Flume OG 与 Flume NG 的对比
- - 开源软件 - ITeye博客很久没接触flume了,刚掀开官网一看,发现flume已然不是以前的那个flume了,其实早在flume技术群就听到NG这个字眼,以前没特注意,今天做了些对比,发现flume确实有了投胎换骨般的改变. 首先介绍下Flume OG & Flume NG这两个概念. Flume OG:Flume original generation 即Flume 0.9.x版本.
很久没接触flume了,刚掀开官网一看,发现flume已然不是以前的那个flume了,其实早在flume技术群就听到NG这个字眼,以前没特注意,今天做了些对比,发现flume确实有了投胎换骨般的改变。首先介绍下Flume OG & Flume NG这两个概念
Flume OG:Flume original generation 即Flume 0.9.x版本
Flume NG:Flume next generation ,即Flume 1.x版本
对于 Flume OG ,可以说他是一个分布式日志收集系统,有Mater概念,依赖于zookeeper,以下是其架构图
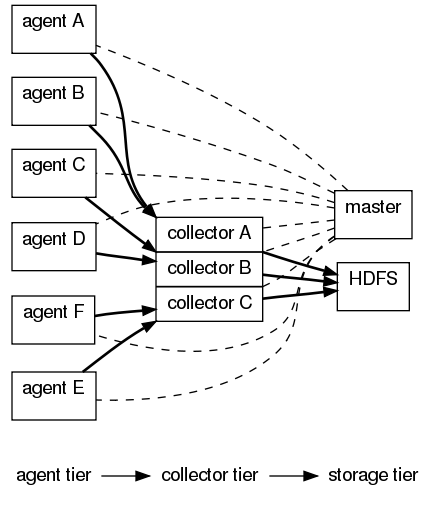
Agent用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector。对应的,collector用于对数据进行聚合,往往会产生一个更大的流。
而对于 Flume NG,它摒弃了Master和zookeeper,collector也没有了,web配置台也没有了,只剩下source,sink和channel,此时一个Agent的概念包括source,channel和sink,完全由一个分布式系统变成了传输工具。不同机器之间的数据传输不再是OG那样由agent->collector,而是由一个Agent端的sink流向另一个agent的source。其新的架构如下


Flume NG is a huge departure from Flume OG (original generation, or "original gangsta," if you prefer) in its implementation although many of the original concepts are the same. If you're already familiar with Flume, here's what you need to know.