1.概述
经过前面Kafka实战系列的学习,我们通过学习《 Kafka实战-入门》了解Kafka的应用场景和基本原理,《 Kafka实战-Kafka Cluster》一文给大家分享了Kafka集群的搭建部署,让大家掌握了集群的搭建步骤,《 Kafka实战-实时日志统计流程》一文给大家讲解一个项目(或者说是系统)的整体流程,《 Kafka实战-Flume到Kafka》一文给大家介绍了Kafka的数据生产过程,《 Kafka实战-Kafka到Storm》一文给大家介绍了Kafka的数据消费,通过Storm来实时计算处理。今天进入Kafka实战的最后一个环节,那就是Kafka实战的结果的数据持久化。下面是今天要分享的内容目录:
下面开始今天的分享内容。
2.结果持久化
一般,我们在进行实时计算,将结果统计处理后,需要将结果进行输出,供前端工程师去展示我们统计的结果(所说的报表)。结果的存储,这里我们选择的是Redis+MySQL进行存储,下面用一张图来展示这个持久化的流程,如下图所示:
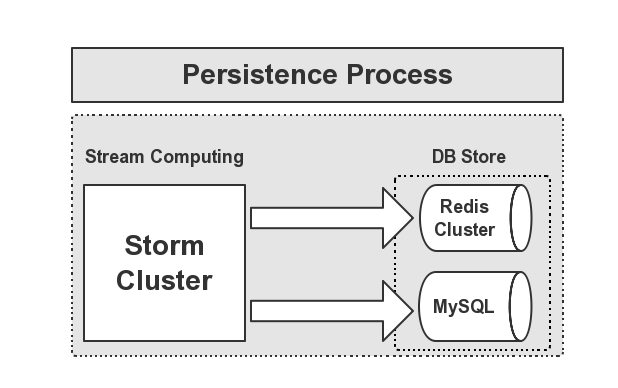
从途中可以看出,实时计算的部分由Storm集群去完成,然后将计算的结果输出到Redis和MySQL库中进行持久化,给前端展示提供数据源。接下来,我给大家介绍如何实现这部分流程。
3.实现过程
首先,我们去实现Storm的计算结果输出到Redis库中,代码如下所示:
package cn.hadoop.hdfs.storm;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import redis.clients.jedis.Jedis;
import cn.hadoop.hdfs.util.JedisFactory;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
/**
* @Date Jun 10, 2015
*
* @Author dengjie
*
* @Note Calc WordsCount eg.
*/
public class WordsCounterBlots implements IRichBolt {
/**
*
*/
private static final long serialVersionUID = -619395076356762569L;
OutputCollector collector;
Map<String, Integer> counter;
@SuppressWarnings("rawtypes")
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.counter = new HashMap<String, Integer>();
}
public void execute(Tuple input) {
String word = input.getString(0);
Integer integer = this.counter.get(word);
if (integer != null) {
integer += 1;
this.counter.put(word, integer);
} else {
this.counter.put(word, 1);
}
for (Entry<String, Integer> entry : this.counter.entrySet()) {
// write result to redis
Jedis jedis = JedisFactory.getJedisInstance("real-time");
jedis.set(entry.getKey(), entry.getValue().toString());
// write result to mysql
// ...
}
this.collector.ack(input);
}
public void cleanup() {
// TODO Auto-generated method stub
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
}
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
注:这里关于输出到MySQL就不赘述了,大家可以按需处理即可。
4.结果预览
在实现持久化到Redis的代码实现后,接下来,我们通过提交Storm作业,来观察是否将计算后的结果持久化到了Redis集群中。结果如下图所示:

通过Redis的Client来浏览存储的Key值,可以观察统计的结果持久化到来Redis中。
5.总结
我们在提交作业到Storm集群的时候需要观察作业运行状况,有可能会出现异常,我们可以通过Storm UI界面来观察,会有提示异常信息的详细描述。若是出错,大家可以通过Storm UI的错误信息和Log日志打印的错误信息来定位出原因,从而找到对应的解决办法。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!

本文链接: Kafka实战-数据持久化,转载请注明。