APP 缓存数据线程安全问题探讨
- - bang’s blog一般一个 iOS APP 做的事就是:请求数据->保存数据->展示数据,一般用 Sqlite 作为持久存储层,保存从网络拉取的数据,下次读取可以直接从 Sqlite DB 读取. 我们先忽略从网络请求数据这一环节,假设数据已经保存在 DB 里,那我们要做的事就是,ViewController 从 DB 取数据,再传给 view 渲染:.
一般一个 iOS APP 做的事就是:请求数据->保存数据->展示数据,一般用 Sqlite 作为持久存储层,保存从网络拉取的数据,下次读取可以直接从 Sqlite DB 读取。我们先忽略从网络请求数据这一环节,假设数据已经保存在 DB 里,那我们要做的事就是,ViewController 从 DB 取数据,再传给 view 渲染:

这是最简单的情况,随着程序变复杂,多个 ViewController 都要向 DB 取数据,ViewController本身也会因为数据变化重新去 DB 取数据,会有两个问题:
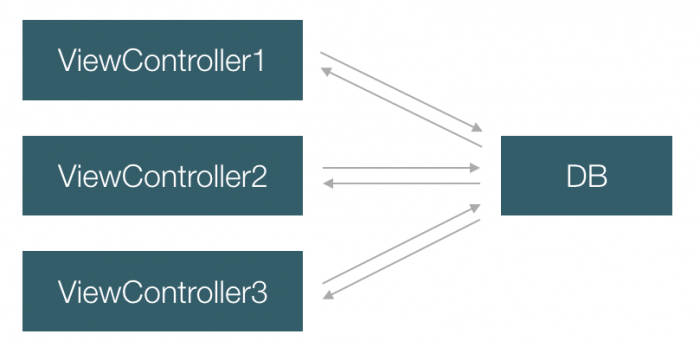
对这里做优化,自然会想到在 DB 和 VC 层之间再加一层 cache,把从 DB 读取出来的数据 cache 在内存里,下次来取同样的数据就不需要再去磁盘读取 DB 了。

几乎所有的数据库框架都做了这个事情,包括微信读书开源的 GYDataCenter,CoreData,Realm 等。但这样做会导致一个问题,就是数据的线程安全问题。
按上面的设计,Cache层会有一个集合,持有从DB读取的数据。

除了 VC 层,其他层也会从cache取数据,例如网络层。上层拿到的数据都是对 cache 层这里数据的引用:
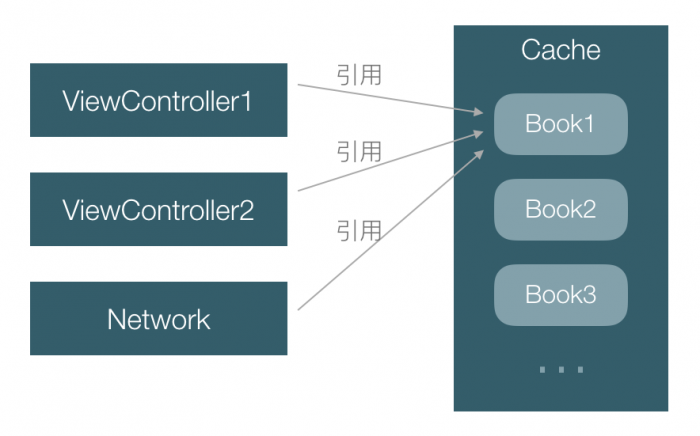
可能还会在网络层子线程,或其他一些用于预加载的子线程使用到,如果某个时候一条子线程对这个 Book1 对象的属性进行修改,同时主线程在读这个对象的属性,就会 crash,因为一般我们为了性能会把对象属性设为nonatomic,是非线程安全的,多线程读写时会有问题:
//Network WRBook *book = [WRCache bookWithId:@“10000”]; book.fav = YES; //子线程在写 [book save]; //VC1 WRBook *book = [WRCache bookWithId:@“10000”]; self.view.title = book.title; //主线程在读
可以通过这个测试看到 crash 场景:
@interface TestMultiThread : NSObject
@property (nonatomic) NSArray *arr;
@end
@implementation TestMultiThread
@end
TestMultiThread *obj = [[TestMultiThread alloc] init];
for (int i = 0; i < 1000; i ++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"%@", obj.arr);
});
}
for (int i = 0; i < 1000; i ++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
obj.arr = [NSArray arrayWithObject:@“b"];
});
}
对这种情况,一般有三种解决方案:
既然这个对象的属性是非线程安全的,那加锁让它变成线程安全就行了。可以给每个对象自定义一个锁,也可以直接用 OC 里支持的属性指示符 atomic:
@property (atomic) NSArray *arr;
这样就不用担心多线程同时读写的问题了。但在APP里大规模使用锁很可能会导致出现各种不可预测的问题,锁竞争,优先级反转,死锁等,会让整个APP复杂性增大,问题难以排查,并不是一个好的解决方案。
另一种方案是一条线程创建一个 cache,每条线程只对这条线程对应的 cache 进行读写,这样就没有线程安全问题了。CoreData 和 Realm 都是这种做法,但这个方案有两个缺点:
CoreData 在不同线程要创建自己的 NSManagedObjectContext,这个 context 里维护了自己的 cache,如果某条子线程没有创建 NSManagedObjectContext,要读取数据就需要通过 performBlockAndWait: 等接口跑到其他线程去读取。如果多个 context 需要同步 cache 数据,就要调用它的 merge 方法,或者通过 parent-children context 层级结构去做。这导致它多线程使用起来很麻烦,API 友好度极低。
Realm 做得好一点,会在线程 runloop 开始执行时自动去同步数据,但如果线程没有 runloop 就需要手动去调 Realm.refresh() 同步。使用者还是需要明确知道代码在哪条线程执行,避免在多线程之间传递对象。
我们的问题是多线程同时读写导致,那如果只读不写,是不是就没有问题了?数据不可变指的就是一个数据对象生成后,对象里的属性值不会再发生改变,不允许像上述例子那样 book.fav = YES 直接设置,若一个对象属性值变了,那就新建一个对象,直接整个替换掉这个旧的对象:
//WRCache
@implementation WRCache
+(void) updateBookWithId:(NSString *)bookId params:(NSDictionary *)params
{
[WRDBCenter updateBookWithId:@“10000” params:{@“fav”: @(YES)}]; //更新DB数据
WRBook *book = [WRDBCenter readBookWithId:bookId]; //重新从DB读取,新对象
[self.cache setObject:book forKey:bookId]; //整个替换cache里的对象
}
@end
self.book = [WRCache bookWithId:@“10000”];
// book.fav = YES; //不这样写
[WRCache updateBookWithId:@“10000” params:{@“fav”: @(YES)}]; //在cache里整个更新
self.book = [WRCache bookWithId:@“10000”]; //重新读取对象
这样就不会再有线程安全问题,一旦属性有修改,就整个数据重新从DB读取,这些对象的属性都不会再有写操作,而多线程同时读是没问题的。
但这种方案有个缺陷,就是数据修改后,会在 cache 层整个替换掉这个对象,但这时上层扔持有着旧的对象,并不会自动把对象更新过来:

所以怎样让上层更新数据呢?有两种方式,push 和 pull。
push 的方式就是 cache 层把更新 push 给上层,cache对整个对象更新替换掉时,发送广播通知上层,这里发通知的粒度可以按需求斟酌,上层监听自己关心的通知,如果发现自己持有的对象更新了,就要更新自己的数据,但这里的更新数据也是件挺麻烦的事。
举个例子,读书有一个想法列表WRReviewController,存着一个数组 reviews,保存着想法 review 数据对象,数组里的每一个 review 会持有这个这个想法对应的一本书,也就是 review.book 持有一个 WRBook 数据对象。然后这时 cache 层通知这个 WRReviewController,某个 book 对象有属性变了,这时这个 WRReviewController 要怎样处理呢?有两个选择:
第一种是精细化的做法,优点是不影响性能,缺点是蛋疼,工作量增多,还容易漏更新,需要清楚知道当前模块持有了哪些数据,有哪些需要更新。第二种是粗犷的做法,优点是省事省心,全部大刷一遍就行了,缺点是在一些复杂页面需要组装数据,会对性能造成较大影响。
另一种 pull 的方式是指上层在特定时机自己去判断数据有没有更新。
首先所有数据对象都会有一个属性,暂时命名为 dirty,在 cache 层更新替换数据对象前,先把旧对象的 dirty 属性设为 YES,表示这个旧对象已经从 cache 里被抛弃了,属于脏数据,需要更新。然后上层在合适的时候自行去判断自己持有的对象的 dirty 属性是否为 YES,若是则重新在 cache 里取最新数据。
实际上这样做发生了多线程读写 dirty 属性,是有线程安全问题的,但因为 dirty 属性读取不频繁,可以直接给这个属性的读写加锁,不会像对所有属性加锁那样引发各种问题,解决对这个 dirty 属性读写的线程安全问题。
这里主要的问题是上层应该在什么时机去 pull 数据更新。可以在每次界面显示 -viewWillAppear 或用户操作后去检查,例如用户点个赞,就可以触发一次检查,去更新赞的数据,在这两个地方做检查已经可以解决90%的问题,剩下的就是同个界面联动的问题,例如 iPad 邮件左右两栏两个 controller,右边详情点个收藏,左边列表收藏图标也要高亮,这种情况可以做特殊处理,也可以结合上面 push 的方式去做通知。
push 和 pull 两种是可以结合在一起用的,pull 的方式弥补了 push 后数据全部重新读取大刷导致的性能低下问题,push 弥补了 pull 更新时机的问题,实际使用中配合一些事先制定的规则或框架一起使用效果更佳。
对于 APP 缓存数据线程安全问题,分线程 cache 和数据不可变是比较常见的解决方案,都有着不同的实现代价,分线程 cache 接口不友好,数据不可变需要配合单向数据流之类的规则或框架才会变得好用,可以按需选择合适的方案。