田超 Apache SeaTunnel(Incubating) PPMC&Committer
今天我来分享从 0 到 1 快速入门 Apache SeaTunnel(Incubating),主要从以下6个方面进行,首先第一个方面是对数据集成做一个简单的概括,第二个是对 SeaTunnel 做简单的介绍,第三是介绍 SeaTunnel 当前的原理和架构演进,第四个方面是对当前市面上一些比较常见的数据集成工具进行对比,来解读一下现在市面上已经有了那么多数据集成工具,为什么我们还要再去“造轮子”,第五个方面是通过案例demo来展示一下SeaTunnel强大的能力,第六是介绍 SeaTunnel 的 Roadmap,包括我们目前正在做的一些事情,以及未来想要做的一些事情。
1
数据集成概览
在对数据集成做概论之前,首先我们要提出一个问题,
什么是数据集成? 从字面意义上来讲,数据集成就是把不同来源格式以及特点性质的数据在逻辑上或者物理上有机地进行集中,从而为企业提供全面的数据共享。企业可以通过高度集中的数据快速做出一系列的分析和决策,从而实现数据利用的价值。
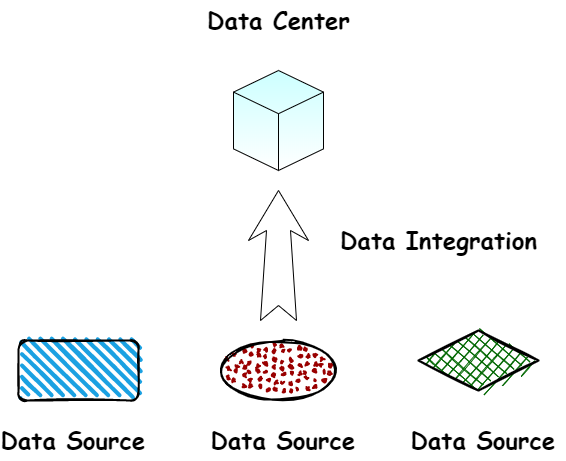
实际上,一家公司每个业务部门负责的业务线是不一样的,每个业务部门每天都在产生数据,如果把这些数据做有效的集中和处理,那么企业可以通过这些数据获得更多的业务价值。再抛出第二个问题,
我们为什么要去做数据集成? 在企业中,由于开发时间或开发部门的不同,往往有多个异构的、运行在不同的软硬件平台上的信息系统同时运行,这些系统的数据源彼此独立、相互封闭,使得数据难以在系统之间交流、共享和融合,从而形成了“信息孤岛“,数据集成可以有效合并和融合异构数据源,打破”信息孤岛”。
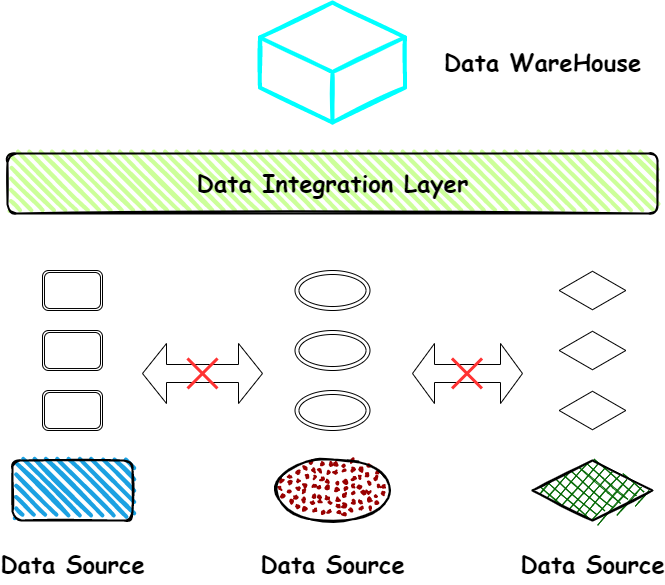
以银行为例,银行可能有营销业务,同时还有信贷的业务,如果信贷业务想要去拿到营销业务那边的数据,是做不到的,因为可能不同的业务部门用的是不同的技术栈,有的数据是存在一些数据仓库里,比如 Greenplum 或 Oracle,有的数据存在 Hadoop 集群中,那么不同的数据库之前的数据如何进行共享?此时我们就需要数据集成层来做这个事情,我们去做一个中间层去把这些数据进行归一化和统一处理,并导入到对应的数据仓库当中。这样我们每一个的业务部门都会拿到其他部门的数据,更好的实现数据价值。下面我们聊一下数据集成中的几个核心概念,也就是我们常说的 ETL ETL 中的 E 是extract,数据抽取;T 是 Transform,代表数据的转换;L 代表Load,数据加载。
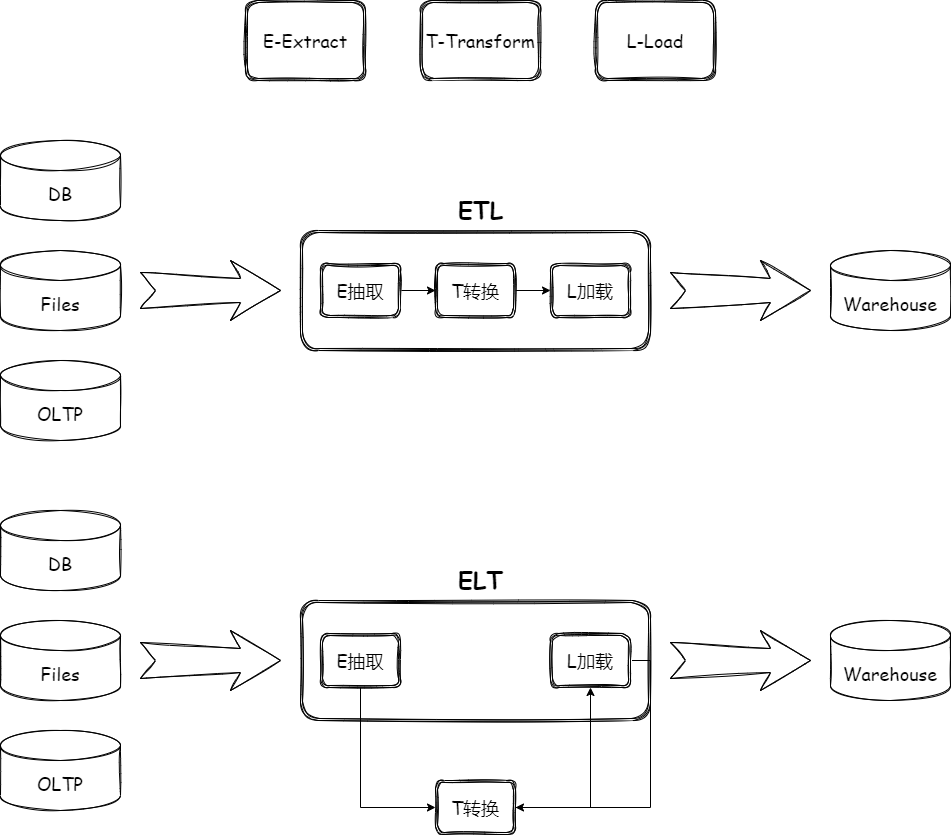
ETL 代表了整个数据集成中最重要的三个步骤,在之前老的数据集成架构中,更多的是 ETL 架构,以 Flink 和Spark 分布式计算引擎为例,它们拥有非常强大的计算能力,同时还会在转换方面有很多方便易用的算子做一些数据的清洗和转换。实际上整个的数据处理流程是将数据抽出来,然后在计算引擎端,也就是说在数据集成层去做数据转换,再把转换好的数据加载到目标 Sink 端。这样做的弊端是什么?那就是当数据抽取量大时,所有的数据计算压力全都放在了数据集成层,会给数据集成层造成巨大的负担,因此我们需要更多的计算资源,而且计算过程中的容错也比较困难。基于这些痛点,以及随着技术发展,Source 和 Sink 端数据库对应的算力提升,使用他们自带的计算能力对数据进行提前转换,效率会提高,渐渐地,数据集成的架构就从 ETL 变成了 ELT,把 T转换这部分的数据操作上推或者下移到对应的 Source 端或者 Sink 端。这样做的好处,一是避免 Source 端和 Sink 端资源浪费,而且可以利用他们对自己保存的数据的优化,提升数据转换的效率。第二点,减轻数据集成中间层的压力,因为当数据抽出来之后,我们不需要再对数据进行转换,这样就会避免内存的损耗,直接把抽出来的数据 加载到对应的目标端,会让数据集成更加纯粹,效率也会更高。
2
Apache SeaTunnel简介
再来看一下 SeaTunnel 究竟是做什么的。SeaTunnel 是一个非常易用的支持海量数据同步的超高性能分布式数据集成平台,由国人主导并捐赠给Apache基金会;SeaTunnel取名灵感来自于小说三体中无坚不摧的水滴,摧毁了人类的好几千艘战舰。
Apache SeaTunnel 特性
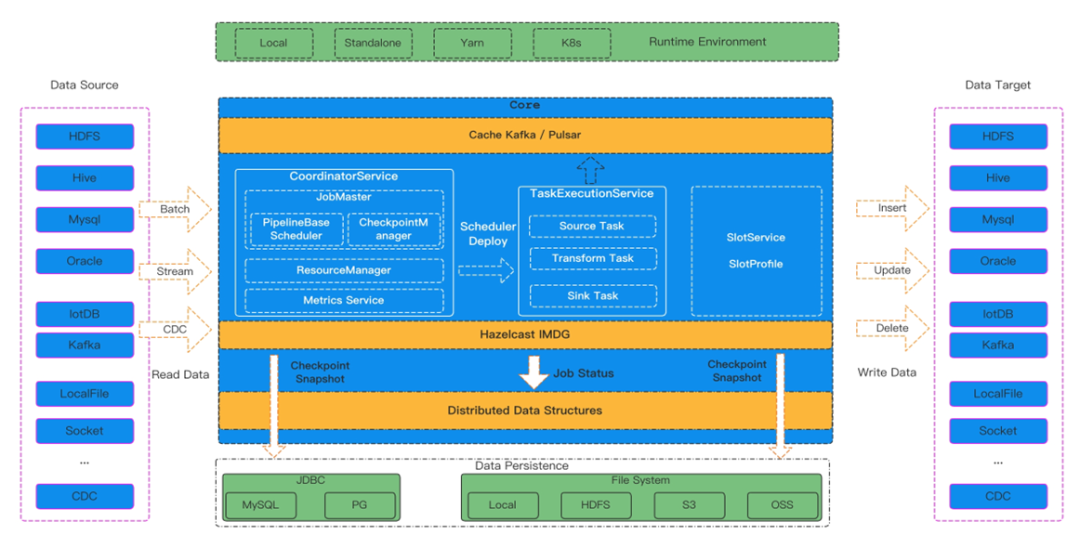
首先,SeaTunnel 最大的一个特点是简单易用,无需开发,用户可以通过学习配置文件,快速开发当前的数据任务。第二个是在架构上做了批流一体的架构升级,现在我们既可以管理流作业,也可以管理批作业。第三,实现了异构多数据源支持,从架构图中可以看到,SeaTunnel 可以支持 HDFS、Hive 、JDBC等类型的数据源,还有 Kafka、Plusar 等流式数据源,CDC 等。同时,SeaTunnel 还支持多个计算引擎无缝接入,目前支持Spark2.4.X+、Flink1.13.X 版本的计算引擎,高版本的计算引擎支持在社区的发展 Roadmap 中,也期待更多有志之士加入到贡献中,让 SeaTunnel 变得更好。另外,SeaTunnel 是模块化和插件化的设计,整个框架是通过 SPI 的方式,动态加载插件到框架中,如果企业有自定义需求,可以利用预留好的接口来快速实现符合自己业务需求的插件。值得注意的是,SeaTunnel 目前已经发布了自研的计算引擎,这款计算引擎主要是针对缺乏一定大数据资源的用户,因为老架构 SeaTunnel 只能依靠 Spark 或者Flink 计算引擎才能跑起来。但目前 SeaTunnel 已经完全和计算引擎进行解构,并且自带计算引擎,极大地降低了 部署成本,提高了易用度。最后,SeaTunnel 最大的特点就是目前已经无缝接入到 CDC,可以支持 CDC 同步。
3
原理和架构演进
接下来讲一讲 SeaTunnel 的内核原理和底层架构演进。
3.1
核心理念
SeaTunnel 设计的核心是利用设计模式中的“控制翻转”或者叫“依赖注入”,主要概括为以下两点:
- 上层不依赖底层,两者都依赖抽象;
- 流程代码与业务逻辑应该分离。整个数据处理过程,大致可以分为以下几个流程:输入 -> 转换 -> 输出,对于更复杂的数据处理,实质上也是这几种行为的组合:

这三个名词是不是很熟悉?它其实就代表了我们刚才讲的数据集成里面核心的几个概念,ETL 就是基于这些高度抽象的行为,再丰富自己的插件,自定义业务处理流程。那么我们在丰富了这些数据处理流程之后,就可以去通过这三种行为去组合出不同的有向无环图来丰富整个数据处理的流程。
3.2
内核原理
接下来讲一讲 SeaTunnel 的内核原理,实际上 SeaTunnel 将数据处理的各种行为抽象成 Plugin,并使用 Java SPI 技术进行动态注册,设计思路保证了框架的灵活扩展,在以上理论基础上,数据的转换与处理还需要做统一的抽象,譬如比较有名异构数据源同步工具 DataX,也同样对数据单条记录做了统一抽象。在 SeaTunnel 架构体系中,由于背靠 Spark 和 Flink 两大分布式计算框架,框架已经为我们做好了数据源抽象的工作,Flink 的 DataStream、Spark 的 DataFrame 已经是对接入数据源的高度抽象,在此基础上我们只需要在插件中处理这些数据抽象即可,同时借助于 Flink 和 Spark 提供的 SQL 接口,还可以将每一次处理完的数据注册成表,方便用 SQL 进行处理,减少代码的开发量;在最新 SeaTunnel 的架构中,SeaTunnel 做了自己的类型抽象,实现了与引擎解耦的目的。
3.3
架构演进
再看 SeaTunnel 架构演进的过程,我们现在目前在做的一个事情就是从 v1 到 v2的架构改造和升级。
对于 V1 版本来讲,SeaTunnel 本质上是一个 ETL平台。而 V2 版本则向 ELT 的路线发展。基于整个架构和设计哲学的讨论,我们可以在https://github.com/apache/incubator-seatunnel/issues/1608 看到,如果有兴趣,可以去了解一下 SeaTunnel 架构演进的前世今生。
V1 架构
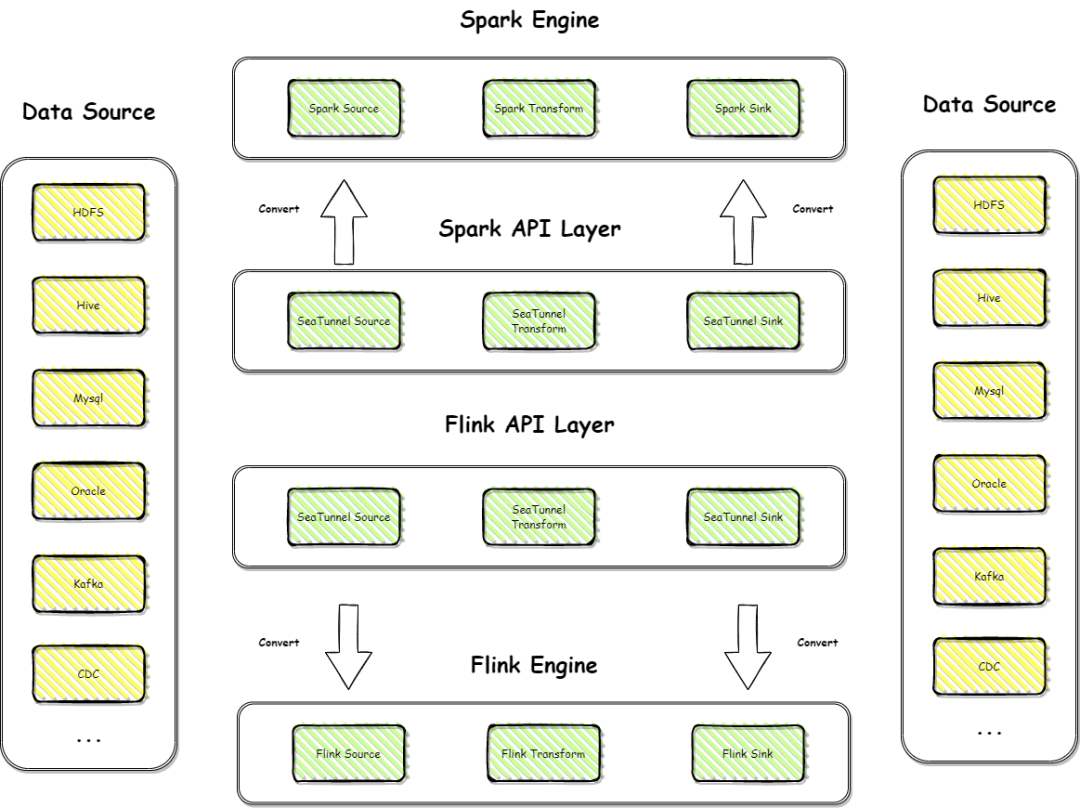
V1 架构中,SeaTunnel 的连接器和异构数据都是强依赖分布式计算引擎的,对于不同的计算引擎,会有不同的一个 API 层,连接器也都依赖着 Spark 和 Flink,已经开发好的连接器本质上也都是 Spark connector 和 Flink connecter。接入数据之后,再去对接入进来的数据进行转换,然后再进行写出。这套设计哲学虽然代码开发量很少,而且很多细节都不需要考虑,因为现在开源的 Spark、Flink的 connecotor 都已经给我们解决了大多数的问题,但实际上这也是一种弊端。第一,强依赖计算引擎,我们无法做到解耦,而且每当计算引擎做大版本升级的时候,就需要进行大量的底层改造,难度比较大。
V2架构
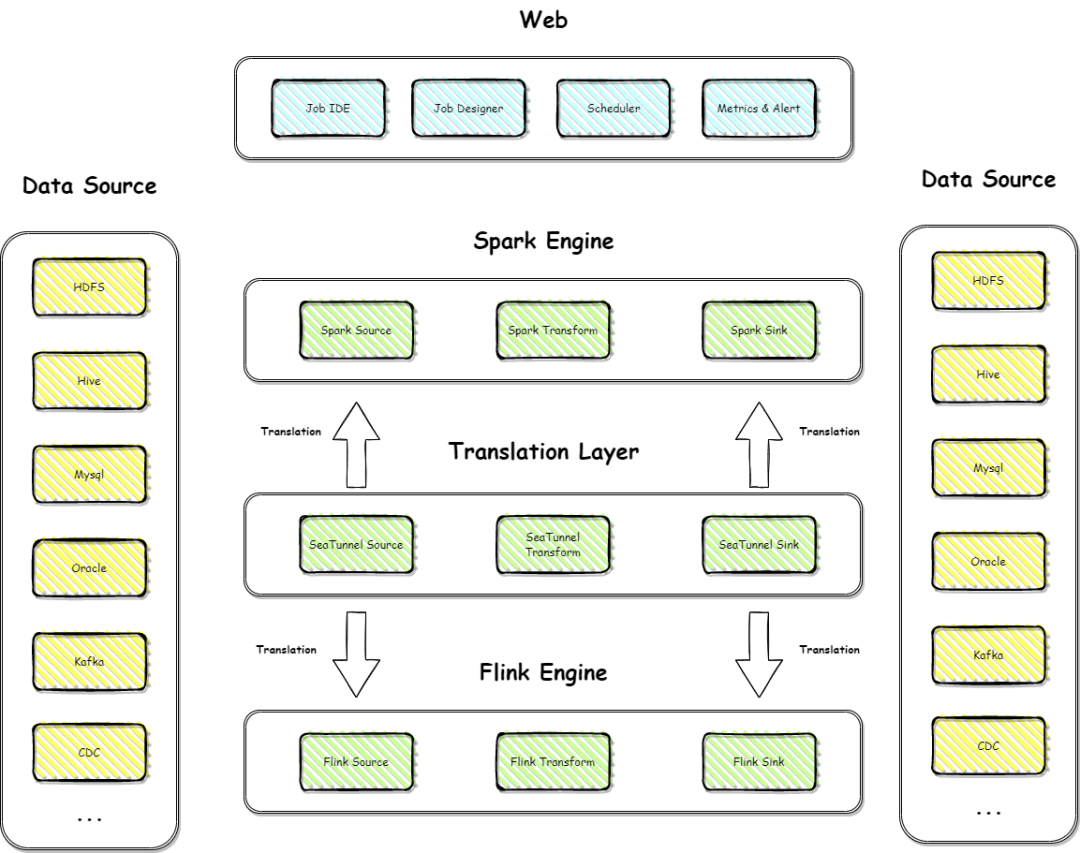
基于这些痛点,我们对 V 2 版本进行了重构。首先,V2 版本有了自己的一套API,也是有了自己的一套数据类型,就可以去开发自己的连接器,而不依赖任何引擎,接入的每一条数据都是 SeaTunnelRow,通过翻译层,把 SeaTunnelRow push 到对应的计算引擎里。从底层来讲,我们实现是统一的,为适配不同的引擎版本,只需要开发不同的翻译层即可。即使引擎进行了大规模的 API 升级改造,也只需要再新建翻译层就好了,老版本丝毫不影响,这也是 V2 版本最大的亮点。除了这点之外,我们还正在 V2 架构上做对应的 web 服务化工作,有一些设想,首先会有 job IDE,也就是说会有一个 job 编辑的页面,会有智能提示、数据源管理等一系列高级功能。第二,是会有 job designer 高级设计版本功能,可以通过不同的数据源参数替换,或者根据不同的需求来去实现,由一个 template 生成多个作业。同时,我们还在规划自己的 scheduler。社区目前已经实现了 Apache DolphinScheduler 的接入,这个版本在不久的将来就会和大家见面。最后一块也是我们整个服务化阶段比较重要的一环,就是要做自己的 Alert,以及对应的 Matrix 系统,去做好作业报警,作业指标的收集和推送,完整地管理作业流程。最后做一下总结,进行 V1 和 V2 架构的升级对比,到底我们做了哪些事情。
首先在引擎依赖方面,V1 强依赖 Spark 和 Flink,V2 无依赖,且自带计算引擎,直接去部署就可以用了。第二,在连接器实现方面,V1 针对不同的引擎可能要实现多次,V2 我们用自己的API 就只需实现一遍。第三,V1 引擎版本升级比较困难,因为底层 API 是与引擎高度耦合的,V2 引擎版本升级比较容易,因为我们已经和引擎进行解耦,针对不同版本开发不同的翻译层即可。连接器参数统一方面,V1 针对不同引擎会有不同的参数,这也是 V1 被吐槽的一个点, V2 解决了这个痛点,所有的参数和特性都是统一的,减少用户的使用和学习成本。最后,自定义分片逻辑上,在 V1 架构下,因为是强依赖 Spark 和 Flink 的connector,底层都已经实现好了一些分片逻辑,数据抽取效率不高,而且分片逻辑也改不了,除非改 Spark 的源码,再重新编译。对于这个痛点, V2 可以自定义分片逻辑,我们可以自由地发挥自己的想象力,数据抽取效率也是可控的,我们可以根据不同的业务需求进行修改。
3.4
V2架构新特性
架构升级之后,V2 架构有了一些新特性。
- 多版本、多引擎支持
- 支持多个版本的Flink引擎,完美支持Flink的Checkpoint流程
- 支持Spark微批处理模式,支持聚合提交特性
- 自研引擎 SeaTunnel Engine,专为数据同步场景设计的引擎,SeaTunnel 内部自带引擎,为那些没有大数据生态的企业或追求数据同步最佳体验的用户提供可选方案
基于这些特性之下,SeaTunnel 实现了三点,首先SeaTunnel 支持Source/Transform/Sink 的并行化处理,提高吞吐性能。第二,支持分布式快照算法,两阶段提交、幂等写入,实现从 Source 到 Sink 端的 exactly once 精确一次性语义,而且还能保证不丢数据,断点续传等高级功能。第三,基于引擎提供的实时处理或微批处理实现低延迟。
3.5
SeaTunnel Engine性能测试
我们还与 DataX 进行了一个性能测试对比 ,在相同的千万级别作业量下,我们对比了不同并发、堆内存下的表现,结果显示 SeaTunnel Engine 的用时明显小于 DataX,尤其在 200 兆小内存的情况下,SeaTunnel Engine表现非常好,性能比DataX 提升了30~40%。
4
数据集成工具对比
下面对我们常见的一些数据集成工具进行对比,也是回答一下大家的疑问,就是我们为什么要去重新造轮子。对比的工具有大家耳熟能详的 DataX,袋鼠云的Chunjun,可能对于Chunjun大家比较陌生,实际上它没改名之前叫 FlinkX,以及最近刚进入 Apache 孵化器的 StreamPark(原名 StreamX)。
首先从定位上来讲,Apache SeaTunnel 的定位是一个数据集成平台,而不只是简单的工具,后续会提供很多平台服务化完善作业流程和作业生命周期。而 DataX 和 Chunjun 目前还只是工具,没有提供服务化的东西。这三者都是以 ELT 为核心的数据同步工具或平台。StreamPark的定位是一个 ETL 作业管理开发平台,主要分为两部分,一部分是对Flink 作业的管理,第二部分是提供一些快速的开发的 SDK 来减轻开发者的开发压力。用 StreamPark 提供的 SDK,你就可以快速去做 Flink 作业或者 Spark作业,来减少代码的开发量,从定位上来讲这是不一样的。第二,从引擎依赖上讲,SeaTunnel 已经对引擎进行解耦,我们可以选用自己的引擎,包括 Spark 引擎或者 Flink 引擎。但对于DataX来讲,它也是没有引擎依赖的,因为DataX是纯 Java 开发的,也就是你把它安装包一下,然后部署好就可以跑了,前提是有 Java 环境。Chunjun 是强依赖Flink 的,它需要基于 Flink 的组件进行二次开发和Connector优化。StreamPark 的定位是开发管理平台,对引擎也是有依赖的。从引擎版本支持来看,SeaTunnel 目前仅支持 Spark 2.2.X – 2.4.X,Spark 3 正在支持中,Flink 目前支持 1.10.X – Flink 1.13.X,高版本支持也在测试稳定性中,因为 Flink 高版本的 API 升级相应改造比较麻烦。DataX 因为没有引擎依赖,是纯 Java 版本的,所以对引擎版本没有要求。Chunjun 目前支持 Flink1.8.X – Flink1.12.X,高版本支持较差,升级改造正在进行中。StreamPark 在这块做得很好,支持管理Flink 1.16作业,对 Spark的作业管理也在开发中。从部署难度维度来看,SeaTunnel、DataX 和 Chunjun 三者部署都比较容易,因为不涉及后端和前端的部署,或数据库的需求,本质上它们就是一个工具,把安装包下载好了之后,有了 Java 环境,把环境变量配好,就可以去运行了。对于 StreamPark ,因为是一个前后端的项目,所以在部署上有一定难度,需要一定的运维成本。在精确一次性语义方面,因为 SeaTunnel 在 V2 架构完美支持了 Flink 的 checkpoint流程,同时在ST Engine中也支持了更细粒度的checkpoint,所以部分连接器支持一次性语义,而 DataX 不支持。Chunjun 因为也是依赖于Flink 的 checkpoint,所以也是支持一次性语义的。StreamPark 本身就是一个 ETL 作业的开发管理平台,可以保证作业的正常状态,并不支持数据同步或数据处理。经过多方面的一个维度对比,我们看到了每个工具的优缺点,也回答了大多数人提到提出来一个问题,就是我们为什么要再去做 SeaTunnel,因为目前现在的一些工具是无法满足所有的需求的,所以我们取长补短,去做出一款更好的工具。Data X 这个工具是 2017 年开源的,历经 5 年时间还是比较火,算是开创了数据集成新思想和新潮流。随着大数据技术不断推进发展的形势之下,我希望我们的技术也是向前去推进的,所以我们才会去做这样的一个平台去回馈大家。
5
SeaTunnel功能演示
接下来是对 SeaTunnel 做一个简单的功能演示。
视频 32:36s-41:16s
6
SeaTunnel Roadmap
最后看一下 SeaTunnel 的发展路线图,包括当前在做的一些工作和未来的计划。
6.1
当前工作
Connectors的接入与优化
当前在做的第一个大块是 Connectors 的接入和优化。目前虽然已经有 80 多种连接器,但是性能和具体代码和逻辑还有优化的空间,所以会着重优化 Connectors,增加更多配置参数,更细力度地来控制作业流程。
SeaTunnel-Web 服务化开发
第二个大块是我们现在正在做的 SeaTunnel-Web 服务化开发,这个工具已经初具雏形,但是现在还不能实现一键部署,我们的目标是让它开箱即用,可以拖拉拽点点就可以实现数据集成、数据迁移、数据同步、数据监控等一系列数据集成工作。
SeaTunnel Engine 优化
第三,SeaTunnel Engine 已经发布了第一个 MVP 版本,支持集群和单机模式。目前在性能上我们已经取得了一些小成绩,比 DataX 的性能高出 30~40%,但相信这不是我们的瓶颈,后续还可以在数据传输和整个流程方面去做更多优化,提高性能。
6.2
继续推进
- 完善指标监控系统
目前,SeaTunnel 在这块比较缺失,我们无法获取当前作业流程的进度,后续会加重去完善这一块。如果大家有好的想法,或者有做相关工作的经验,欢迎加入我们,一起共建指标监控系统。
- 脏数据收集,流速控制
目前很多连接器在做在一些数据类型转换或是数据写入报错的时候,直接整个作业就停止了,但本来不应该停止的,这是因为在整个在数据接入过程当中,各种各样的数据进入,但数据清洗没有达到预期的目标。这部分脏数据的收集应该由系统处理,及时给出提醒。另外是要进行流速控制,因为现在很多客户的机器可能在云上,云上会有带宽限制,目前 SeaTunnel 工作时带宽会占满,我们后续会加入流控这个功能。
- 自动建表,监控 schema 变更
自动建表也是很多用户的痛点,比如出仓的表有五六十个字段,去写这五六十个字段的建表 SQL 非常累人。我们计划支持自动建表,在 Sink 端自动建表,这也是一个开关,如果用户想要自动建表,就打开它,不想就关闭。监控 scheme 变更是针对 CDC 场景,当前, Schema 如果发生改变,后续的同步行为要接收到通知,而且还要做一些变更。
- 支持 Spark3,支持 Flink1.14+
积极推进计算引擎高版本的支持,支持 Spark3 和 Flink1.14+。虽然计算引擎已经与 Spark 和 Flink 解耦了,但实际上还是要站在巨人的肩膀,站在技术前沿,让数据集成变得更加流畅。最后,我们的愿景是做一个国产的世界一流的数据集成平台,大家如果有关于数据集成或 SeaTunnel 设计理论或功能需求需要和我探讨的,欢迎和我们交流。
SeaTunnel
Apache SeaTunnel(Incubating)是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台。
59篇原创内容
公众号
Apache SeaTunnel

Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台
仓库地址: https://github.com/apache/incubator-seatunnel
网址:https://seatunnel.apache.org/
Proposal:https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelPro
Apache SeaTunnel(Incubating) 下载地址:https://seatunnel.apache.org/download 衷心欢迎更多人加入!
我们相信,在
「Community Over Code」(社区大于代码)、
「Open and Cooperation」(开放协作)、
「Meritocracy」(精英管理)、以及「
多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
提交问题和建议:https://github.com/apache/incubator-seatunnel/issues
贡献代码:https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 : [email protected] 开发邮件列表:[email protected] 加入 Slack:https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1cmonqu2q-ljomD6bY1PQ~oOzfbxxXWQ
关注 Twitter: https://twitter.com/ASFSeaTunnel