simple model + large scale data

知识库:用户知识库,Item知识库,用户评分数据(显性和隐性)等.不同的业务背景不一样,譬如电商,社交网络,视频,app应用等
协同过滤引擎:根据用户评分数据集,通过collaborative filtering方法,计算用户喜欢的top N
item。数据格式: userid, itemid,score
PS:注意数据预处理,尤其是评分数据,可以优化
Context
引擎服务:用户profile数据与item数据匹配,类似搜索引擎服务,譬如常见的用户特征(基本,行为,社会)。数据格式:
userid,itemid,score
实时数据引擎:收集用户实时数据特征,简单实时预处理
业务规则引擎:业务规则处理,主要是定制化的业务,信息过滤
核心引擎:根据应用类型进行服务响应。(1)基于context推荐服务结合实时数据特征(譬如电子商务中的用户购物前的推荐服务),为用户推荐item。(2)基于协同过滤推荐服务结合实时数据特征(没有明显的业务背景),为用户推荐item。Rec(u,v)
= w1 * OnlineScore(u,v) + w2 * OfflineScore(u,v) + b。排序,Online
Ranking,通过机器学习算法,训练在线和离线的权重;或者,通过人工方法,设定权重,在线AB测试,不断尝试。
技术选型
数据存储:voldemort,BDB, postgresql, hbase
实时数据处理:kafka, storm
计算平台:hadoop,hive,Pig, oracle
DM、ML平台:pig,mahout,weka, libsvm,
liblinear等。常用的算法协同过滤,线性回归,logistics 回归,GBDT,聚类(AP)
数据分析与可视化:R python SAS data.js PATTERN
工作流管理:Azkaban
评测:在线AB测试,离线测试,数据指标NDGC,MAE,RMSE,Recall, Precision, CTR, CVR
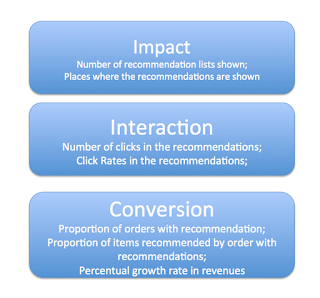
- REC: number of recommendations presented in a list.
- LOC: places where the recommendation lists are placed.
- CER: total of clicks in the recommendations
- CTR (%): rate of clicks in the recommendations
- TPR (%): proportion of orders with recommendations
- TIR (%): proportion of recommended items per order with
recommendation
- IAT (%): increase in the average ticket
- IR (%): increase in the revenue
应用开发:python+flask+bootstrap+memcached+sqlachemy或者其他java,php
人员配置
前期:
超强战斗力性1人 ,个人综合能力强(算法,存储,数据,应用开发)
精编型3人:算法,数据和分析(1人), 存储和工作流(1人),应用开发(1人,前端和应用)
后期:
标配型6人:算法和数据(2人),分析和评测(1人),存储和工作流管理(2人),应用开发(1人,前端和应用)
正规部队10人:算法和数据(4人), 分析和评测(2人), 存储和工作流管理(2人), 应用开发(2人,前端和应用)
http://weibo.com/bicloud
 青春就应该这样绽放 游戏测试:三国时期谁是你最好的兄弟!! 你不得不信的星座秘密
青春就应该这样绽放 游戏测试:三国时期谁是你最好的兄弟!! 你不得不信的星座秘密 