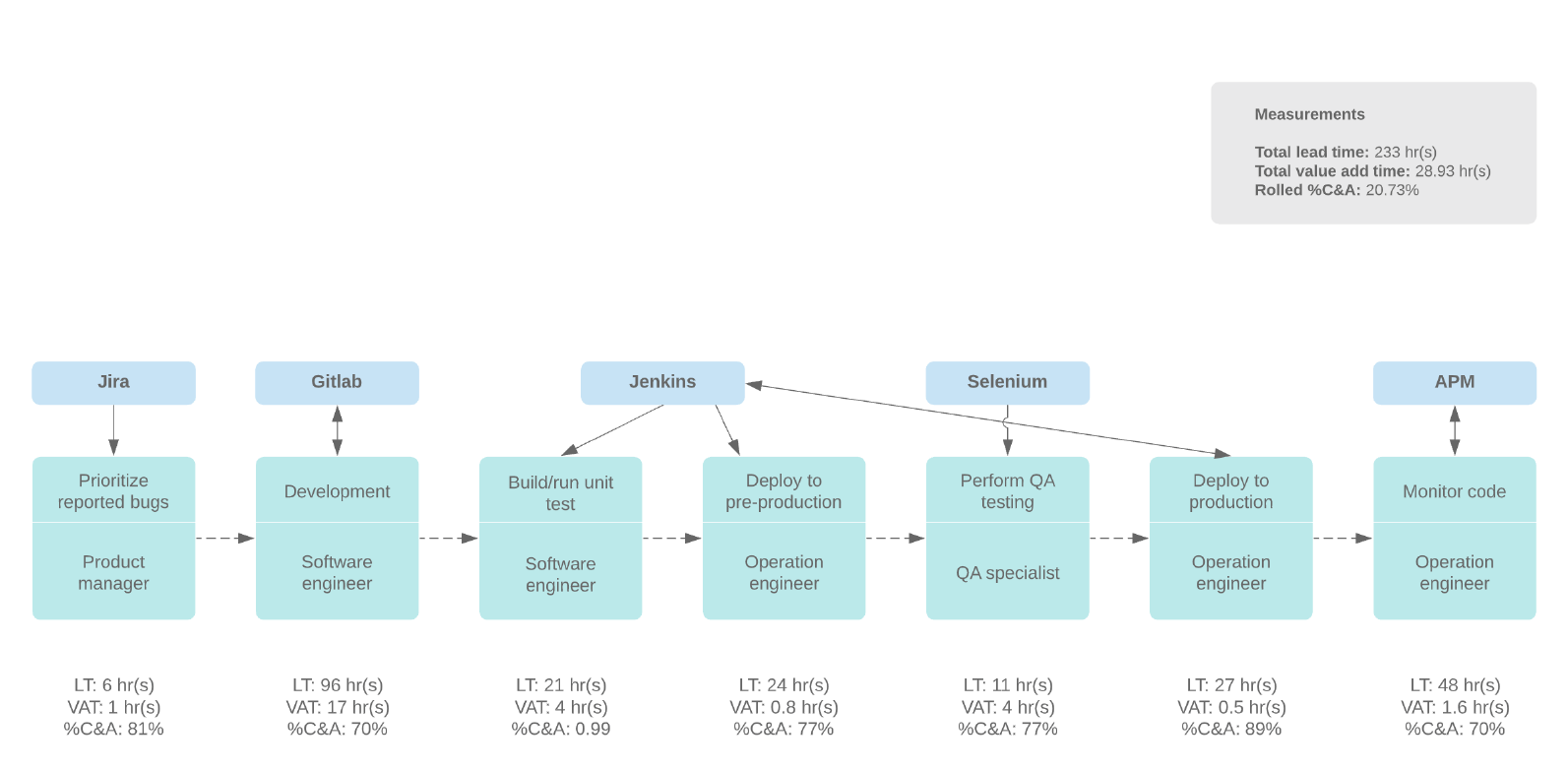
实际上,它的价值绝不仅限于输出了一幅价值流交付图而已。VSM 具有非常丰富的价值,包括以下几个方面:
看见全貌。
如果只关注单点问题,我们会很容易陷入局部优化的怪圈。DevOps 追求的是价值流动效率最大化,也就是说,就算单点能力再强,单点之间的割裂和浪费对于价值交付效率的影响也是超乎想象的。所以,对于流程改进来说,第一步,也是最重要的一步,就是能够看见全貌,这样才能从全局视角找到可优化的瓶颈点,从而提升整体的交付效率。
另外, 对于全局交付的建模,最终也会体现到软件持续交付流水线的建设上,因为流水线反映的就是企业客观的交付流程。
识别问题。
VSM 中的几个关键指标,也就是前置时长、增值和不增值时长,以及完成度和准确度,都是可以客观量化改进的指标。当面对这样一幅价值流图的时候,我们很容易就能识别出当前最重要的问题和改进事项。
促进沟通。
在我们开展 VSM 梳理的时候,团队才第一次真正了解上下游团队的职责、工作方式,以及让他们痛苦低效的事情。这时,我们通常会设身处地地想:“只要我们多做一点点,就能大大改善兄弟团队的生存状况了。”实际上,这种 同理心对打破协作的壁垒很有帮助,可以为改善团队内部文化带来非常正面的影响。实际上,这也是我推荐你用会议或者工作坊的方式推进 VSM 的根本原因。
驱动度量。
在 VSM 访谈的时候,我们要问一个团队的交付周期、准确率等指标问题,如果你发现这个团队支支吾吾,只能给出模糊的回答,这时你就要注意啦,这里本身就大有问题。因为这就表示当前环节的度量指标不够清晰,或者指标过于复杂,团队不清楚关键的结果指标。 另外,如果数据的提取需要大量时间,比如需要采用人为统计算数的方式,那么这就体现了这个环节的平台建设能力不足,无法自动化地收集和统计数据,甚至有些关键数据还没有沉淀到数据系统中,只能通过人工本地化的方式进行管理。 这些都是 DevOps 转型的过程中需要解决的问题,可以优先处理。可以说, VSM 是一场团队协作的试炼。收集 VSM 数据的过程本身,就需要平台间的打通和数据共享,以及自动化的推进,这有助于度量活动的开展。
价值展现。
如何让高层领导明白企业交付效率改善所带来的价值呢?价值流梳理就是一种很好的方式。因为 VSM 从价值分析而来,到价值优化而去,本身就是在回答 DevOps 对于企业的价值问题。
如果想在企业内部推行一种新的模式,无外乎有两种可行的轨迹:一种是 自底向上,一种是 自顶向下。
在这种模式下,企业内部的 DevOps 引入和实践源自于一个小部门或者小团队,他们可能是 DevOps 的早期倡导者和实践者,为了解决自身团队内部,以及上下游团队交互过程中的问题,开始尝试使用 DevOps 模式。由于团队比较小,而且内部的相关资源调动起来相对简单,所以这种模式比较容易在局部获得效果。
采用“ 羽化原则”,也就是首先在自己团队内部,以及和自己团队所负责的业务范围有强依赖关系的上下游团队之间建立联系, 一方面不断扩展自己团队的能力范围,另一方面,逐步模糊上下游团队的边界,由点及面地打造 DevOps 共同体。
当然,如果想让 DevOps 转型的效果最大化,你一定要想方设法地让 高层知晓局部改进的效果,让他们认可这样的尝试,最终实现横向扩展,在企业内部逐步铺开。
企业高层基于自己对于行业趋势发展的把握和团队现状的了解,以行政命令的方式下达任务目标。在这种模式下,公司领导有足够的意愿来推动 DevOps 转型并投入资源,各个团队也有足够清晰的目标。
那么,这样是不是就万事大吉了呢?其实不然。在企业内部有这样一种说法:只要有目标,就一定能达成。因为公司领导对于细节的把握很难做到面面俱到,团队为了达成上层目标,总是能想到一些视角或数据来证明目标已经达成,这样的 DevOps 转型说不定对公司业务和团队而言反而是一种伤害。
无论企业的 DevOps 转型采用哪条轨迹, 寻求管理层的认可和支持都是一个必选项。如果没有管理层的支持,DevOps 转型之路将困难重重。因为无论在什么时代,变革一直都是一场勇敢者的游戏。对于一家成熟的企业而言,无论是组织架构、团队文化,还是工程能力、协作精神,都是长期沉淀的结果,而不是在一朝一夕间建立的。
除此之外,转型工作还需要持续的资源投入,这些必须借助企业内部相对比较 high level 的管理层的推动,才能最终达成共识并快速落地。如果你所在的公司恰好有这样一位具备前瞻性视角的高层领导,那么恭喜你,你已经获得了 DevOps 转型道路上至关重要的资源。
一个合适的项目应该具备以下几个特征:
所谓痛点,就是当前最影响团队效率的事情,同时也是改进之后可以产生最大效益的事情。
可以通过 价值流分析活动来寻找团队痛点。
在进行的转型初期,切记不要把面铺得太广,把战线拉得太长。 首先识别一个改进点,定义一个目标。比如,环境申请和准备时间过程,那么就可以定义这样一个指标:优化 50% 的环境准备时长。这样一来,团队的目标会更加明确,方便任务的拆解和细化,可以在几周内见到明显的成果。
取得阶段性的成果之后,要及时向管理层汇报,并且在团队内部进行总结。这样,一方面可以增强管理层和团队的信心,逐步加大资源投入;另一方面,也能够及时发现改进过程中的问题,在团队内部形成持续学习的氛围,激发团队成员的积极性,可以从侧面改善团队的文化。
在这条路径之下,也隐藏着一些可以预见的问题,最典型的就是DevOps 转型的 J 型曲线,这也是在 2018 年 DevOps 状态报告中的一个重点发现。
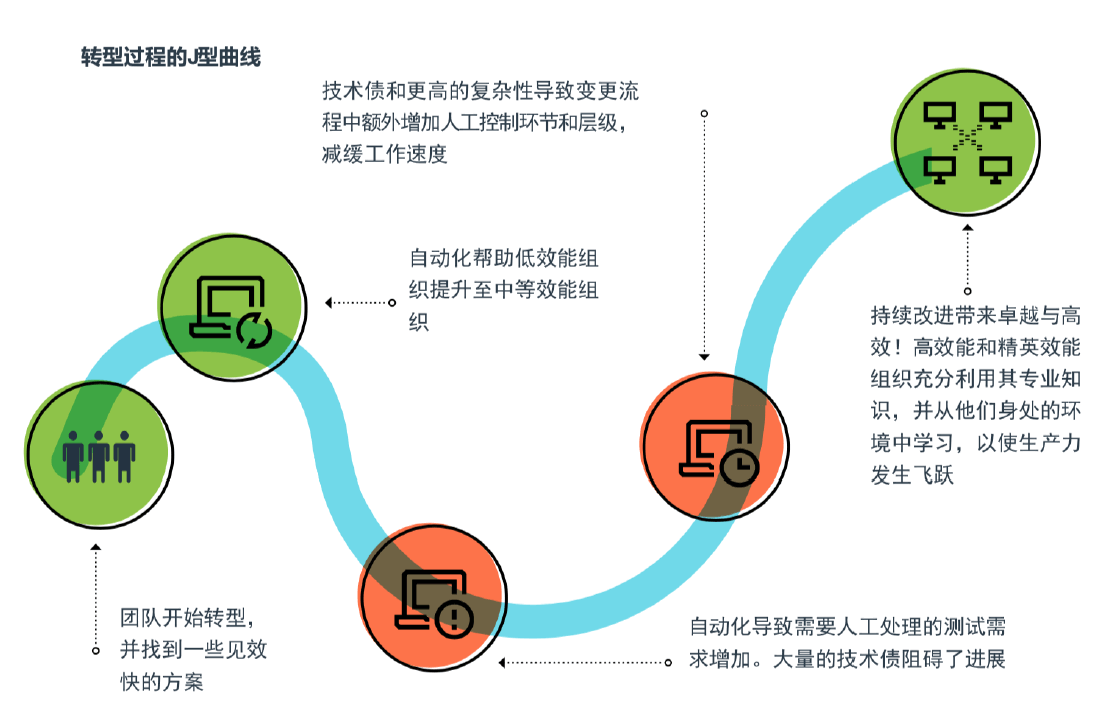
在转型之初,团队需要快速识别出主要问题,并给出解决方案。在这个阶段,整个团队的效能水平比较低,可以通过一些实践引入和工具的落地,快速提升自动化的能力和水平,从而帮助团队获得初期的成功。
但是,随着交付能力的提升,质量能力和技术债务的问题开始显现。比如,由于大量的手工回归测试,团队难以压缩测试周期,从而导致交付周期陷入瓶颈;项目架构的问题带来的技术债务导致集成问题增多,耦合性太强导致改动牵一发而动全身……
这个时候,团队开始面临选择:是继续推进呢?还是停滞不前呢?继续推进意味着团队需要分出额外的精力来加强自动化核心能力的预研和建设,比如优化构建时长、提升自动化测试覆盖率等,这些都需要长期的投入,甚至有可能会导致一段时间内团队交付能力的下降。
与此同时,与组织的固有流程和边界问题相关的人为因素,也会制约企业效率的进一步提升。如何让团队能够有信心减少评审和审批流程,同样依赖于质量保障体系的建设。如果团队迫于业务压力,暂缓 DevOps 改进工作,那就意味着 DevOps 难以真正落地发挥价值,很多 DevOps 项目就是这样“死”掉的。
在转型初期,建立一个 专职的转型工作小组还是很有必要的。这个团队主要由 DevOps 转型关联团队的主要负责人、DevOps 专家和外部咨询顾问等牵头组成,一般是各自领域的专家或者资深成员,相当于 DevOps 实施的“大脑”,主要负责制定 DevOps 转型项目计划、改进目标识别、技术方案设计和流程改造等。
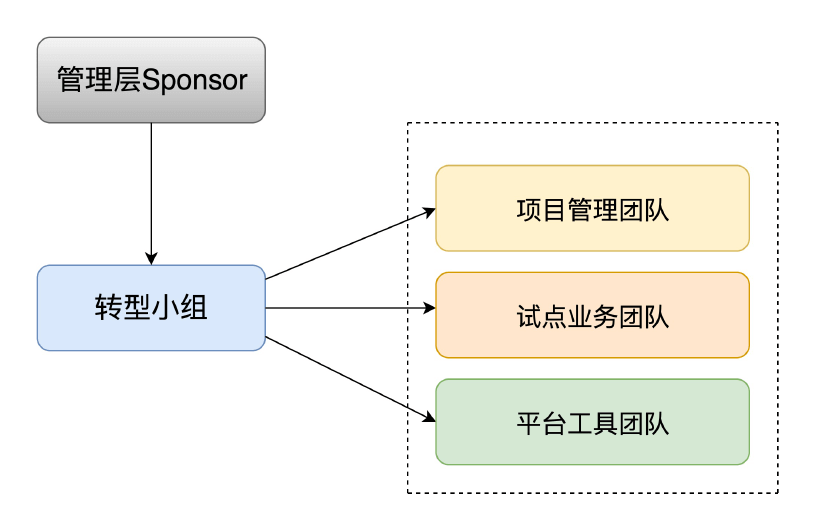
转型小组的团队组成示意图
在现在这个多变的时代,没人能够准确地预测需求的价值。所以,交付能力的提升,可以帮助业务以最小的成本进行试错,将新功能快速交付给用户。同时,用户和市场的情况又能够快速地反馈给业务方,从而帮助业务校准方向。而业务的敏捷能力高低,恰恰体现在对功能的设计和需求的把握上,如果不能灵活地调整需求,专注于最有价值的事情,同样会拖累交付能力,导致整体效率的下降。
也就是说,在这样一种快速迭代交付的模式下,业务敏捷和交付能力二者缺一不可。
所以开发更少的功能,聚焦用户价值,持续快速验证,就成了产品需求管理的核心思想。
在把握需求质量的前提下,如何尽可能地减小需求交付批次,采用最小的实现方案,保证高优先级的需求可以快速交付,从而提升上线实验和反馈的频率,就成了最关键的问题。
关于需求分析,比较常见的方法就是 影响地图。
影响地图是通过简单的“Why-Who-How-What”分析方法,实现业务目标和产品功能之间的映射关系。
如果你是第一次接触影响地图,可能会听起来有点晕。没关系,我给你举个例子,来帮你理解这套分析方法。
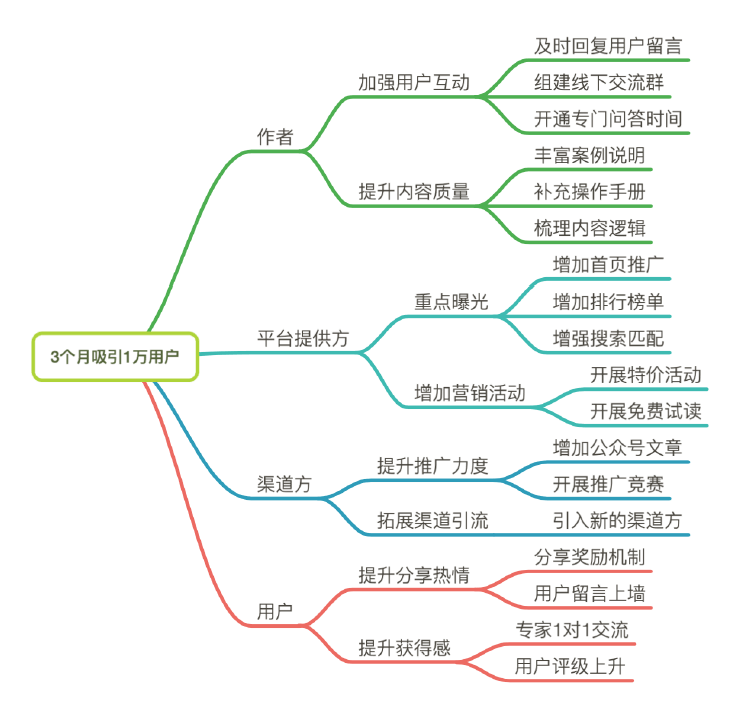
比如,一个专栏希望可以在上线 3 个月内吸引 1 万名用户,那么,这个 Why,也就是最核心的业务目标。为了达成这个目标,需要影响的角色包含哪些呢?其实就包含了作者、平台提供方、渠道方和最终用户。需要对他们施加哪些影响呢?对作者来说,需要快速地回答用户的问题,提升内容的质量;对平台来说,需要对专栏进行重点曝光,增加营销活动;对渠道方来说,需要提高推广力度和渠道引流;对于用户来说,增加分享有礼、免费试读和个人积分等活动。
那么基于以上这些影响方式,转化为最终的实际需求,就形成了一张完整的影响地图,如下图所示:
需求这么多,优先级要怎么安排呢?别急,现在我就给你介绍一下 “ 卡诺模型“。
卡诺模型(Kano Model),是日本大师授野纪昭博士提出的一套需求分析方法,它对理解用户需求,对其进行分类和排序方面有着很深刻的洞察。
卡诺模型将产品需求划分为五种类型:
必备型:这些是产品必须要有的功能,如果没有的话,会带来非常大的影响。不过有这些功能的话,也没人会夸你做得有多好,比如安全机制和风控机制等。
对于五类需求来说,核心要做到 3 点:
而 用户故事则是以用户的价值为核心,圈定一种角色,表明通过什么样的活动,最终达到什么样的价值。团队在讨论需求的时候,采用一种讲故事的形式,代入到设定的用户场景之中,跟随用户的操作路径,从而达成用户的目标,解决用户的实际问题。这样做的好处在于,经过团队的共同讨论和沟通,产品、研发和测试对需求目标可以达成共识,尤其是对想要带给用户的价值达成共识。
在这个过程中,团队不断探索更好的实现方案和实现路径,并补充关联的用户故事,从而形成完整的待办事项。更重要的是,团队成员逐渐培养了用户和产品思维,不再拘泥于技术实现本身,增强了彼此之间的信任,积极性方面也会有所改善,从而提升整个团队的敏捷性。用户故事的粒度同样需要进行拆分,拆分的原则是针对一类用户角色,交付一个完整的用户价值,也就是说用户故事不能再继续拆分的粒度。当然,在实际工作中,拆分的粒度还是以迭代周期为参考,在一个迭代周期内交付完成即可,一般建议是 3~5 天。检验用户故事拆分粒度是否合适,可以遵循 INVEST 原则。
Negotiable(可协商的):用户故事不应该是滴水不漏、行政命令式的,而是要抛出一个场景描述,并在需求沟通阶段不断细化完成。
需求的价值难以预测,但是需求的价值却可以定义。
需求价值的定义,可以理解为需求价值的度量,分为客观指标和主观 2 个方面。
但是无论是客观指标,还是主观指标,每一个需求在提出的时候,可以在这些指标中选择需求上线后的预期,并定义相关的指标。一方面加强价值导向,让产品交付更有价值的需求,另外一方面,也强调数据导向,尽量客观地展现实际结果。
从技术层面来说,一个业务需求的背后,一般都会关联一个埋点需求。所谓埋点分析,是网站分析的一种常用的数据采集方法。设计良好的埋点功能,不仅能帮助采集用户操作行为,还能识别完整的上下文操作路径,甚至进行用户画像的聚类和分析,帮助识别不同类型用户的行为习惯。从用户层面来说,众测机制和用户反馈渠道是比较常见的两种方式,核心就是既要听用户怎么说,也要看用户怎么做。
最后,引入业务的 DevOps,就成了 BizDevOps。 BizDevOps 的核心理念:
如果没有在制品限制的拉动系统,只能说是一个可视化系统,而不是看板系统,这一点非常重要。
加快价值流动是精益看板的核心。在软件开发中,这个价值可能是一个新功能,也可能是缺陷修复,体验优化。根据利特尔法则,我们知道:平均吞吐率 = 在制品数量 / 平均前置时间。其中,在制品数量就是当前团队并行处理的工作事项的数量。
在 制品数量会影响前置时间,并行的任务数量越多,前置时间就会越长,也就是交付周期变长,这显然不是理想的状态。
不仅如此,前置时间还会影响交付质量,前置时间增长,则质量下降。
精益看板的实践方法分为了五个步骤。
在最开始,我们只需要忠实客观地把这个现有流程呈现出来就可以了,而无需对现有流程进行优化和调整。也正因为如此,看板方法的引入初期给组织带来的冲击相对较小,不会因为剧烈变革引起组织的强烈不适甚至是反弹。所以,看板方法是一种相对温和的渐进式改进方法。
看板的主要构成元素可以简单概括成“ 一列一行”。
一列是指看板的竖向队列,是按照价值流转的各个主要阶段进行划分的,比如常见的需求、开发、测试、发布等。
竖向队列划分的标准主要有两点:
除此之外,看板的设计需要定义明确的起点和终点。对于精益看板来说,覆盖端到端的完整价值交付环节是比较理想的状态。
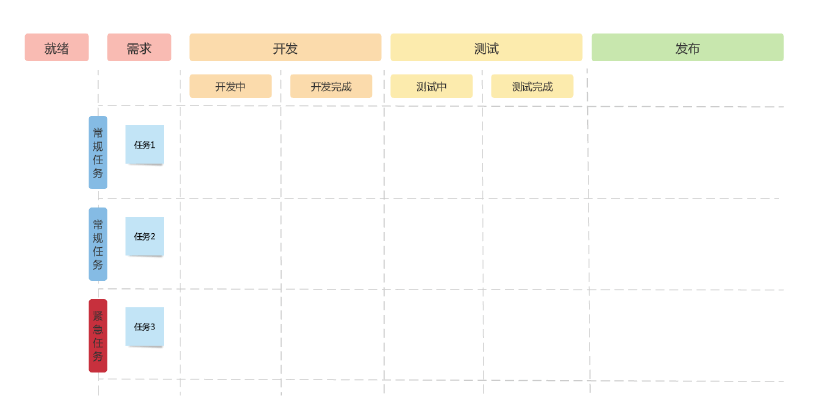
一行是指看板横向的泳道。泳道用于 需求与需求之间划清界限,尤其在使用物理看板的时候,经常会因为便利贴贴的位置随意等原因导致混乱,而定义泳道就可以很好地解决这个问题。
沟通的成本甚至要大于工作的成本。而规则可以大大地降低团队成员之间的沟通成本,统一团队的沟通语言,形成团队成员之间的默契。看板的规则包含两个方面,一个是可视化规则,另一个是显式化规则,我分别来介绍一下。
可视化规则。
看板中的主要构成元素是“一列一行”。实际上,看板中卡片的设计也有讲究,主要有 3 点。
显式化规则。
看板除了要让人看得懂,还要让人会操作,这一点非常重要。
应用看板方法只能暴露团队的现有问题,而不能解决团队的现有问题。
看板方法的好处在于,通过降低在制品数量,可以将这些潜在的问题逐步暴露出来。
限制在制品数量有两个关键节点:一个是需求流入节点,一个是需求交付节点。
需求流入节点
根据需求的优先级限制并行任务数量。
需求交付节点
关键在于加速需求的流出。
需要配套的管理流程,来保障看板机制的顺畅运转。在看板方法中,常见的有三种会议,分别是每日站会、队列填充会议和发布规划会议。
每日站会。
与 Scrum 方法的“夺命三连问”(昨天做了什么?今天计划做什么?有什么困难或者阻塞?)不同,看板方法更加关注两点: 待交付的任务。看板追求价值的快速流动,所以,对于在交付环节阻塞的任务,你要重点关注是什么原因导致的。 紧急、缺陷、阻塞和长期没有更新的任务。这些任务在规则中也有相应的定义,如果出现了这些问题,团队需要最高优先级进行处理。这里有一个小技巧,就是当卡片放置在看板之中时,每停留一天,卡片的负责人就会手动增加一个小圆点标记,通过这个标记的数量,就可以看出哪些任务已经停留了太长时间。而对于使用电子看板的团队来说,这就更加简单了。比如,Jira 本身就支持停留时长的显示。当然,你也可以自建过滤器,按照停留时长排序,重点关注 Top 问题的情况。
每日站会要尽量 保持高效,对于一些存在争议的问题,或者是技术细节的讨论,可以放在会后单独进行
队列填充会议。
队列填充会议的目标有两点: 一个是对任务的优先级进行排序, 一个是展示需求开发的状态。一般情况下,队列填充会议需要业务方、技术方和产品项目负责人参与进来,对需求的优先级达成一致,并填充到看板的就绪状态中。
发布规划会议。
发布规划会议以最终交付为目标。一般情况下,项目的交付节奏会影响队列填充的节奏,二者最好保持同步。另外,随着部署和发布的分离,研发团队越来越趋近于持续开发持续部署,而发布由业务方统一规划把控,发布规划会议有助于研发团队和业务方的信息同步,从而实现按节奏部署和按需发布的理想状态。
实际上,无论是 DevOps 还是精益看板,任何一套方法框架的终点都是持续改进。因为,作为一种新的研发思想和研发方法,只有结合业务实际,并根据自身的情况持续优化规则、节奏、工具和流程,才能更好地为业务服务。
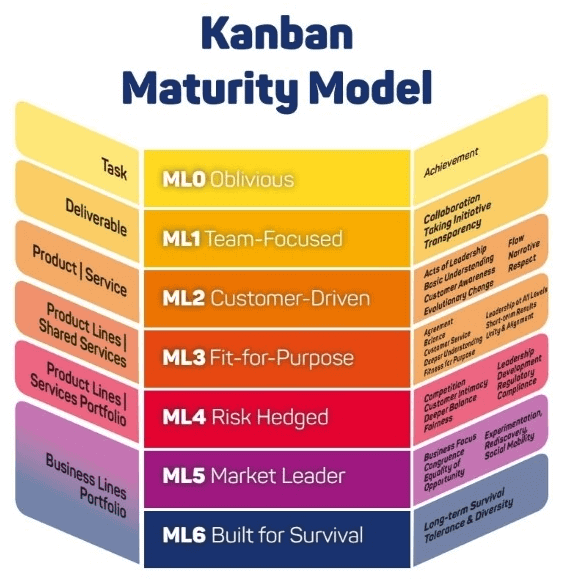
看板方法的实践是一个循序渐进的过程。为此看板创始人 David J Anderson 总结了看板方法的成熟度模型,用于指导中大型团队实践看板方法,如下图所示:
配置管理的四个核心理念: 版本变更标准化,将一切纳入版本控制,全流程可追溯和单一可信数据源。
版本控制是配置管理中的一个非常核心的概念,而对于软件来说,最核心的资产就是源代码。
配置管理中的另一个核心概念是 变更。我们对软件做的任何改变都可以称之为一次变更,比如一个需求,一行代码,甚至是一个环境配置。 版本来源于变更。对于变更而言,核心就是要记录: 谁,在什么时间,做了什么改动,具体改了哪些内容,又是谁批准的。
用好版本控制系统也需要有一套规则和行为规范。比如,版本控制系统需要打通公司的统一认证系统,也就是任何人想要访问版本控制系统,都需要经过公司统一登录的认证。同时,在使用 Git 的时候,你需要正确配置本地信息,尤其是用户名和邮箱信息,这样才能在提交时生成完整的用户信息。另外,系统本身也需要增加相关的校验机制,避免由于员工配置错误导致无效信息被提交入库。
软件改动说明一般就是版本控制系统的提交记录,一个完整的提交记录应该至少包括以下几个方面的内容:
一套标准化的规则和行为习惯,可以降低协作过程中的沟通成本,一次性把事情做对,这也是标准和规范的重要意义。
标准化是自动化的前提,自动化又是 DevOps 最核心的实践。
软件源代码、配置文件、测试编译脚本、流水线配置、环境配置、数据库变更等等,你能想到的一切,皆有版本皆要被纳入管控。
这是因为,软件本身就是一个复杂的集合体,任何变更都可能带来问题,所以,全程版本控制赋予了我们全流程追溯的能力,并且可以快速回退到某个时间点的版本状态,这对于定位和修复问题是非常重要的。
如果这个产物可以通过其他产物来重现,那么就可以作为制品管理,而无需纳入版本控制。如软件包可以通过源代码和工具重新打包生成,那么,代码、工具和打包环境就需要纳入管控,而生成的软件包可以作为制品。
在出现问题时,就要追溯当时的全部数据,像软件源代码、测试报告、运行环境等等。
对于配置管理来说,除了追溯能力以外,还有一个重要的价值,就是记录关联和依赖关系。
对于软件开发来说,必须要有统一的管控:
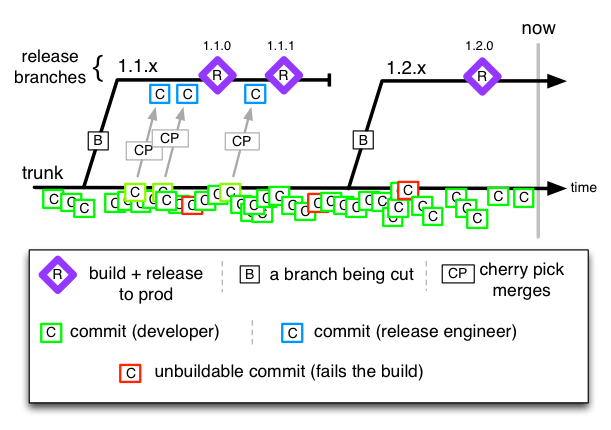
分支策略就是软件协作模式和发布模式的风向标。
在这种分支策略下,开发团队共享一条主干分支,所有的代码都直接提交到主干分支上,主干分支就相当于是一个代码的全量合集。在软件版本发布之前,会基于主干拉出一条以发布为目的的短分支。
需要注意的两点:
以发布为目的。这条分支存在的意义不是开发新功能,而是对现有功能进行验收,并在达到一定的质量标准后对外发布
短分支。这条发布分支一般不会存在太长时间,只要经过回归验证,满足发布标准后,就可以直接对外发布,这时,这条分支的历史使命也就结束了。只要在主干分支和发布分支并行存在的时间段内,所有发布分支上的改动都需要同步回主分支,这也是我们不希望这条分支存在时间过长的原因,因为这会导致重复工作量的线性累计。
优势:
缺点:
这些问题的解决方法包括以下几点:
当开发接到一个任务后,会基于主干拉出一条特性开发分支,在特性分支上完成功能开发验证之后,通过 Merge request 或者 Pull request 的方式发起合并请求,在评审通过后合入主干,并在主干完成功能的回归测试
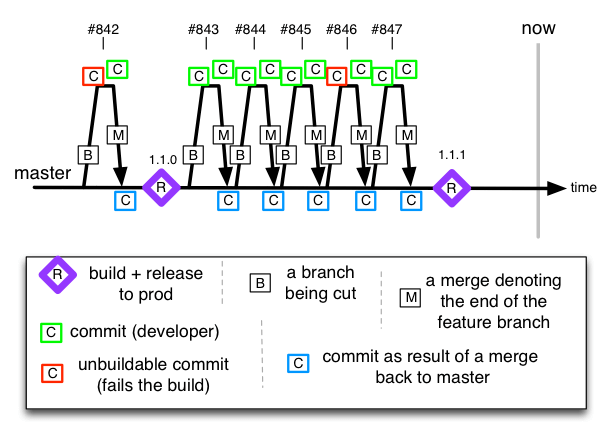
根据特性和团队的实际情况,还可以进一步细分为两种情况:
两者的区别就在于特性分支存活的周期,拉出时间越长,跟主干分支的差异就越大,分支合并回去的冲突也就越大。所以,对于长线模式来说,要么是模块拆分得比较清晰,不会有其他人动这块功能,要么就是保持同主干的频繁同步。 随着需求拆分粒度的变小,短分支的方式其实更合适。
优点:
特性发布虽然看起来很好,但是有三个前置条件:第一个是特性拆分得足够小,第二是有强大的测试环境作支撑,可以满足灵活的特性组合验证需求,第三是要有一套自动化的特性管理工具。
缺点:
团队只有一条分支,开发人员的代码改动都直接集成到这条主干分支上,同时,软件的发布也基于这条主干分支进行。
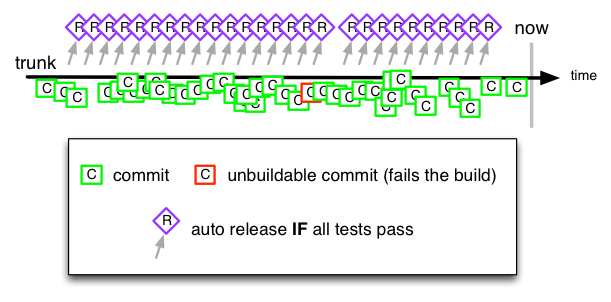
Facebook 最早采用的也是主干开发、分支发布的策略,每天固定发布两次。但是,随着业务发展的压力增大,团队对于发布频率有了更高的要求,这种分支策略已经无法满足每天多次发布的需求了。于是,他们开始着手改变分支策略,从主干开发、分支发布的模式,演变成了主干开发、主干发布的模式。
为了保证主干分支的质量,自动化验收手段是必不可少的,因此,每一次代码提交都会触发完整的编译构建、单元测试、代码扫描、自动化测试等过程。在代码合入主干后,会进行按需发布,先是发布到内部环境,也就是只有 Facebook 的员工才能看到这个版本,如果发现问题就立刻修复,如果没有问题,再进一步开放发布给 2% 的线上生产用户,同时自动化检测线上的反馈数据。直到确认一切正常,才会对所有用户开放。
最后,通过分支策略和发布策略的整合,注入自动化质量验收和线上数据反馈能力,最终将发布频率从固定的每天 2 次,提升到每天多次,甚至实现了按需发布的模式。Facebook最新的分支策略如图所示:
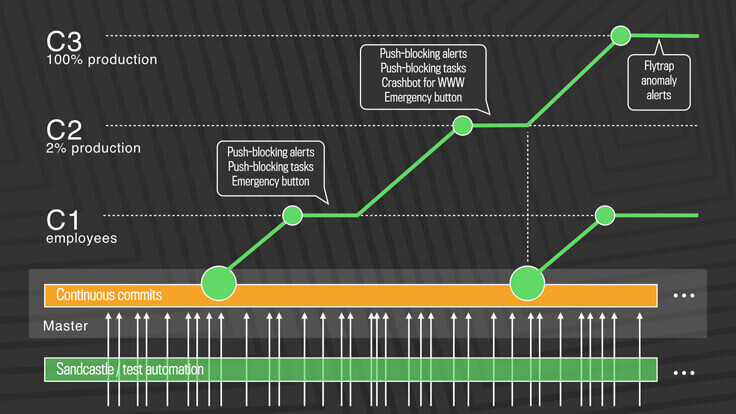
推荐: 主干开发结合特性分支的模式
团队共享一条开发主干,特性开发基于主干拉出特性分支,快速开发验收并回归主干,同时,在特性分支和主干分别建立不同的质量门禁和自动化验收能力。
这样做的好处在于,可以加快代码集成频率,特性相对独立清晰,并且主干分支又可以保持一定的质量水平。不过,在执行的过程中,你需要遵守以下原则:
CI 是 Continuous Integration 的缩写,也就是我们熟悉的持续集成,顾名思义,这里面有两个关键的问题:集成什么东西?为什么要持续?要回答这两个问题,就得从 CI 诞生的历史说起了。
CI 本身源于肯特·贝克(Kent Beck)在 1996 年提出的极限编程方法(ExtremeProgramming,简称 XP)。顾名思义,极限编程是一种软件开发方法,作为敏捷开发的方法之一,目的在于通过缩短开发周期,提高发布频率来提 升软件质量,改善用户需求响应速度。
关于 CI 的定义,我在这里引用一下马丁·福勒(Martin Fowler)的一篇博客中的内容,这也是当前最为业界公认的定义之一:
CI 是一种软件开发实践,团队成员频繁地将他们的工作成果集成到一起(通常每人每天至少提交一次,这样每天就会有多次集成),并且在每次提交后,自动触发运行一次包含自动化验证集的构建任务,以便尽早地发现集成问题。
践行 CI的三个问题:
每一次代码提交,是否都会触发一次完整的流水线?
第一个阶段的关键词是: 快速集成。这是对 CI 核心理念的最好诠释,也就是集成速度做到极致,每次变更都会触发 CI。
如果想做到每次提交都触发持续集成的话,首先就需要打通版本控制系统和持续集成系统
实施提交触发流水线,还需要一些前置条件。
统一的分支策略。
既然 CI 的目的是集成,那么首先就需要有一条以集成为目的的分支。这条分支可以是研发主线,也可以是专门的集成分支,一旦这条分支上发生任何变更,就会触发相应的 CI 过程。
清晰的集成规则。
对于研发特性分支而言,目的主要是快速验证和反馈,那么速度就是不可忽视的因素,所以这个层面的持续集成,主要以验证打包和代码质量为主;而对于系统集成分支而言,它的目的不仅是验证打包和代码质量,还要关注接口和业务层面的正确性,所以集成的步骤会更加复杂,成本也会随之上升。所以,根据分支策略选择合适的集成规则,对于 CI的有效运转来说非常重要。
标准化的资源池。
首先,资源池需要实现环境标准化,也就是任何任务在任何节点都具备可运行的能力,这个能力就包括了工具、配置等一系列要素。如果 CI 任务在一个节点可以运行,跑到另外一个节点就运行失败,那么 CI 的公信力就会受到影响。 另外,资源池的并发吞吐量应该可以满足集中提交的场景,可以动态按需初始化的资源池就成了最佳选择。当然,同时还要兼顾成本因素,因为大量资源的投入如果没有被有效利用,那么造成的浪费是巨大的。
足够快的反馈周期。
越是初级 CI,对速度的敏感性就越强。一般来讲,如果 CI 环节超过 10~15 分钟还没有反馈结果,那么研发人员就会失去耐心,所以 CI 的运行速度是一个需要纳入监控的重要指标。对于不同的系统而言,要约定能够容忍的 CI 最大时长,如果超过这个时长,同样会导致 CI 失败。所以,这就需要环境、平台、开发团队共同维护。
第二个阶段的关键词是: 质量内建。实际上,CI 的目的是尽早发现问题,这些问题既包括构建失败,也包括质量不达标,比如测试不通过,或者代码规约静态扫描等不符合标准。
匹配合适的测试活动。
对于不同层级的 CI 而言,同样需要根据集成规则来确定需要注入的质量活动。比如,最初级的提交集成就不适合那些运行过于复杂、时间太长的测试活动,快速的代码检查和冒烟测试就足以证明这个版本已经达到了最基本的要求。而对于系统层的集成来说,质量要求会更高,这样一来,一些接口测试、UI 测试等就可以纳入到 CI 里面来。
树立测试结果的公信度。
自动化测试的目标是帮助研发提前发现问题,但是,如果因为自动化测试能力自身的缺陷或者环境不稳定等因素,造成了 CI 的大量失败,那么,这个 CI 对于研发来说就可有可无了。所以,我们要对 CI 失败进行分类分级,重点关注那些异常和误报的情况,并进行相应的持续优化和改善。
提升测试活动的有效性。
考虑到 CI 对于速度的敏感性,那么如何在最短的时间内运行最有效的测试任务,就成了一个关键问题。显然,大而全的测试套件是不合时宜的,只有在基础功能验证的基础上,结合与本次 CI 的变更点相关的测试任务,发现问题的概率才会大大提升。所以,根据 CI 变更,自动识别匹配对应的测试任务也是一个挑战。
利用现有的开源工具和框架快速搭建一套 CI 平台并不困难, 真正让 CI 发挥价值的关键,还是在于团队面对持续集成的态度,以及团队内是否建立了持续集成的文化。
在CI 的修复时间中, 人不是关键,建立机制才是关键。
什么是机制呢? 机制就是一种约定,人们愿意遵守这样的行为,并且做了会得到好处。对于CI 而言,保证集成主线的可用性,其实就是团队成员间的一种约定。这不在于谁出的问题谁去修复,而在于我们是否能够保证 CI 的稳定性,足够清楚问题的降级路径,并且主动关注、分析和推动问题解决。
另外,团队要建立清晰的规则,比如 10 分钟内没有修复则自动回滚代码,比如当 CI“亮红灯”的时候,团队不再提交新的代码,因为在错误的基础上没有办法验证新的提交,这时需要集体放下手中的工作,共同恢复 CI 的状态。
自动化测试要解决什么问题?
产品交付速度的提升,给测试工作带来了很大的挑战。一方面,测试时间被不断压缩,以前三天的测试工作要在一天内完成。另一方面,需求的变化也给测试工作的开展带来了很大的不确定性。这背后核心的问题是, 业务功能的累加导致测试范围不断扩大,但这跟测试时长的压缩是矛盾的。说白了,就是要测试的内容越来越多,但是测试的时间却越来越短。
要想提升测试效率,自然就会联想到自动化手段。
自动化测试适用于以下几种典型场景:
自动化测试建设也面临着一些问题:
投入产出比:很多需求基本上只会上线一次(比如促销活动类需求),那么,实现自动化测试的成本要比手动测试高得多,而且以后也不会再用了,这显然有点得不偿失。
介绍一下经典的测试三角形。这个模型描述了从单元测试、集成测试到 UI测试的渐进式测试过程。越是靠近底层,用例的执行速度就越快,维护成本也越低。而在最上层的 UI 层,执行速度要比单元测试和接口测试要慢,比手工测试要快,相应的维护成本要远高于单元测试和接口测试
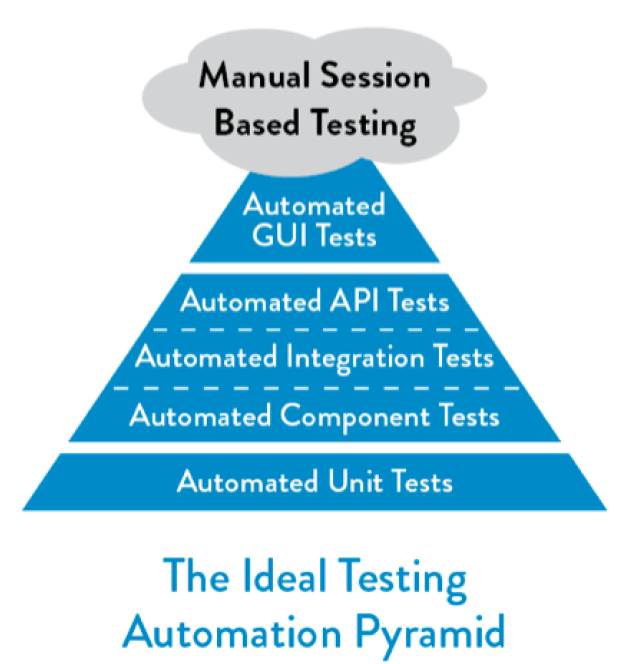
这样看来,从靠近底层的单元测试入手是一个投入产出相对比较高的选择。但实际上,单元测试的执行情况因公司而异,有的公司能做到 80% 的覆盖率,但有的公司却寸步难行。毕竟,单元测试更多是由开发主导的,开发领导的态度就决定了运行的效果。但不可否认的是,单元测试还是非常必要的,尤其是针对核心服务,比如核心交易模块的覆盖率。当然,好的单元测试需要研发投入大量的精力。
对于 UI 层来说,执行速度和维护成本走向了另外一个极端,这也并不意味着就没有必要投入 UI 自动化建设。 UI 层是唯一能够模拟用户真实操作场景的端到端测试,页面上的一个按钮可能触发内部几十个函数调用,和单元测试每次只检查一个函数的逻辑不同,UI 测试更加关注模块集成后的联动逻辑, 是集成测试最有效的手段。
在实际应用中,UI 自动化可以帮助我们节省人工测试成本,提高功能测试的测试效率。不过,它的缺点也是比较明显的: 随着敏捷迭代的速度越来越快,UI 控件的频繁变更会导致控件定位不稳定,提高了用例脚本的维护成本。
对于基于 Web 的应用来说,我更推荐椭圆形模型,也就是以中间层的 API接口测试为主,以单元测试和 UI 测试为辅。你可以参考一下分层自动化测试模型图。
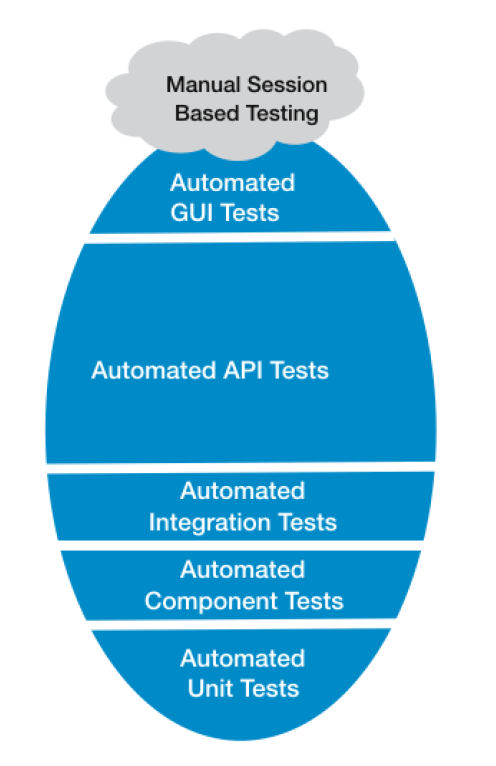
有效的自动化测试离不开工具和平台的支持。以接口测试为例,最早都是通过 cURL、Postman、JMeter 等工具单机执行的。但是,一次成功的接口测试,除了能够发起服务请求之外,还需要前置的测试数据准备和后置的测试结果校验。对于企业的实际业务来说,不仅需要单接口的执行,还需要相对复杂的多接口,而且带有逻辑的执行,这就依赖于调用接口的编排能力,甚至是内建的 Mock 服务。
不仅如此,测试数据、用例、脚本的管理,测试过程中数据的收集、度量、分析和展示,以及测试报告的发送等,都是一个成熟的自动化测试框架应该具备的功能。
那么,我们该如何衡量自动化测试的结果呢?当前比较常用的方式是覆盖率,不过问题是,测试覆盖率提升就能发现更多的缺陷吗?
在实际项目中,手工测试发现的缺陷数量要比自动化测试发现的缺陷数量多得多。自动化测试更多是在帮助守住软件质量的底线,尤其是应用在回归测试中,自动化测试可以确保工作正常的已有功能不会因为新功能的引入而带来质量回退。可以这么说, 如果自动化测试覆盖率足够高,那么软件质量一定不会差到哪儿去。
关于测试误报,是指由于非开发代码变更导致的自动化测试用例执行失败的情况。业界对于误报率的普遍定义是:
自动化测试误报率 = 非开发变更引入的问题用例数量 / 测试失败的用例数量
测试误报率是体现自动化测试稳定性的一个核心指标。对于不同测试类型和产品形态,误报的的原因有很多。比如测试环境的网络不稳定导致的连接超时、测试脚本和测试工具本身的固有缺陷导致的执行失败、测试数据不齐备、测试资源不可用等等。
如何解决自动化测试并给出了测试结果,但还是需要人工审查判断之后,才能将真正的问题上报缺陷系统的问题?这就要依赖于自动化测试结果的分析啦。
增加已有分类的自动识别能力。比如,对于捕获到的常见异常,可以根据异常信息自动上报到对应的错误分类,从而简化人工识别和归类错误的工作量。
不应该将质量依赖于检验工作,因为检验工作既昂贵,又不可靠。最重要的是,检验工作并不直接提升产品质量,只是为了证明质量有缺陷。而正确的做法是将质量内建于整个流程之中,并通过有效的控制手段来证明流程自身的有效性。
内建质量有两个核心原则:
在需求环节,可以定义清晰的需求准入规则,比如需求的价值衡量指标是否客观、需求的技术可行性是否经过了验证、需求的依赖是否充分评估、需求描述是否清晰、需求拆分是否合理、需求验收条件是否明确等等。
在开发阶段,代码评审和持续集成就是一个非常好的内建质量的实践。在代码评审中,要尽量确认编码是否和需求相匹配,业务逻辑是否清晰。另外,通过一系列的自动化检查机制,来验证编码风格、风险、安全漏洞等。
在测试阶段,可以通过各类自动化测试,以及手工探索测试,覆盖安全、性能、可靠性等,来保障产品质量;在部署和发布阶段,可以增加数据库监控、危险操作扫描、线上业务监控等多种手段。
研发环节作为整个软件产品的源头,是内建质量的最佳选择。
选择投入产出比相对比较高的检查类型,是一种合理的策略。比如代码风格与缺陷漏洞相比,检查缺陷漏洞显然更加重要,因为一旦发生代码缺陷和漏洞,就会引发线上事故。所以,这么看来,如果是客户端业务,Infer 扫描就可以优先实施起来。虽然我们不能忽视编码风格问题,但这并不是需要第一时间强制执行的。
指标项是针对检查类型所采纳的具体指标,比如单元测试覆盖率这个检查项,可采纳的指标就包括行、指令、类、函数等。那么,我们要以哪个为准呢?这个一般需要同研发负责人达成一致,并兼顾行业的一些典型做法,比如单测行覆盖率就是一个比较好的选择。
参考值的定义是一门艺术。对于不同的项目,甚至是同一个项目的不同模块来说,我们很难用“一刀切”的方式定义数值。我比较推荐的做法是将静态指标和动态指标结合起来使用。
静态指标就是固定值,对于漏洞、安全等问题来说,采取零容忍的态度,只要存在就绝不放过。 而动态指标是以考查增量和趋势为主,比如基线值是 100,你就可以将参考值定义成小于等于 100,也就是不允许增加。你还可以根据不同的问题等级,定义不同的参考值,比如严格检查致命和阻塞问题,其余的不做限制。
最后,对于这个指标,你一定要跟研发团队达成共识,也就是说,团队要能够认可并且执行下去。所以,定义指标的时候要充分采纳对方的建议。
按照快速失败的原则,质量门禁的生效节点要尽量靠近指标数据的产生环节。比如,如果要检查编码风格,最佳的时间点是在研发本地的 IDE 中进行,其次是在版本控制系统中进行并反馈结果,而不是到了最后发布的时间点再反馈失败。
现代持续交付流水线平台都具备质量门禁的功能,常见的配置和生效方式有两种:
一般来说,质量门禁都具有强制属性,也就是说,如果没有达到检查指标,就会立即停止并给予反馈。
在实际执行的过程中,质量门禁的结果可能存在多种选项,比如失败、告警、人工确认等。这些都需要在制定规则的时候定义清楚,通过一定的告警值和人工确认方式,可以对质量进行渐进式管控,以达到持续优化的目标。
另外,你需要对所有软件交付团队成员宣导质量规则和门禁标准,并明确通知方式、失败的处理方式等。否则,检查出问题却没人处理,这个门禁就形同虚设了。
无论是检查能力、指标、参考值,还是处理方式,只有在运行起来后才能知道是否有问题。所以,在推行的初期,也应该具备一定程度的灵活性,比如对指标规则的修订、指标级别和参考值的调整等, 核心目标不是为了通过质量门禁,而是为了质量提升,这才是最重要的。
| 常见问题 | 处理建议 |
|---|---|
| 虽然有质量门禁,但是并没有强制生效。 | 分析不强制的原因,选择核心检查项启用强制规则,比如Critical和Blocker级别的问题,必须要解决。 |
| 规则有效性存在争议。 | 重新评审规则库,支持规则库自定义或者分级调整。在评审规则库时,核心就是要有务实的态度和开放的心态。务实是对真正对团队有用的规则达成共识,开放是允许团队针对规则提出意见。 |
| 采用人工审批的方式绕过门禁。 | 尽量减少让不了解详情的人员进行审批,因为这样做除了出问题一起背锅,并没有什么实质作用。 |
| 质量规则长期不更新。 | 建立定期质量规则更新机制,根据实际执行效果不断优化。 |
| 检查时间过长。 | 调整扫描频率和检查项内容,优化检查效率。 |
| 检查失败率高。 | 优化系统的稳定性。 |
| 质量数据丢失。 | 对每一次的执行数据进行归档,保证历史数据可见。 |
技术债务,就是指团队在开发过程中,为了实现短期目标选择了一种权宜之计,而非更好的解决方案,所要付出的代价。这个代价就是团队后续维护这套代码的额外工作成本,并且只要是债务就会有利息,债务偿还得越晚,代价也就越高。
如何对代码的技术债务进行分类呢?我们可以借用“Sonar Code QualityTesting Essentials”一书中的代码“七宗罪”,也就是 复杂性、重复代码、代码规范、注释有效性、测试覆盖度、潜在缺陷和系统架构七种典型问题。你可以参考一下这七种类型对应的解释和描述:
| 类型 | 影响 |
|---|---|
| 不能均匀分布的复杂性 | 较高的圈复杂度需要更多的测试才能覆盖到全路径,导致潜在的功能质量风险。 |
| 重复代码 | 重复代码是最严重的问题,会导致潜在缺陷。另外,重复也会带来维护成本的增加。 |
| 不合适的注释 | 代码的注释没有明确标准。缺少关键环节的注释或者是注释难以理解,都会导致代码的可读性变差。 |
| 违反代码规范 | 影像团队基于共同的规范进行写作,会增加潜在的风险。 |
| 缺乏单元测试 | 单元测试不足会影响团队对代码的信心,增加重构成本,通过测试覆盖率对其进行度量。 |
| 缺陷和潜在的缺陷 | 缺陷和潜在缺陷是最直接影响代码质量的要素,要尽可能地发现并修复。 |
| 设计和系统架构 | 设计和系统架构受限于当时的资源条件,可能无法满足后续产品的发展需求,所以需要持续演进。 |
技术债务最直接的影响就是内部代码质量的高低。如果软件内部质量很差,会带来 3 个方面的影响:
额外的研发成本
软件开发不像是银行贷款,技术债务看不见摸不着,所以,我们需要一套计算方法把这种债务量化出来。目前业界比较常用的开源软件,就是 SonarQube。在 SonarQube 中,技术债是基于 SQALE 方法计算出来的。关于SQALE,全称是 Software QualityAssessment based on Lifecycle Expectations,这是一种开源算法。
Sonar 通过将不同类型的规则,按照一套标准的算法进行识别和统计,最终汇总成一个时间,也就是说,要解决扫描出来的这些问题,需要花费的时间成本大概是多少,从而对代码质量有一种直观的认识。
计算出来的技术债务会因为开启的规则数量和种类的不同而不同。
另外,在 Sonar 中,还有一个更加直观的指标来表示代码质量,这就是 SQALE 级别。SQALE 的级别为 A、B、C、D、E,其中 A 是最高等级,意味着代码质量水平最高。级别的算法完全是基于技术债务比例得来的。简单来说,就是 根据当前代码的行数,计算修复技术债务的时间成本和完全重写这个代码的时间成本的比例。
技术债务比例 = 修复已有技术债务的时间 / 完全重写全部代码的时间
解决技术债务,有哪些步骤呢?
在解决技术债务的过程中,要遵循 4 条原则。
制定规则的建议:
第一,参考代码质量平台的默认问题级别。一般来说,阻塞和严重的问题的优先级比一般问题更高,这也是基于代码质量平台长时间的专业积累得出的结论。
第二,你可以参考业界优秀公司的实践经验,比如很多公司都在参考阿里巴巴的 Java 开发手册,京东也有自己的编码规约。
影响比较大的问题类型,建议你优先进行处理:
环境管理的挑战
1.环境种类繁多
2.环境复杂性上升
3.环境一致性难以保证
4.环境交付速度慢
5.环境变更难以追溯
解决这些问题的方法就是是 基础设施即代码。可以这么说,如果没有采用基础设施即代码的实践,DevOps 一定走不远。
基础设施即代码
基础设施即代码就是用一种描述性的语言,通过文本管理环境配置,并且自动化完成环境配置的方式。典型的就是以 CAPS 为代表的自动化环境配置管理工具,也就是 Chef、Ansible、Puppet 和 Saltstacks 四个开源工具的首字母缩写。
首先, 通过将所有环境的配置过程代码化,每个环境都对应一份配置文件,可以实现公共配置的复用。
其次,环境的配置过程,完全可以使用工具自动化批量完成。你只需要引用对应环境的配置文件即可,剩下的事情都交给工具。
最后,既然环境配置变成了代码,自然可以直接纳入版本控制系统中进行管理,享受版本控制的福利。任何环境的配置变更都可以通过类似 Git 命令的方式来实现,不仅收敛了环境配置的入口,还让所有的环境变更都完全可追溯。
基础设施即代码的实践,通过人人可以读懂的代码将原本复杂的技术简单化,这样一来,即便是团队中不懂运维的角色,也能看懂和修改这个过程。这不仅让团队成员有了一种共同的语言,还大大减少了不同角色之间的依赖,降低了沟通协作成本。这也是基础设施即代码的隐形价值所在,特别符合 DevOps 所倡导的协作原则。
在大多数公司,部署上线的工作都是由专职的运维团队来负责,开发团队只要将测试通过的软件包提供给运维团队就行了。所以, 开发和运维的自然边界就在于软件包交付的环节,只有打通开发环节的软件集成验收的 CI 流水线和运维环节的应用部署 CD 流水线上线,才能真正实现开发运维的一体化。而当版本控制系统遇上基础设施即代码,就形成了一种绝妙的组合,那就是 GitOps。
开发运维打通的 GitOps 实践
顾名思义,GitOps 就是 基于版本控制系统 Git 来实现的一套解决方案,核心在于基于 Git这样一个统一的数据源,通过类似代码提交过程中的拉取请求的方式,也就是 Pull/Request,来完成应用从开发到运维的交付过程,让开发和运维之间的协作可以基于 Git 来实现。
虽然 GitOps 最初是基于容器技术和 Kubernetes 平台来实现的,但它的理念并不局限于使用容器技术,实际上,它的核心在于通过代码化的方式来描述应用部署的环境和部署过程。
在 GitOps 中, 每一个环境对应一个环境配置仓库,这个仓库中包含了应用部署所需要的一切过程。比如,使用 Kubernetes 的时候,就是应用的一组资源描述文件,比如部署哪个版本,开放哪些端口,部署过程是怎样的。
GitOps的部署流程图
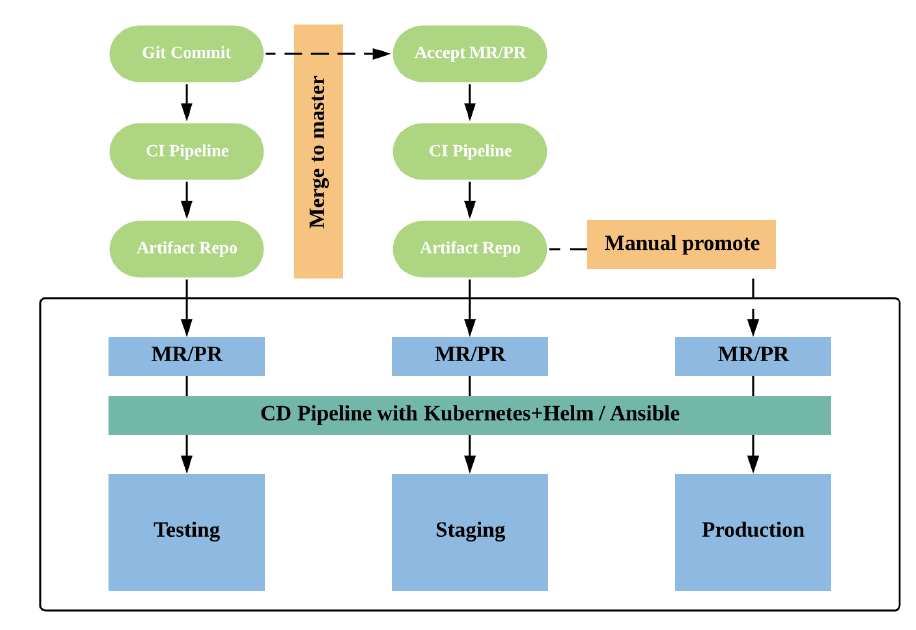
以测试环境为例的主要流程:
GitOps 的好处究竟有哪些呢?
开发环境的治理实践
可以采用基础设施即代码的方法,生成一个包含全部工具依赖的Docker 镜像,并分发给开发团队。在开发时仅需要拉起一个容器,将代码目录挂载进去,就可以生成一个完全标准化的研发环境。当工具版本升级时,可以重新制作一个新的镜像,开发本地拉取后,所有的工具就升级完成了,这大大简化了研发环境的维护成本。
关于如何解决开发本地测试的问题,在 Jenkins 社区也有一些相关的实践。
比如,你基于 Kubernetes 创建了一套最小测试环境,按照正常过程来说,如果改动一行代码,你需要经过代码提交、打包镜像、上传制品、更新服务器镜像等,才能开始调试。但如果你使用KSync工具,这些过程统统可以省略。KSync 可以帮你建立本地工作空间和远端容器目录的关联,并自动同步代码。也就是说,只要在本地 IDE 里面修改了一行代码,保存之后,KSync 就可以帮你把本地代码传到线上的容器中,对于类似 Python 这样的解释型语言来说特别省事。
谷歌也开源了一套基于容器开发自动部署工具Skaffold,跟 KSync 类似,使用 Skaffold命令就可以创建一套 Kubernetes 环境。当本地修改一行代码之后,Skaffold 会自动帮你重新生成镜像文件,推送远端,并部署生效,让代码开发变得所见即所得。研发只需要专注于写代码这件事情,其余的全部自动化,这也是未来 DevOps 工程实践的一个发展方向。
部署是一组技术实践,表示通过技术手段,将本次开发测试完成的功能实体(比如代码、二进制包、配置文件、数据库等)应用到指定环境的过程,包括开发环境、预发布环境、生产环境等。部署的结果是对服务器进行变更,但是这个变更结果不一定对外可见。
发布,也就是 Release,更偏向一种业务实践,也就是将部署完成的功能正式生效,对用户可见和提供服务的程。
DevOps 模式下, 质量思想发生了转变。简单概括就是: 要在保障一定的质量水平的前提下,尽量加快发布节奏,并通过低风险发布手段,以及线上测试和监控能力,尽早地发现问题,并以一种最简单的手段来快速恢复。
一定的质量水平
对于互联网这种快速迭代的业务来说,大家都习惯了默认会出问题,所以在圈定测试范围和测试覆盖的基础上,只要完成严重问题的修复即可发布,低级别的问题可以在后续的众测和灰度的环节继续处理。
所以,与定义一个发布质量标准相比,更重要的随着 DevOps 的推广,扭转团队的质量观念。 质量不再是测试团队自身的事情,而是整个交付团队的事情。如果出现了线上问题,团队要一起来定位和修复,并且反思如何避免类似的问题再次发生,从失败中学习。
低风险的发布手段
既然发布是一件不可回避的高风险事情,那么,为了降低发布活动的风险,就需要有一些手段了。典型的包括以下几种:蓝绿部署,灰度发布和暗部署。
线上测试和监控
如何做线上验证呢?比较常见的,有三种手段。
在互联网产品中, 埋点是一种最常用的产品分析和数据采集方法,也是数据驱动决策的主要依据之一。它的价值就在于,根据预先设计的收集和监控数据的方法,采集用户的行为、产品质量、运营数据等多维度的数据。
除了自动化的采集数据之外,用户主动的反馈也是获取产品信息的第一手资料。而用户反馈的渠道有很多,公司里面一般都有用户运营和舆情监控系统,用于按照“关键字”等自动爬取各个主流渠道的产品信息。一旦发现负面的反馈,就第一时间进行止损。
使用线上流量测试。
最常用的就是将线上真实的用户流量复制下来,以实时或者离线的方式回放到预发布环境中用于功能测试。
快速恢复
初步对问题进行分析定位后,你可以有两种选择:向前修复和向后回滚。
向前修复就是快速修改代码并发布一个新版本上线,向后回滚就是将系统部署的应用版本回滚到前一个稳定版本。
在出现问题系统可以自动修复, 就是故障自愈。故障自愈的第一步,就要做好服务降级和兜底策略。
服务降级就是指,在流量高峰的时候,将非主路径上的功能进行临时下线,保证业务的可用性。典型的做法就是通过功能开关的方式来手动或自动地屏蔽一些功能。
兜底策略是指,当极端情况发生时,比如服务不响应、网络连接中断,或者调用服务出现异常的时候,也不会出现崩溃。常见的做法就是缓存和兜底页面,以及前端比较流行的骨架屏等。
混沌工程作为软件领域的一门新兴学科,就和它的名字一样,让很多人感到非常“混沌”。
那么,混沌工程究竟是从何而来,又是要解决什么问题呢?我们先来看看混沌原则网站对混沌工程的定义:
Chaos Engineering is the discipline of experimenting on a distributed system inorder to build confidence in the system’s capability to withstand turbulent conditions in production.
混沌工程是一门在分布式系统上进行实验的学科,目的是建立人们对于复杂系统在生产环境中抵御突发事件的信心。
简单来说,混沌工程要解决的,就是复杂环境下的分布式系统的反脆弱问题。那么,我们所要面对的“复杂的分布式”的真实世界是怎样的呢?
随着微服务、容器化等技术的兴起,业务驱动自组织团队独立发布的频率越来越高,再加上架构的不断更新演进,可以说,几乎没有人能完整地梳理清楚一套系统的服务间调用关系,这就让复杂系统变成了一个“黑洞”。不管外围如何敲敲打打,都很难窥探到核心问题。
区别于以往的方式,混沌工程采取了一种更加积极的方式,换了一个思路主动出击。那就是, 尽可能在这些故障和缺陷发生之前,通过一系列的实验,在真实环境中验证系统在故障发生时的表现。根据实验的结果来识别风险问题,并且有针对性地进行系统改造和安全加固,从而提升对于整个系统可用性的信心。
服务可用性实践
故障演练就是针对以往发生过的问题进行有针对性地模拟演练。通过事先定义好的演练范围,然后人为模拟事故发生,触发应急响应预案,快速地进行故障定位和服务切换,并观察整个过程的耗时和各项数据指标的表现。
故障演练针对的大多是可以预见到的问题,比如机器层面的物理机异常关机、断电,设备层面的磁盘空间写满、I/O 变慢,网络层面的网络延迟、DNS 解析异常等。这些问题说起来事无巨细,但基本上都有一条清晰的路径,有明确的触发因素,监控事项和解决方法。
从业务层面来说,面对多变的环境因素,完善的服务降级预案和系统兜底机制也是必不可少的。在业务压力比较大的时候,可以适当地屏蔽一些对用户感知不大的服务,比如推荐、辅助工具、日志打印、状态提示等,保证最核心流程的可用性。另外,适当地 引入排队机制也能在一定程度上分散瞬时压力。
必须要强调的是,在引入混沌工程的实践之前,首先需要确保现有的服务已经具备了弹性模式,并且能够在应急响应预案和自动化工具的支撑下尽早解决可能出现的问题。
混沌工程的五大原则:建立稳定状态的假设、真实世界的事件、在生产中试验、持续的自动化实验、最小影响范围。
建立稳定状态的假设
关于系统的稳定状态,就是说,有哪些指标可以证明当前系统是正常的、健康的。实际上,无论是技术指标,还是业务指标,现有的监控系统都已经足够强大了,稍微有一点抖动,都能在第一时间发现这些问题。
| 指标类型 | 指标示例 |
|---|---|
| 业务核心指标 | 用户数、活跃用户数、新增用户数、订单量、GMV、平均客单价、转化率、订单成功率、订单取消率、订单退货率、商品和商家数量 |
| 业务访问指标 | UV、PV、点击率、首页到达率、商品到达率、评论到达率 |
| 用户体验指标 | 用户满意度、用户投诉数量、用户反馈数量、订单好评率、订单差评率 |
| 系统指标 | QPS、TPS、CPU使用率、CPU负载、内存使用率、网络连接数、平均响应时长、404数量 |
真实世界的事件
真实世界的很多问题都来源于过往踩过的“坑”,即便是特别不起眼的事件,都会带来严重的后果。
我们无法模拟所有的异常事情, 投入产出比最高的就是选择重要指标(比如设备可用性、网络延迟,以及各类服务器问题),进行有针对性地实验。另外,可以结合类似全链路压测等手段,从全局视角测试系统整体运作的可用性,通过和稳定状态的假设指标进行对比,来识别潜在的问题。
在生产中实验
真实世界的问题,只有在生产环境中才会出现。一个小规模的预发布环境更多的是验证系统行为和功能符合产品设计,也就是从功能的角度出发,来验证有没有新增缺陷和质量回退。 但是,系统的行为会根据真实的流量和用户的行为而改变。比如,流量明星的一则消息就可能导致微博的系统崩溃,这是在测试环境很难复现的场景。
但客观来说,在生产环境中进行实验,的确存在风险,这就要求实验范围可控,并且具备随时停止实验的能力。还是最开始的那个原则,如果系统没有为弹性模式做好准备,那么就不要开启生产实验。
还以压测为例,我们可以随机选择部分业务模块,并圈定部分实验节点,然后开启常态化压测。通过定期将线上流量打到被测业务上,观察突发流量下的指标表现,以及是否会引发系统雪崩,断路器是否生效等, 往往在没有准备的时候才能发现真实问题。这种手段作为混沌工程的一种实践,已经普遍应用到大型公司的在线系统之中了。
持续的自动化实验
自动化是所有重复性活动的最佳解决方案。通过自动化的实验和自动化结果分析,我们可以保证混沌工程的诸多实践可以低成本、自动化地执行。正因为如此,以混沌工程为名的工具越来越多。
比如,商业化的混沌工程平台 Gremlins 就可以支持不可用依赖、网络不可达、突发流量等场景。阿里也开源了他们的混沌工具ChaosBlade,缩短了构建混沌工程的路径,引入了更多的实践场景。另外,开源的Resilience4j和 Hystrix也都是非常好用的工具。无论是自研,还是直接采用,都可以帮助你快速上手。
最小的影响范围
混沌工程实践的原则就是不要干扰真实用户的使用,所以,在一开始将实验控制在一个较小的范围内,是非常有必要的,这样可以避免由于实验失控带来的更大问题。
度量不是目的,而是手段,也就是说度量的目标是“做正确的事”,而度量的手段是“正确地做事”。
好的指标大多具备一些典型的特征。
明确受众。
指标不能脱离受众而单独存在,在定义指标的同时,要定义它所关联的对象,也就是这个指标是给谁看。
直指问题。
一看到这个指标,就能意识到问题所在,并自然而然地进行改进,而不是看了跟没看见一样,也不知道具体要做什么。
量化趋势。
按照 SMART 原则,好的指标应该是可以衡量的,而且是可以通过客观数据来自证的。
充满张力。
指标不应该孤立存在,而是应该相互关联构成一个整体。好的指标应该具有一定的张力,向上可以归并到业务结果,向下可以层层分解到具体细节。这样通过不同维度的数据抽取,可以满足不同视角的用户需求。
交付效率
需求前置时间:从需求提出到完成整个研发交付过程,并最终上线发布的时间。对业务方和用户来说,这个时间是最能客观反映团队交付速度的指标。这个指标还可以进一步细分为需求侧,也就是从需求提出、分析、设计、评审到就绪的时长,以及业务侧,也就是研发排期、开发、测试、验收、发布的时长。对于价值流分析来说,这就代表了完整的价值流时长。 开发前置时间:从需求进入排期、研发真正动工的时间点开始,一直到最终上线发布的时长。它体现的是研发团队的交付能力,也就是一个需求进来后,要花多久才能完成整个开发过程。
交付能力
发布频率:单位时间内的系统发布次数。原则上发布频率越高,代表交付能力越强。这依赖于架构结构和团队自治、独立发布的能力。每个团队都可以按照自己的节奏安全地发布,而不依赖于关联系统和发布窗口期的约束。 发布前置时间:指研发提交一行代码到最终上线发布的时间,是团队持续交付工程能力的最直观的考查指标,依赖于全流程自动化的流水线能力和自动化测试能力。这也是DevOps 状态报告中的核心指标之一。 交付吞吐量:单位时间内交付的需求点数。也就是,单位时间内交付的需求个数乘以需求颗粒度,换算出来的点数,它可以体现出标准需求颗粒度下的团队交付能力。
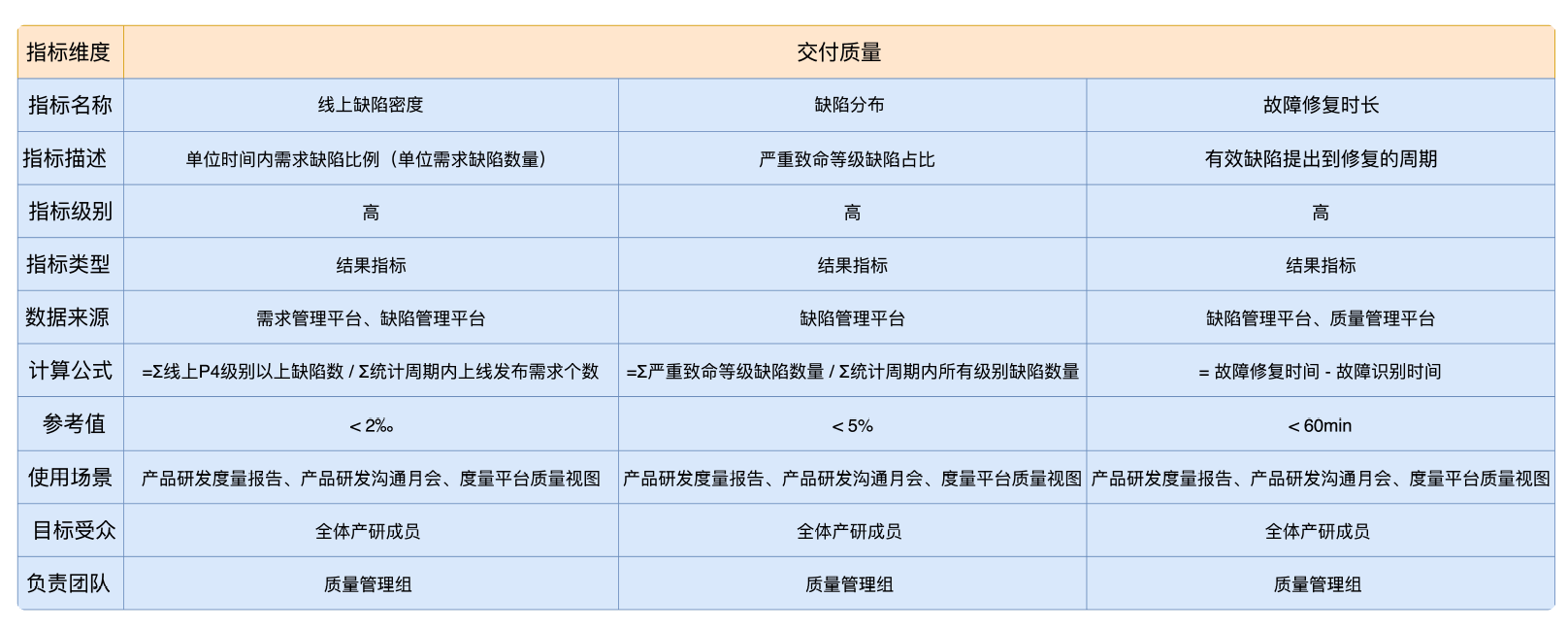
交付质量
线上缺陷密度:单位时间内需求缺陷比例,也就是平均每个需求所产生的缺陷数量,缺陷越多,说明需求交付质量越差。 线上缺陷分布:所有缺陷中的严重致命等级缺陷所占的比例。这个比例的数值越高,说明缺陷等级越严重,体现了质量的整体可控性。 故障修复时长:从有效缺陷提出到修复完成并上线发布的时间。一方面,这个指标考查了故障定位和修复的时间,另外一方面,也考查了发布前置时间,只有更快地完成发布上线过程,才能更快地修复问题。
在企业内部开启度量工作,可以分为四个步骤。
一个完整的指标,除了定义之外,还需要明确指标名、指标描述、指标级别(团队级 / 组织级)、指标类型、适用场景范围及目标用户、数据采集方式和标准参考值。
以交付指标为例,我汇总了一份细化后的指标内容,你可以参考下表。其实不仅仅是核心结果指标,只要是在度量体系内定义的指标,都需要进行细化。
度量指标需要客观数据的支撑,而数据往往都来源于各个不同的平台。所以,在定义指标的时候,你需要评估是否有足够的客观数据来支撑这个指标的衡量。
需要从流程和平台两个层面入手解决。比如,一方面,从流程层面制定研发操作规范,让每一名研发人员都清楚在什么时间点需要改变需求卡片状态;另一方面,建设平台能力,提供易用性的方式辅助研发,甚至自动流转需求状态。
度量指标毕竟是要给人看的,度量数据也需要有一个地方可以收集和运算,这就依赖于度量可视化平台的建设了。
当数据做到了可信和可视化之后,团队面临的问题和瓶颈会自然而然浮现出来。
DevOps 做到什么程度,就算是实现转型落地了?那么,我的回答是, 核心就是团队已经具备了持续改进的能力,而不只是简简单单地引入了几个工具,建立了几个度量指标而已
持续改进的意义到底是什么呢?为什么一切活动的终极目标都是持续改进呢?
这是因为,每家公司面临的问题都不一样,从 0 到 1 的过程相对比较简单,可以对照着工程实践,快速地引入工具,建立流程,补齐能力短板。但是,从 1 到 N 的过程,就需要团队根据业务需要,自行识别改进目标了。
谈到持续改进,有一个非常著名的方法体系,叫作 PDCA,也称为 戴明环。没错,你从名称就能看出,这套方法体系同样来自于质量管理大师戴明博士。PDCA 是四个英文单词的缩写,也就是 Plan(计划)、Do(实施)、Check(检查)和 Action(行动)。
PDCA 提供了一套结构化的实施框架,任何一项改进类工作,都可以划分为这四个实施阶段。 通过 PDCA 循环的不断迭代,驱动组织进入一种良性循环,不断识别出新的待改进问题。针对这些问题,首先要进行根因分析,制定具体的实施计划。然后,不定期地检查实施的结果和预期目标是否一致。最后,要对改进结果进行复盘,把做得好的地方保留下来,把做得不好的地方纳入下一阶段的循环中,继续改进。
构建持续改进的核心,就在于构建一个学习型组织。
从失败中学习是我们从小就懂的道理。一个团队对待故障的态度,很大程度上就反映了他们对于持续改进的态度。系统出现故障是谁都不愿意遇到的事情,但在真实世界中,这是没法避免的。
故障回溯并不一定以确定责任为第一要务, 更重要的是,要识别系统流程中的潜在问题和漏洞,并通过后续机制来进行保障,比如增加测试用例、增加产品走查事项等等。
在团队的日常迭代中,事先给改进类工作预留一部分时间,或者是在业务相对不那么繁忙的时候(比如大促刚刚结束,团队在调整状态的时候),在改进工作上多花些时间。
这些工作量主要用于解决非功能需求、技术改进类问题,比如修复技术债务、单元测试用例补充、度量识别出来的改进事项等。通过将这部分改进时间固定下来,可以培养团队持续改进的文化。
我比较推荐的做法是,在团队的 Backlog 中新增一类任务,专门用于记录和跟踪这类持续改进的内容。在迭代计划会议上,对这类问题进行分析,并预估工作量,保证团队有固定的时间来应对这些问题。
对于业务的指标和表现,需要尽可能地在团队内部做到透明,让团队成员可以接触真实世界的用户反馈和评价,以及业务的度量信息。
在一个新功能开发完成上线之后,要能实时查看这个需求的上线状态。如果需求分析时已经关联了业务考核指标,那么,同样可以将该业务关联的指标数据进行展示。这样,研发就会知道自己交付的内容有多少问题,用户的真实反馈是怎样的,从而促使团队更多地站在用户的视角思考问题。
除了业务指标,DevOps 的指标体系也应该对内部公开透明。大家可以查看自己所在团队的表现,以及在公司内部的整体水平。
在团队成员的绩效目标中,增加对团队贡献和技术创新的要求,在团队内部鼓励创新类工作。另外,在团队内部建立对应的选拔和激励机制,为好的想法投入资源,把它们变成可以解决类似问题的工具。
很多公司也开始注意到这种内部知识复用的重要性,所以,无论是代码库开源,还是公共基础组件的市的建设,甚至是公司级的平台治理系统,都可以帮助你快速地复用已有的能力,避免一直重复造轮子。
企业DevOps平台建设的三个阶段
在这个阶段,企业的 DevOps 平台建设处于刚刚起步的状态,在整个交付过程中,还有大量的本地操作和重复性的操作。 另外,企业内部一般也没有一个成体系的工具团队,来专门负责平台能力建设。那么,对于这个阶段,我给你的建议是: 引入开源工具和商业工具,快速补齐现有的能力短板。
所谓能力短板,其实就是当前交付工具链体系中缺失的部分,尤其是高频操作,或者是涉及多人协作的部分,比如,需求管理、持续集成等。
如何选择工具?
选择工具的核心原则就是 选择主流工具
为什么商业工具也是可选项?
商业工具的优势一直都存在,比如,专业性、安全性、扩展性、技术支持力度等。其实,很多开源工具都有商业版本。
选择商业工具的理由有很多,不选的理由大多就是一个字:贵。针对这个问题,我要说的是,要分清一笔支出到底是成本,还是投资。
就跟购买黄金一样,虽然也花了钱,但这是一笔投资,未来可以保值和增值,甚至是变现。对于商业工具来说,也是同样的道理。如果一款商业工具可以大幅提升团队效率,最后的产出可能远超最开始的投资。如果我们组建一个团队,仿照商业工具,开发一套自研工具,重复造轮子的成本也可能一点不少。所以,重点就是要看怎么算这笔账。
经过了第一个阶段,企业交付链路上的工具基本都已经齐全了。团队对于工具的需求开始从够用到好用进行转变。另外,随着业务发展,团队扩大,差异化需求也成了摆在面前的问题。再加上,人和数据都越来越多,工具的重要性与日俱增。
那么,工具的稳定性、可靠性,以及大规模使用的性能问题,也开始凸显出来。对于这个阶段,我给你的建议是:使用半自建工具和定制商业工具,来解决自己的问题。
所谓半自建工具,大多数情况下,还是基于开源工具的二次开发,或者是对开源工具进行一次封装,在开源工具上面实现需要的业务逻辑和交互界面。
那么,半自建工具有哪些注意事项呢?虽然各个领域的工具职能千差万别,但从我的经验来看,主要有两点:设计时给扩展留出空间;实现时关注元数据治理。
到了第三个阶段,恭喜你已经在 DevOps 平台建设方面有了一定的积累,在各个垂直领域也积累了成功案例。那么,在这个阶段,我们要解决的主要问题有 3 点:
平台太多。做一件事情,需要各种切来切去;
平台太复杂。想要实现一个功能,需要对相关人员进行专业培训,他们才能做对;
平台价值说不清。比如,使用平台,能带来多大价值?能给团队和业务带来多大贡献?
对于这个阶段,我给你的建议是: 使用整合工具来化繁为简,统一界面,简化操作,有效度量。
整合工具,就是包含了开源工具、半自研工具、商业工具的集合。
你要提供的不再是一个工具,而是一整套的解决方案;不是解决一个问题,而是解决交付过程中方方面面的问题。
企业工具平台治理
如果最开始没有一个顶层规划,到了这个时候,企业内部大大小小的工具平台应该有很多。你需要做的第一步,就是 平台化治理工作。
第一条建议是比较温和可行的,那就是,找到 软件交付的主路径。用一个平台覆盖这条主路径,从而串联各个单点上的能力,让一些真正好的平台能够脱颖而出。而要做到这个事情,就需要持续交付流水线了。
打造自服务的工具平台
到了这个阶段,自服务就成了平台建设的核心理念。
所谓自服务,就是用户可以自行登录平台实现自己的操作,查看自己关心的数据,获取有效的信息。
而想要实现自服务,简化操作是必经之路。说白了,如果一件事情只要一键就能完成,这才是真正地实现了自服务。
这么说可能有点夸张。但是,打破职能间的壁垒,实现跨职能的赋能,依靠的就是平台的自 服务能力。很多时候,当你在埋怨“平台设计得这么简单,为啥还是有人不会用”的时候, 其实这只能说明一个问题,就是平台依然不够简单。
指导平台建设的核心理念
DevOps 产品设计体验的五个层次:战略存在层、能力圈层、资源结构层、角色框架层和感知层。
希望用户通过这个产品得到什么?显然,目标用户和痛点问题的不同,会从根本上导致两套 DevOps 产品之间相距甚远。
DevOps 产品的战略定位: 效率,质量,成本和安全。归根结底,产品的任何功能都是要为战略服务的.
明确目标用户,定义刚性需求,服务于典型场景,并最终在某一个点上突出重围,这就是我们在准备做 DevOps 产品的时候首先要想清楚的问题。
战略很好,但是不能当饭吃。为了实现战略目标,我们需要做点什么,这就是需要产品化的能力。所谓产品化,就是将一个战略或者想法通过产品分析、设计、实验并最终落地的过程。
明确哪些是自己产品的核心竞争力,而哪些是我们的边界和底线,现阶段是不会去触碰的。当我们用这样一个圈子把自己框起来的时候,至少在短期内,目标是可以聚焦的。
当然,随着产品的价值体现,资源会随之而扩充,这个时候,我们就可以调整、扩大自己的能力圈。但说到底,这些能力都是为了实现产品战略而存在的,这一点永远不要忘记。
所谓 主航道,就是产品的核心能力,直接反射了产品战略的具体落地方式。对于流水线产品来说,这个能力来源于对软件交付过程的覆盖,而不论你将来开发任何产品,这条主路径都是无法回避的。那么,产品就有了茁壮成长的环境和土壤。而 护城河就是你这个产品的不可替代性,或者是为了替代你的产品需要付出的高额代价。
资源这个事儿吧,就像刚才提到的,永远是稀缺的,但这对于所有人来说都是公平的。所以, 对资源的整合和调动能力就成了核心竞争力。
产品蕴含的资源除了这些看得见、摸得着的机器以外,还有很多方面,比如,硬实力方面的,像速度快、机器多、单一领域技术沉淀丰富,又比如,强制性的,像审批入口、安全规则,还有软性的用户习惯,数据积累等等。
对于内部 DevOps 产品来说,还有一项资源是至关重要的,那就是 领导支持。
要站在用户的角度来看待问题,要在他们当时的场景下,去解决他们的问题,而不是远远地观望着,甚至以上帝视角俯视全局。
不要让你的产品只有专业人士才会使用。
产品应该提供抽象能力屏蔽很多细节,而不是暴露很多细节,甚至,好的产品自身就是使用说明书。这一点,在注意力变得格外稀缺的现在,重要性不可忽视。
让不专业的人做专业的事情,结果可想而知,好多产品功能的设计都堪称是“反人类”的。
关于这个层次,我提供两点建议:
流水线是持续交付中最核心的实践,也是持续交付实践最直接的体现。
特性一:打造平台而非能力中心
与其他 DevOps 平台相比,流水线平台有一个非常典型的特征,那就是,它是唯一一个贯穿软件交付端到端完整流程的平台。正因为这样,流水线平台承载了整个软件交付过程方方面面的能力,比如,持续集成能力、自动化测试能力、部署发布能力,甚至是人工审批的能力等。
将持续交付流水线平台和垂直业务平台分开,并定义彼此的边界。
所谓的 垂直业务平台,就是指单一专业领域的能力平台,比如自动化测试平台、代码质量平台、运维发布平台等等,这些也是软件交付团队日常打交道最频繁的平台。
流水线平台只专注于流程编排、过程可视化,并提供底层可复用的基础能力。比如,像是运行资源池、用户权限管控、任务编排调度流程等等。
垂直业务平台则专注于专业能力的建设、一些核心业务的逻辑处理、局部环节的精细化数据管理等。垂直业务平台可以独立对外服务,也可以以插件的形式,将平台能力提供给流水线平台。
特性二:可编排和可视化
所谓的流程可编排能力,就是指用户可以自行定义软件交付过程的每一个步骤,以及各个步骤之间的先后执行顺序。说白了,就是“我的模块我做主,我需要增加哪些交付环节,我自己说了算”。
流程可编排,需要平台前端提供一个可视化的界面,来方便用户定义流水线过程。典型的方式就是,将流水线过程定义为几个阶段,每个阶段按顺序执行。在每个阶段,可以按需添加步骤,这些步骤可以并行执行,也可以串行执行。
特性三:流水线即代码
流水线代码化的好处不言而喻:借助版本控制系统的强大功能,流水线代码和业务代码一样纳入版本控制系统,可以简单追溯每次流水线的变更记录。
流水线即代码大大地简化了流水线的配置成本,和原子一样,是构成现代流水线的另外一个支柱。
特性四:流水线实例化
首先,流水线需要支持参数化执行。 通过输入不同的参数,控制流水线的运行结果,甚至是控制流水线的执行过程。
其次,流水线的每一次执行,都可以理解为是一个实例化的过程。
每个实例基于执行时间点的流水线配置,生成一个快照,这个快照不会因为流水线配置的变更而变更。如果想要重新触发这次任务,就需要根据当时的快照运行,从而实现回溯历史的需求。
最后,流水线需要支持并发执行能力。
这就是说,流水线可以触发多次,生成多个运行实例。这考察的不仅是流水线的调度能力、队列能力,还有持久化数据的管理能力。
特性五:有限支持原则
流水线的设计目标,应该是满足大多数、常见场景下的快速使用,并提供一定程度的定制化可扩展能力,而不是满足所有需求。
流水线设计要提供有限的可能性,而非穷举所有变量因素。
用户的差异化诉求,该如何满足呢?其实,这很简单,你可以在平台中提供一些通用类原子能力,比如,执行自定义脚本的能力、调用 http 接口的能力、用户自定义原子的能力,等等。只要能提供这些能力,就可以满足用户的差异化需求了。
特性六:流程可控
流水线可以为了满足不同阶段的业务目标而存在,并且每条流水线上实现的功能都不相同。为了达到这个目的,流水线需要支持多种触发方式,比如定时触发、手动触发、事件触发等。其中,事件触发就是实现持续集成的一个非常重要的能力。
除了多种触发方式以外,流水线还需要支持人工审批。这也就是说,每个阶段的流转可以是自动的,上一阶段完成后,就自动执行下一阶段;也可以是手动执行的,必须经过人为确认才能继续执行,这里的人为确认需要配合权限的管控。
特性七:动静分离配置化
动静分离就是一种配置化的实现方式。这就是指,将需要频繁调整或者用户自定义的内容,保存在一个静态的配置文件中。然后,系统加载时通过读取接口获取配置数据,并动态生成用户可见的交互界面。
特性八:快速接入
在建设流水线平台的时候,能否快速地实现外部平台能力的接入,就成了一个必须要解决的问题。
经典的解决方式就是提供一种插件机制,来实现平台能力的接入。
实际上,接入成本的高低,直接影响了平台能力的拓展,而流水线平台支持的能力多少,就是平台的核心竞争力。
首先,流水线平台需要定义一套标准的接入方式。以接口调用类型为例,接入平台需要提供一个任务调用接口、一个状态查询接口以及一个结果上报接口。
特性九:内建质量门禁
内建质量的两大原则:
毫无疑问,持续交付流水线是内建质量的最好阵地,而具体的展现形式就是质量门禁。通过在持续交付流水线的各个阶段注入质量检查能力,可以让内建质量真正落地。
在流水线平台上,要完成质量规则制定、门禁数据收集和检查,以及门禁结果报告的完整闭环。质量门禁大多数来源于垂直业务平台,比如,UI 自动化测试平台就可以提供自动化测试通过率等指标。只有将用于门禁的数据上报到流水线平台,才能够激活检查功能。
特性十:数据聚合采集
当平台的能力以原子的形式接入流水线之后,流水线需要有能力获取本次执行相关的结果数据,这也是在平台对接的时候,务必要求子系统实现数据上报接口的原因。至于上报数据的颗粒度,其实并没有一定之规,原则就是满足用户对最基本的结果数据的查看需求。
建设数据度量平台的核心价值,也就是让软件交付过程变得可视化。
在平台建设的时候,需要关注事前、事中和事后三个阶段的事情。
在项目启动会上,团队达成了两个非常关键的结论:一个是系统方案选型;另一个是建立协作机制。
首先,由于时间紧任务重,我们决定使用更易于协作的前后端分离的开发模式
技术框架方面,由于大家对前后端分离的模式达成了共识,我们就采用Python+Django+VUE 的方式来做。
在项目协作方面,我等会儿会专门提到,由于团队成员分散在北京、上海两地,彼此之间不够熟悉和信任,所以,建立固定的沟通机制就非常重要。
建立沟通机制
最后,项目毕竟还是有一些技术风险的,所以还需要启动预研。 预研项目的一些技术风险。
项目启动阶段要重点关注的几件事情:
首先,就是研发环境容器化。
其次,就是选择分支策略。虽然 DevOps 倡导的是主干开发,但是我们还是选择了“三分支”的策略,因为我们搭建了三套环境。
在工具层面,我们使用了 Jira。
在 Jira 里面,我们采用了精益看板加上迭代的方式,基本上两周一个迭代,保持开发交付的节奏。
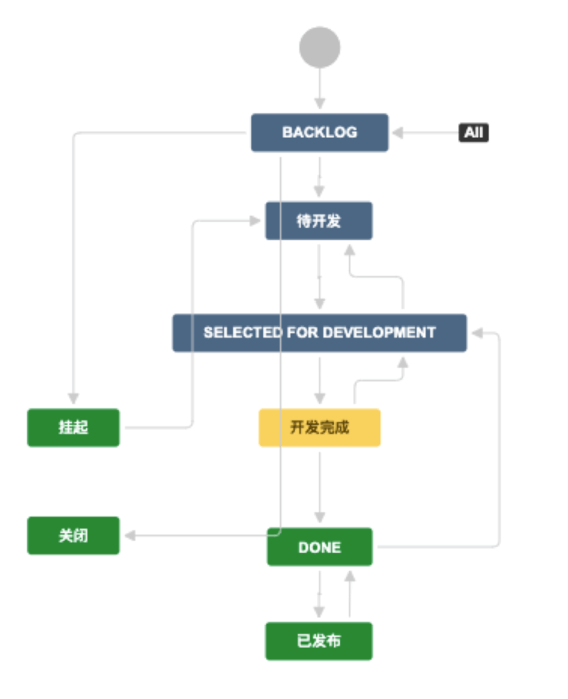
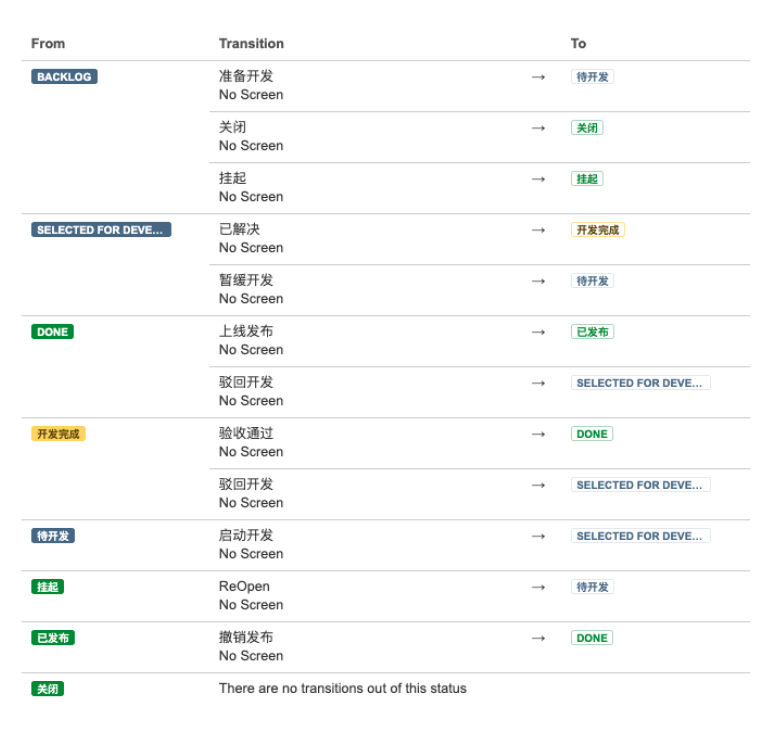
需求统一纳入 Backlog 管理,当迭代开始时,就拖入待开发状态,研发挑选任务启动开发,并进入开发中。当开发完成后,也就意味着功能已经在测试环境部署。这个时候,就可以等待功能验收。只有在验收通过之后,才会发布到预发布环境。并经过二次验收后,最终上线发布给用户。
开发流程
明确原则和规范
对于一个新组建的团队来说,规则是消除分歧和误解的最好手段,所以一定要让这些规则足够得清晰易懂。
“3-2-1”原则
3:创建任务三要素
2:处理任务两要素
1:解决任务一要素
当然,团队规则远不止这几条。你要打造自己团队内部的规则,并且反复地强调规则,帮助 大家养成习惯。这样一来,你会发现,研发效率提升和自组织团队都会慢慢成为现实。
除此之外,你也不要高估人的主动性,期望每个人都能自觉地按照规则执行。定期和及时的提醒就非常必要。比如,每天增加定时邮件通知,告诉大家有哪些需求需要验收,有哪些可以上线发布,尽量让每个人都明白应该去哪里获取最新的信息。
另外,每次开周会时,都要强调规则的执行情况,甚至每天的站会也要按需沟通。只有保持短促、高频的沟通,才能产生理想的效果。
团队不仅要做得好,还要善于运营和宣传,而这又是技术团队的一大软肋。
建立内部用户沟通群,在产品初期尽量选择一些活跃的种子用户来试用。那些特别感兴趣、愿意尝试新事物、不断给你提建议的都是超级用户。这些用户未来都是各个团队中的“星星之火”,在项目初期,你一定要识别出这些用户。
另外,每一次上线都发布一个 release notes,并通过邮件和内部沟通群的方式通知全员,一方面可以宣传新功能,另一方面,也是很重要的一方面,就是 保持存在感的刷新。
内部建立 OnCall 机制,每周团队成员轮值解决一线用户的问题,既可以保证问题的及时收敛,也能让远离用户的开发真真切切地听到用户的声音。
平台运营就跟打广告是一样的,越是在人流最大、关注度最高的地方打广告,效果也就越好。每个公司一般都有类似的首页,比如公司内部的技术首页、技术论坛、日常办公的 OA系统等等,这些地方其实都会有宣传的渠道和入口。你要做的就是找到这个入口,并联系上负责这个渠道的人员。
另一个方法有些取巧,但对于技术团队来说,也非常适用,那就是通过技术分享的渠道来宣传产品。
无论什么样的工具、流程、目标,最终都是依靠人来完成的。如果忽略对人的关注,就等同于本末倒置,不是一个成熟的团队管理者应该做的事情。
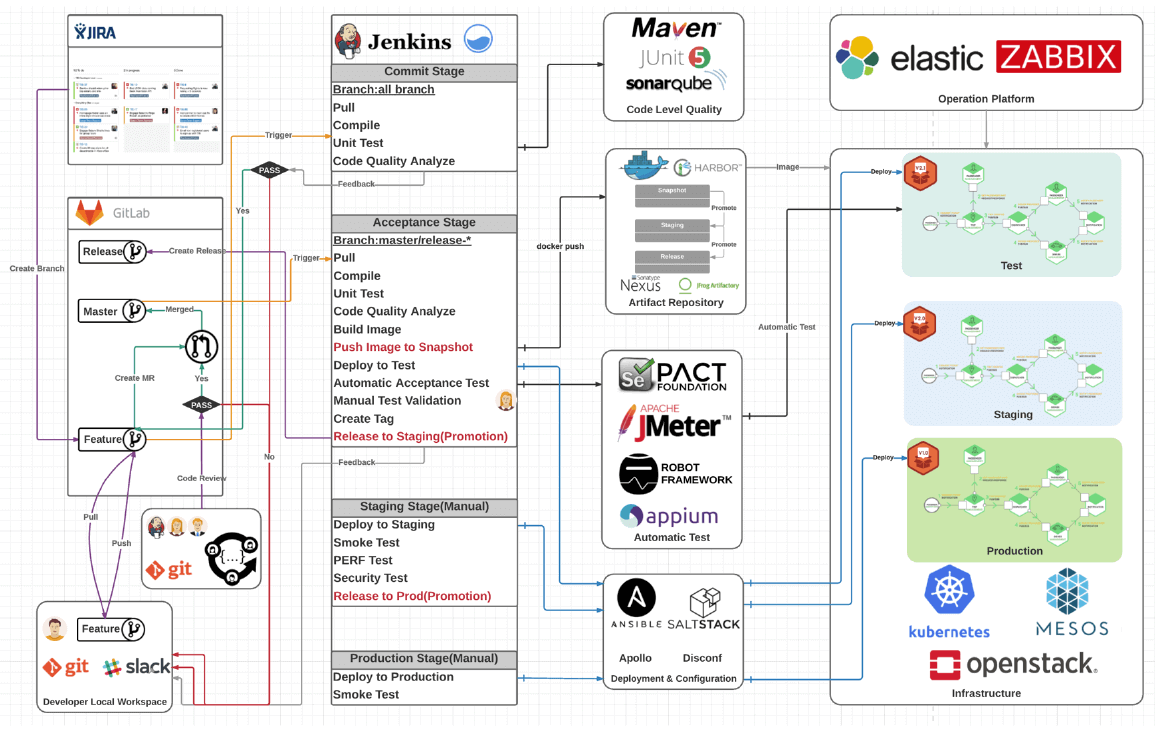
需求管理 - Jira
代码管理 - GitLab
代码质量 - SonarQube
环境管理 - Kubernetes

除了基础的岗位职责外,还需额外关注 3 个方面
DevOps 工程师的核心能力模型:
其中,能力模型分为两个方面:专业能力和通用能力。
专业能力也就是常说的硬实力,是IT 从业人员身上的特有能力,比如软件工程师会写代码,就跟导演会拍电影,司机会开车一样。而通用能力,更加接近于软实力,这些能力并不局限于某一个岗位或者职业,是所有人都应该努力培养的能力。很多时候,当硬实力到达天花板之后,软实力的差异将决定一个人未来的高度,这一点非常重要。
软实力
硬实力
基于过往在公司内部推行 DevOps 的经验,以及当前行业的发展趋势,我有几条建议送给你:
培养跨职能领域核心能力
报告
《DevOps 状态报告》
关注点:1.看趋势, 2.看模型,3看实践
https://pan.baidu.com/s/1W7-_et-wulD7AueBU2KTow 提取码:mgl1
书籍
电子读物可以去 微信读书 APP中搜索
关于DevOps 工程实践
《持续交付》&《持续交付 2.0》
关于管理实践和精益方面
《精益创业》&《 Scrum 精髓》&《精益产品开发》&《精益开发与看板方法》
关于DevOps 的全貌以及核心理论体系和实践
《DevOps 实践指南》&《Accelerate:加速》
小说
《凤凰项目》&《人月神话》&《目标》
大会,网站和博客
本文是对 极客时间 的 « DevOps实战笔记 » 的总结。