Apache NiFi简介
Apache NiFi 是一个强大的数据流管理和自动化工具,旨在简化数据的采集、传输、处理和分发。它特别适合于构建和管理复杂的数据流管道,支持从各种数据源到不同目标系统的数据传输。
Apache NiFi主要功能
Apache NiFi 是一个用于自动化数据流的强大工具,具有广泛的功能集,旨在支持从各种数据源到不同目标的复杂数据流管道。以下是 Apache NiFi 的主要功能:
- 数据采集与传输:
- 支持从多种数据源采集数据,包括文件系统、数据库、HTTP 服务、消息队列(如 Kafka)、传感器设备等。
- 支持将数据传输到多种目标系统,如 HDFS、数据库、云存储服务、REST API 等。
- 数据流可视化:
- 提供直观的 Web 用户界面,用户可以通过拖拽和配置处理器来设计和管理数据流。
- 实时显示数据流的状态和性能指标,便于监控和调试。
- 数据处理与转换:
- 提供丰富的内置处理器,支持数据的解析、转换、清洗、聚合和格式化等操作。
- 支持复杂的数据处理逻辑,如条件路由、数据分片、合并和拆分。
- 动态路由与优先级控制:
- 支持根据数据内容或属性动态路由数据到不同的处理器或目标。
- 允许为数据流设置优先级,以控制数据处理的顺序和速度。
- 实时流处理:
- 支持实时数据流处理,能够在数据到达时立即执行处理操作。
- 事件驱动架构,处理器在接收到数据或触发条件时自动执行。
- 分布式架构与扩展性:
- 支持多节点集群部署,可以水平扩展以处理大规模数据流。
- 集群中的节点通过 Apache ZooKeeper 进行协调和管理。
- 数据安全与合规:
- 支持数据加密、访问控制和用户身份验证,确保数据的安全性。
- 提供数据审计功能,记录数据流的处理历史和用户操作。
- 错误处理与重试机制:
- 自动处理数据传输和处理过程中出现的错误,支持重试和故障转移。
- 提供数据回退和恢复功能,确保数据的可靠性和完整性。
- 可扩展性与集成性:
- 支持自定义处理器和控制器服务的开发,用户可以根据需要扩展 NiFi 的功能。
- 与其他大数据工具和框架(如 Apache Kafka、Hadoop、Spark)紧密集成,支持复杂的数据处理和分析工作流。
- 监控与管理:
- 提供详细的日志记录和监控功能,帮助用户了解数据流的执行状态和性能指标。
- 支持告警和通知机制,用户可以根据特定条件设置告警,及时响应异常情况。
Apache NiFi 的设计目标是提供一个灵活、高效且易于管理的数据流管理平台,适用于各种数据集成和处理场景。其丰富的功能集使其成为企业数据管道构建和管理的理想选择。
Apache NiFi的优势
- 灵活性:通过丰富的处理器和自定义开发能力,NiFi 可以适应各种复杂的数据处理需求。
- 可扩展性:支持多节点集群部署,可以水平扩展以处理大规模数据流。
- 可视化管理:提供直观的 Web UI,用户可以轻松设计和管理数据流,无需编写复杂的代码。
- 高可用性:通过故障转移和数据重试机制,确保数据流的高可用性和可靠性。
- 安全性:支持数据加密、访问控制和审计,确保数据的安全性和隐私保护。
Apache NiFi的架构
Apache NiFi 的架构设计旨在提供一个灵活、高效且可扩展的数据流管理平台。它采用模块化设计,支持分布式部署,能够处理各种规模和复杂度的数据流任务。
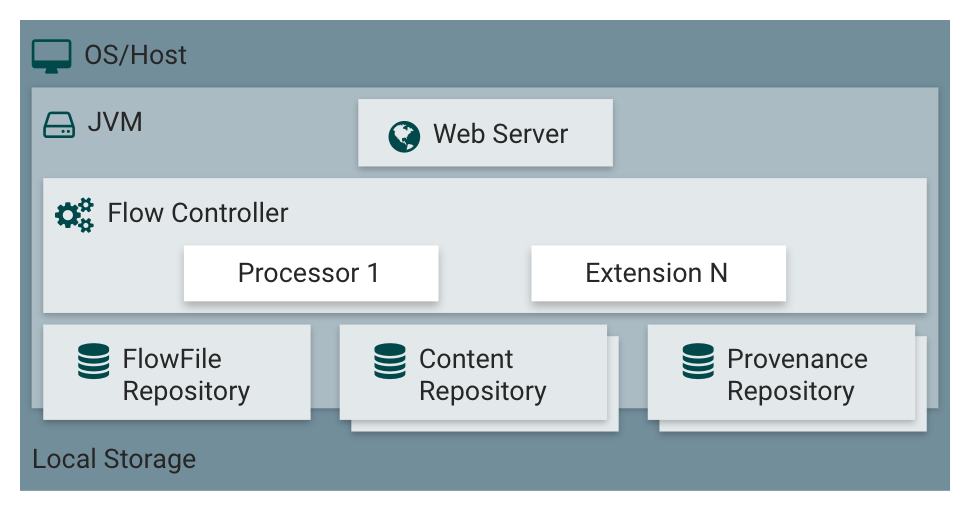
核心组件
- Web UI(用户界面):NiFi 提供了一个直观的 Web 用户界面,用于设计、监控和管理数据流。用户可以通过拖拽和配置组件来构建数据流,并实时查看数据流的状态和性能指标。
- FlowFile:FlowFile 是 NiFi 中的数据单元,包含数据内容和属性。每个 FlowFile 都有唯一标识符和元数据,支持数据的高效传输和处理。
- 处理器(Processor):处理器是执行特定数据处理任务的基本单元。NiFi 提供了丰富的内置处理器,用于数据采集、转换、路由和传输。用户还可以开发自定义处理器以满足特定需求。
- 连接(Connection):连接用于在处理器之间传递 FlowFile。连接可以配置为使用不同的队列策略,以控制数据的流动速度和优先级。
- 流程组(Process Group):流程组用于组织和管理多个处理器和连接,形成逻辑上的子流程。这有助于复杂数据流的模块化设计和维护。
- 控制器服务(Controller Service):控制器服务提供共享的配置和服务,例如数据库连接池、分布式缓存等。它们可以在多个处理器之间复用,提高资源利用率。
- 报告任务(Reporting Task):报告任务用于生成和发送 NiFi 系统的运行状态和指标数据,通常用于监控和告警系统。
工作流和数据流
- 数据采集与处理:
- 数据流从输入处理器开始,输入处理器从外部数据源(如文件系统、HTTP、Kafka)获取数据并生成 FlowFile。
- 中间处理器对 FlowFile 进行处理,包括数据解析、转换、过滤和聚合等操作。
- 数据路由与分发:
- 根据业务规则和条件,NiFi 可以将 FlowFile 路由到不同的处理器或流程组。
- 输出处理器将处理后的 FlowFile 发送到目标系统(如 HDFS、数据库、云存储)。
- 实时监控与管理:
- Web UI 提供实时数据流监控功能,用户可以查看处理器的性能指标、队列长度、处理速率等。
- 用户可以动态调整数据流的配置和参数,以优化性能和处理逻辑。
分布式架构
- 多节点集群:
- NiFi 支持多节点集群部署,可以通过增加节点来扩展处理能力。集群中的每个节点都可以执行数据流任务。
- 集群节点通过 Apache ZooKeeper 进行协调和管理,以确保任务的负载均衡和高可用性。
- 高可用性与故障转移:
- NiFi 采用主从架构,集群中一个节点为主节点(Primary Node),负责调度任务和管理集群配置。
- 在主节点故障时,集群会自动选举新的主节点,确保数据流的持续性和可靠性。
安全性
- 用户认证与授权:
- 支持多种认证机制(如 LDAP、Kerberos),确保只有授权用户才能访问和管理 NiFi 系统。
- 提供细粒度的权限控制,用户可以对不同的数据流组件和操作进行授权。
- 数据加密:
- 支持数据传输加密和存储加密,确保数据在传输和存储过程中的安全性。
- 审计与日志:
- 提供详细的审计日志记录,记录用户操作和数据流处理历史,便于合规性检查和故障排查。
Apache NiFi 的架构设计使其成为一个灵活、可扩展和安全的数据流管理平台,适用于各种规模和复杂度的数据集成和处理任务。其模块化设计和丰富的功能集使得用户能够高效地构建和管理复杂的数据流管道。
Airflow、Kafka的对比
Apache NiFi、Apache Airflow 和 Apache Kafka 都是现代数据处理和管理生态系统中的重要工具,但它们各自的设计目的和应用场景有所不同。以下是它们的详细对比:
| 特性 |
Apache NiFi |
Apache Airflow |
Apache Kafka |
| 主要用途 |
实时数据流管理和自动化 |
工作流调度和管理 |
消息队列和流处理 |
| 架构特点 |
可视化界面,事件驱动架构 |
编程接口定义工作流(DAGs),基于调度器和执行器 |
发布/订阅模型,分布式架构 |
| 数据处理 |
实时数据采集、转换和路由 |
批处理任务调度,不直接处理数据流 |
高吞吐量的消息传输,支持实时流处理 |
| 扩展性与部署 |
多节点集群,水平扩展 |
分布式调度和执行,支持多种执行器 |
水平扩展,通过分区和副本实现容错 |
| 安全性 |
细粒度权限控制和数据加密 |
用户认证和授权(RBAC) |
SSL 加密、SASL 认证和 ACL 授权 |
| 应用场景 |
实时数据集成、物联网数据采集、日志管理和监控 |
定时数据处理任务、复杂的 ETL 管道、机器学习工作流 |
实时数据传输、日志收集和分析、事件驱动架构 |
对比总结
- 实时 vs 批处理:
- NiFi:适合实时数据流处理和自动化。
- Airflow:适合批处理任务调度和复杂的工作流管理。
- Kafka:适合高吞吐量的消息传输和实时流处理。
- 用户界面 vs 编程接口:
- NiFi:提供可视化界面,适合需要快速构建和管理数据流的场景。
- Airflow:提供编程接口,适合需要灵活定义复杂工作流的场景。
- Kafka:主要通过编程接口和命令行工具进行管理和配置。
- 数据流管理 vs 工作流调度 vs 消息队列:
- NiFi:专注于数据流的管理和处理。
- Airflow:专注于任务调度和工作流管理。
- Kafka:专注于消息队列和流处理。
根据具体的需求和场景,企业可以选择合适的工具或组合使用这些工具来构建复杂的数据处理和管理生态系统。例如,可以使用 NiFi 进行数据采集和预处理,使用 Kafka 进行高吞吐量的消息传输,使用 Airflow 进行批处理任务的调度和管理。