




系统频繁Full gc问题分析及解决办法
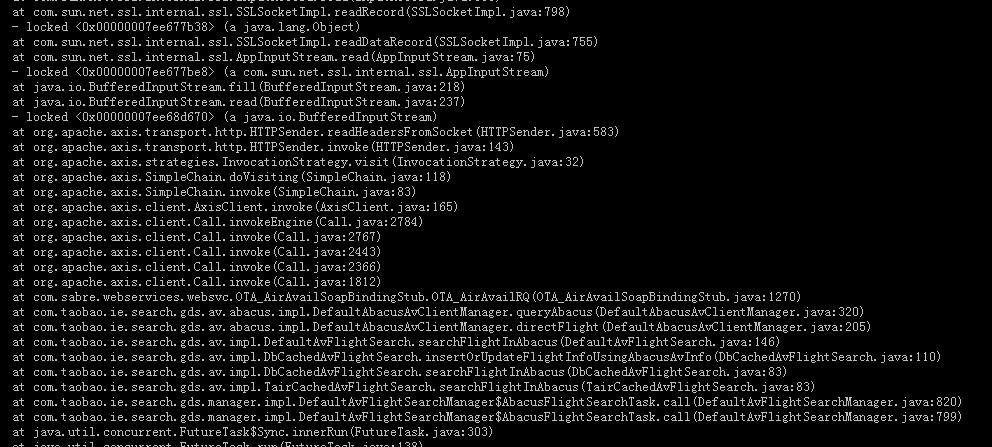
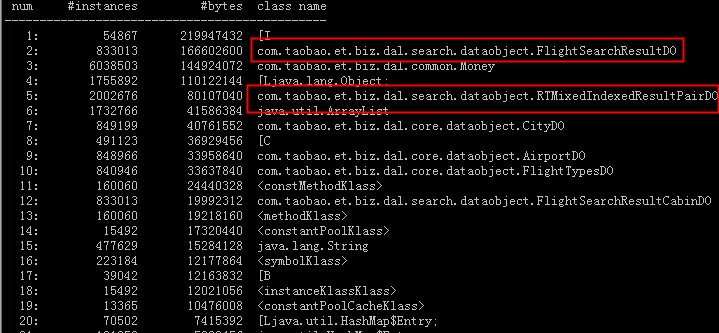
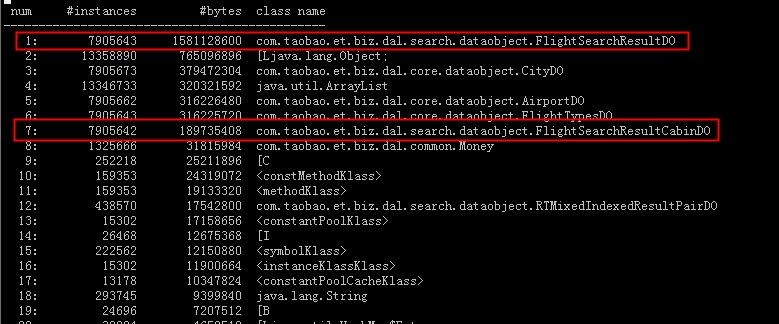
- - JavaRanger - 专注JAVA高性能程序开发、JVM、Mysql优化、算法上周开始系统在业务高峰期一直收到Full gc报警,监控显示fgc频繁,下图是监控图,左边红框是优化前效果,右边是优化后,优化后fgc基本为0. 1.查看gc日志,发现old区fgc后大小没有变化,如下图:. 2.去线上dump内存看是什么对象,用memory analyzer分析,Retained Size竟然有2.4G,全是sun.awt.SunToolkit这个对象,其实到这一步已经可以确定是什么问题了,只是自己对系统不是很熟悉,导致定位具体的问题代码花了一些时间.