ChatGPT背后人工智能算法
- - 今日话题 - 雪球ChatGPT背后人工智能算法,关键的原创技术,其实全部都是国外公司发明的. 这里做一点简单的科普,人工智能原创性研究,中国还有很大进步空间,ChatGPT也不是普通的公司能够复刻的出来的. 深度残差网络(ResNet)由微软(亚洲)研究院发明. 在此之前,研究员们发现深度神经网络的效果要比浅层神经网络要好得多,这也就是所谓的深度学习.
ChatGPT背后人工智能算法,关键的原创技术,其实全部都是国外公司发明的。这里做一点简单的科普,人工智能原创性研究,中国还有很大进步空间,ChatGPT也不是普通的公司能够复刻的出来的。所以,大A的炒作,洗洗睡吧。

深度残差网络(ResNet)由微软(亚洲)研究院发明。在此之前,研究员们发现深度神经网络的效果要比浅层神经网络要好得多,这也就是所谓的深度学习。
但是,一旦神经网络过于深,那么网络学习、训练的过程就会爆炸,也就是人工智能学不出来了,这很奇怪,理论上网络越深越好。
为了解决这个问题,在普通的神经网络的基础上,ResNet提出了残差连接,也就是把浅层部分的表征直接加和到深层,防止深度网络出现退化。因为浅层的直接连接,所以保证了网络至少能够有浅层的水平,后面的深层部分摆烂也不要紧。
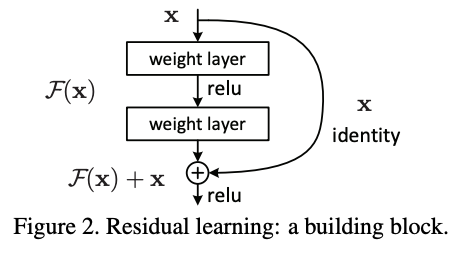
这篇论文的影响是深刻的,是顶级会议“计算机视觉与模式识别”(CVPR)的最佳论文,之后这个残差网络的技术渗透到了所有的神经网络结构,包括AlphaGo和ChatGPT,成为了深度学习的基础。甚至可以说,这篇论文奠定了2015年之后深度学习的黄金发展期。

Transformer由谷歌提出,其原理是提出了自注意力机制(Attention),具体比较复杂,我就不展开了。
这篇文章直接改变了深度学习模型的设计理念。在此之前,图像数据,例如人脸识别,一般适用卷积神经网络(CNN),例如上述提到的ResNet就是嵌入到CNN中做图像识别和目标检测。然后文本数据、自然语言数据,一般采用循环神经网络(RNN)处理。
但是,Transformer在图像上战胜了CNN,在文本上战胜了RNN,成为大一统模型!甚至,我们现在做AI+创新药,也用Transformer建模药物分子,其他的模型结构几乎全部被淘汰了!
Transformer除了大一统,多才多艺处理所有类型的数据之外,还把深度学习向着大模型方向引导,ChatGPT便是大模型,我们马上会介绍。

BERT还是由谷歌提出,预训练深层的双向Transformer。
首先,预训练旨在用大量的数据训练一个模型,这就要求这个模型“脑容量”足够大,所以需要用到深层的双向Transformer。上古时期的CNN、RNN没有这么强大的学习能力。
其次,预训练是怎么做的呢?其实很简单:
(1)比如有一段文字,我随机的去掉一些单词,然后让模型复原出来这些被去掉的单词。
(2)我手里有一段故事,其中有很多句子。我把这些句子随机打乱,拿出两句句子A和B,问你:A是不是B的下一句句子?也就是上下文预测。
注意,这样的预训练不需要去标注数据,只需要输入大量的语料库即可。这就加速了数据的收集。
其次,很重要的一点是这样的模型预训练完成之后,能够去做其他的自然语言任务。只需要在下游其他任务的小数据上面进行微调即可,实现了一个模型打天下。在以前,不同的自然语言任务都需要不同的算法去处理,但是BERT经过微调之后可以处理所有任务。

ChatGPT的基础便是OpenAI提出的GPT,他做的事情和BERT差不多,也就是预训练,只是预训练的方式不一样。
GPT全名叫做Generative Pre-trained Transformer,用生成式方法预训练的Transformer,知道我为什么要大篇幅介绍Transformer和预训练了吧?
GPT-3有1750亿参数,45TB的训练数据(1TB=1000GB),烧了1200万美元的费用进行训练。训练所使用的设备包括285000 个CPU和10000 个GPU。这个模型的护城河有两点:(1)训练数据的收集,(2)训练和维护所产生的费用。
AIGC中的图像生成是怎么火起来的呢?是一个叫做扩散模型(Diffusion Model)的生成模型。
首先,生成模型已经有10多年的研究历史了,比较知名的有:
(1)生成对抗网络(GAN),加拿大蒙特利尔大学研究者于2014年提出。

(2)变分自编码器(VAE),2013年被荷兰阿姆斯特丹大学的研究者提出。

(3)归一化流(Normalizing Flow),谷歌于2015年提出。

但是上述的三个模型在生成高清图像上效果均不理想,所以没有商用化的潜力。
但是,扩散模型改变了这一切。扩散模型可以追溯到2015年,被美国斯坦福大学和加州大学伯克利分校的研究者提出:

后来在2022年被发扬光大。Stable Diffusion(稳定扩散模型)的开源,加速了其应用,所谓的开源就是把代码公开,这样所有人都能使用。且Stable Diffusion是海外机构——一个德国慕尼黑的大学Ludwig Maximilian University of Munich开源的。
注意到,Diffusion是没有商业护城河的,因为算法是公开的,所有人都能使用,且训练快速,稍微有几张显卡就能使用,门槛很低。
(1)ChatGPT模型的护城河在于训练数据收集和烧钱的计算过程,因此,除了百度这种在人工智能领域有一定积累的大公司,既有数据的积累,也有研究上的积累,其他公司洗洗睡吧。
(2)从上可以发现,所有原创性、颠覆性的研究均由海外单位提出,值得深思。
$百度(BIDU)$ $中概互联网指数ETF-KraneShares(KWEB)$ $纳斯达克综合指数(.IXIC)$ #ChatGPT继续发酵,软件概念集体狂飙#