Storm Trident 学习
- - 小火箭Storm支持的三种语义:. 至少一次语义的Topology写法. 参考资料: Storm消息的可靠性保障
Storm提供了Acker的机制来保证数据至少被处理一次,是由编程人员决定是否使用这一特性,要使用这一特性需要:. 在Spout emit时添加一个MsgID,那么ack和fail方法将会被调用当Tuple被正确地处理了或发生了错误.
Storm支持的三种语义:
参考资料: Storm消息的可靠性保障 Storm提供了Acker的机制来保证数据至少被处理一次,是由编程人员决定是否使用这一特性,要使用这一特性需要:
_collector.emit(new Values("field1", "field2", 3) , msgId);_collector.emit(tuple, new Values(word));Spout例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public class RandomSentenceSpout extends BaseRichSpout {
private SpoutOutputCollector _collector;
private Random _rand;
private ConcurrentHashMap<UUID, Values> _pending;
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
_collector = spoutOutputCollector;
_rand = new Random();
_pending = new ConcurrentHashMap<UUID, Values>();
}
public void nextTuple() {
Utils.sleep(1000);
String[] sentences = new String[] {
"I write php",
"I learning java",
"I want to learn swool and tfs"
};
String sentence = sentences[_rand.nextInt(sentences.length)];
Values v = new Values(sentence);
UUID msgId = UUID.randomUUID();
this._pending.put(msgId, v);
_collector.emit(v, msgId);//发射tuple时,添加msgId
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("world"));
}
public void ack(Object msgId) {
this._pending.remove(msgId);//当消息被完整性地处理了
}
public void fail(Object msgId) {
this._collector.emit(this._pending.get(msgId), msgId);//当消息处理失败了,重新发射,当然也可以做其他的逻辑处理
}
}
Bolt例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
_collector = outputCollector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for (String word : sentence.split(" "))
_collector.emit(tuple, new Values(word));//发射tuple时进行锚定
_collector.ack(tuple);//对处理完的tuple进行确认
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word"));
}
}
如果只需要至多一次的语义,那么只需要在编程的时候不用Storm的Acker机制,可以通过如下方法达到:
需要注意的点:每个待处理的 tuple 都必须显式地应答(ack)或者失效(fail)。因为 Storm 是使用内存来跟踪每个 tuple 的,所以,如果你不对每个 tuple 进行应答或者失效,那么负责跟踪的任务很快就会发生内存溢出。
参考资料: Trident State Trident中的三种Spout,根据Spout代码情况可判断属于哪个: 事务型Spout的特点:
模糊型Spout的特点:
非事务型Spout的特点:
假如你的拓扑需要计算单词数,而且你准备将计数结果存入一个 K-V 型存储系统中。这里的 key 就是单词,value 对应于单词数。如果仅仅存储计数结果是无法确定某个batch中的tuple是否已经被处理过的,例如一个batch已经处理到最后一步并成功写入到了存储系统中,正准备Ack时挂了,那么重新发射这个batch后,被完整地处理了,batch中的tuple就被处理了多次,为了解决这个问题需要State的帮助,即存储的时候做一些处理。 Trident中的三种State,Storm已经提供了多中存储系统State的实现,如MemoryMapState、MemcachedState: 事务型State
模糊型State
(单词, 存储的计数值作为preValue, 存储的计数值+batch计算出来的值作为计数值, batch的txid);若相同,则记录更新为 (单词, preValue, preValue加上batch计算出来的值作为计数值, txid)。非事务型State
不同的Spout类型与不同的State类型的组合是否支持有且仅有一次的消息处理语义:
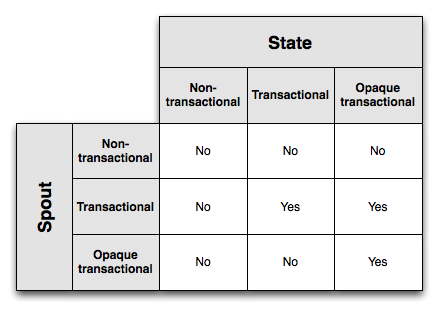
上图中的Yes表示组合支持有且仅有一次的语义。