在线AI技术在搜索与推荐场景的应用
- - 创业邦 12月6日-7日,由阿里巴巴集团、阿里巴巴技术发展部、阿里云云栖社区联合主办,以“2016双11技术创新”为主题的阿里巴巴技术论坛(Alibaba Technology Forum,ATF)成功在线举办. 在本次分享中,来自阿里巴巴集团的研究员徐盈辉带了题为《在线AI技术在搜索与推荐场景的应用》的精彩演讲,他结合本届双11搜索和推荐场景详细介绍了电商搜索推荐的技术演变、阿里搜索推荐的新技术体系以及未来的发展方向.
12月6日-7日,由阿里巴巴集团、阿里巴巴技术发展部、阿里云云栖社区联合主办,以“2016双11技术创新”为主题的阿里巴巴技术论坛(Alibaba Technology Forum,ATF)成功在线举办。在本次分享中,来自阿里巴巴集团的研究员徐盈辉带了题为《在线AI技术在搜索与推荐场景的应用》的精彩演讲,他结合本届双11搜索和推荐场景详细介绍了电商搜索推荐的技术演变、阿里搜索推荐的新技术体系以及未来的发展方向。
以下内容根据在线分享和幻灯片整理而成。
电商搜索推荐技术演变过程
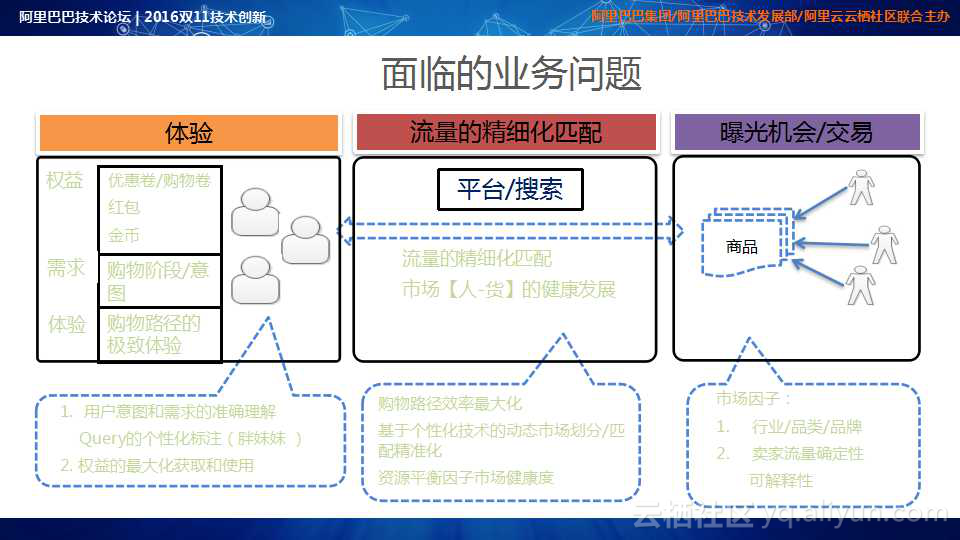
对于阿里巴巴电子商务平台而言,它涉及到了买家、卖家和平台三方的利益,因此必须最大化提升消费者体验;最大化提升卖家和平台的收益。在消费者权益中,涉及到了一些人工智能可以发力的课题,如购物券和红包的发放,根据用户的购物意图合理地控制发放速率和中奖概率,更好地刺激消费和提升购物体验;对于搜索,人工智能主要用于流量的精细化匹配以及在给定需求下实现最佳的人货匹配,以实现购物路径效率最大化。经过几年的努力,阿里研发了一套基于个性化技术的动态市场划分/匹配技术。
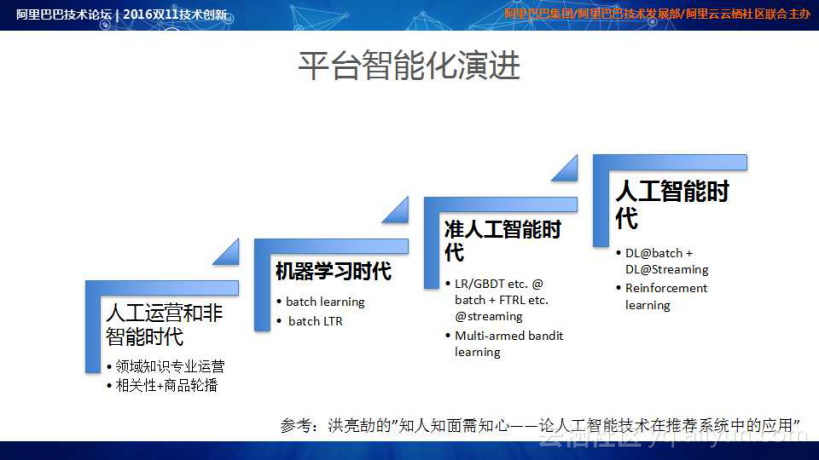
电商搜索和推荐的智能化演进路程可以划分为四个阶段:人工运营和非智能时代、机器学习时代、准人工智能时代、人工智能时代。人工运营和非智能时代,主要靠领域知识人工专业运营,平台的流量投放策略是基于简单的相关性+商品轮播;在机器学习时代,利用积累的大数据分析用户购物意图,最大化消费者在整个链路中可能感兴趣的商品;准人工智能时代,将大数据处理能力从批量处理升级到实时在线处理,有效地消除流量投放时的误区,有效地提高平台流量的探索能力;人工智能时代,平台不仅具有极强的学习能力,也需要具备一定的决策能力,真正地实现流量智能投放。
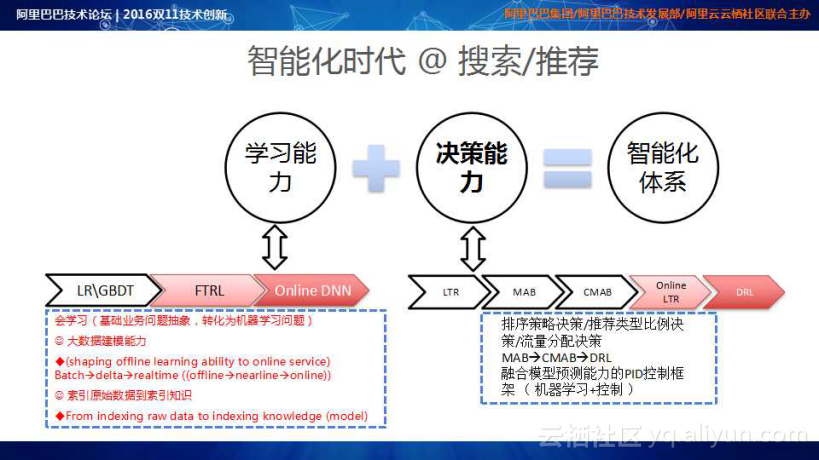
智能化时代,对于搜索和推荐而言,可以提炼为两点:学习能力和决策能力。学习能力意味着搜索体系会学习、推荐平台具有很强的建模能力以及能够索引原始数据到索引知识提升,学习能力更多是捕捉样本特征空间与目标的相关性,最大化历史数据的效率。决策能力经历了从LTR到MAB再到CMAB再到DRL的演变过程,使得平台具备了学习能力和决策能力,形成了智能化体系。
借他山之石以攻玉
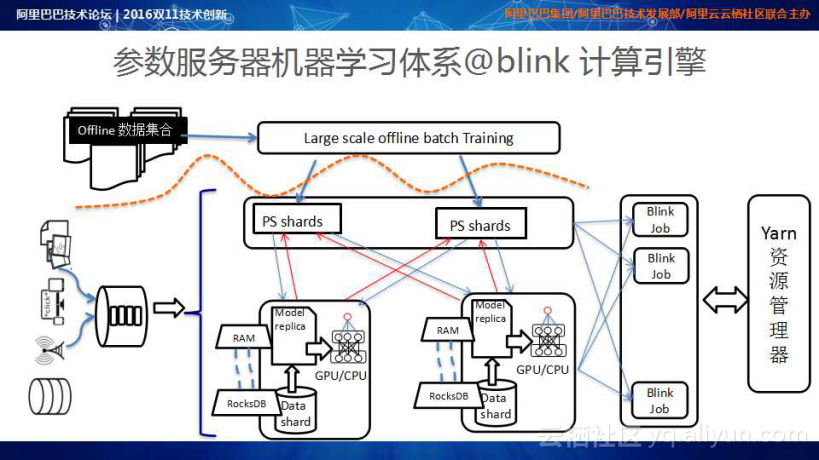
借他山之石以攻玉。在线服务体系中,我们基于参数服务器构建了基于流式引擎的Training体系,该体系消费实时数据,进行Online Training;On Training的起点是基于离线的Batch Training进行Pre-train和Fine Tuning;然后基于实时的流式数据进行Retraining;最终,实现模型捕捉实时数据的效果。
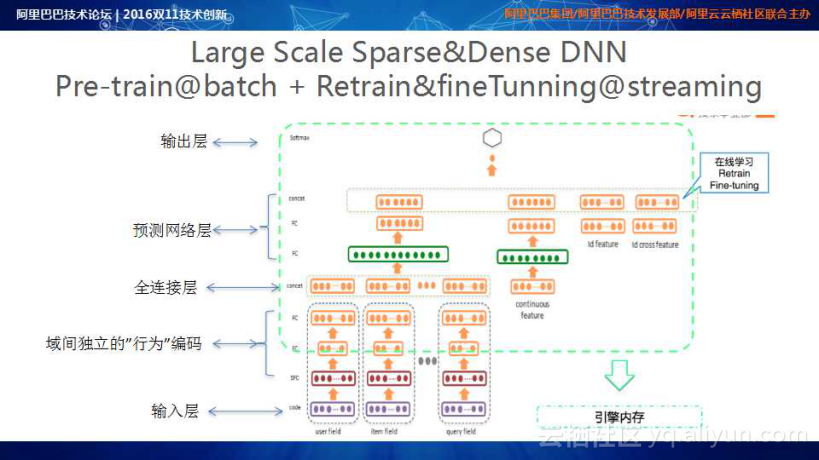
上图是基于Wide & Deep Learning for Recommender Systems的工作建立的Large Scale Sparse&Dense DNN训练体系的架构,该架构中利用Batch Learning进行Pre-Train,再加上Online数据的Retrain&fine Tuning。模型在双11当天完成一天五百万次的模型更新,这些模型会实时输送到在线服务引擎,完成Online的Prediction。
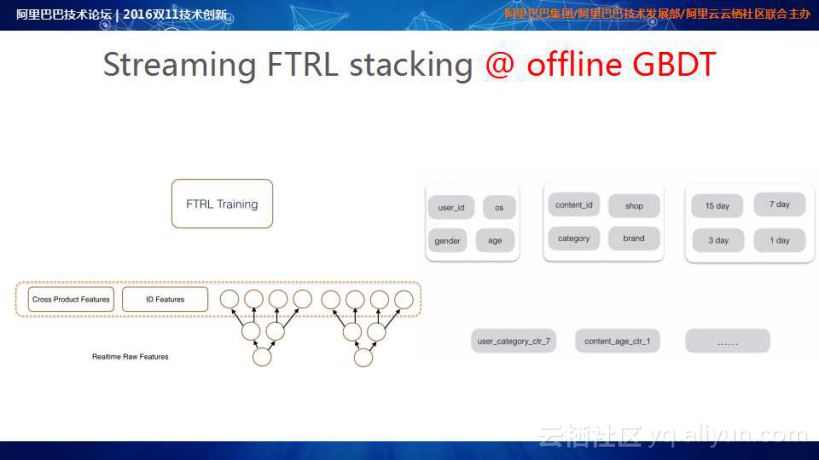
Streaming FTRL stacking@offline GBDT的基本理念是通过离线的训练,在批量数据上建立GBDT的模型;在线的数据通过GBDT的预测,找到相应的叶子节点作为特征的输入,每一个特征的重要性由online training FTRL进行实时调整。
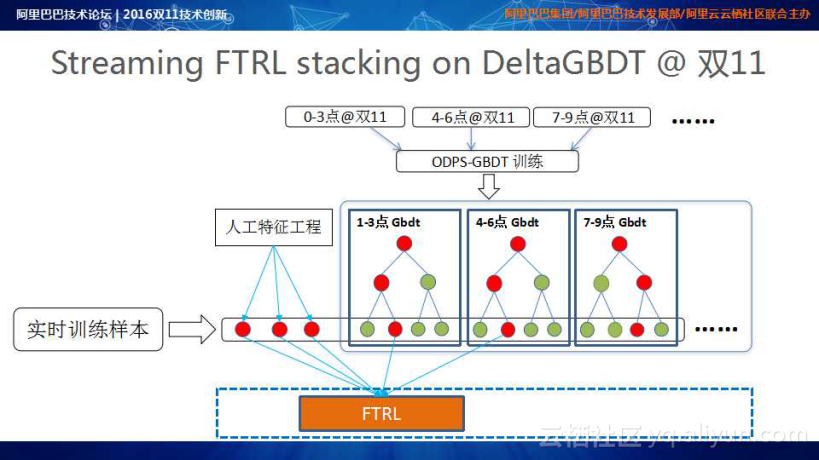
双11当天的成交额是是普通成交日的十到十二倍,点击量将近三十倍。在用户行为密集发生的情况下,有理由相信数据分布在一天内发生了显著的变化,基于这样的考虑,GBDT的Training由原来的日级别升级到小时级别(每小时进行GBDT Training),这些Training的模型部署到Streaming的计算体系中,对于实时引入的训练样本做实时的预测来生成对应的中间节点,这些中间节点和人工的特征一起送入FTRL决出相应特征的重要性。
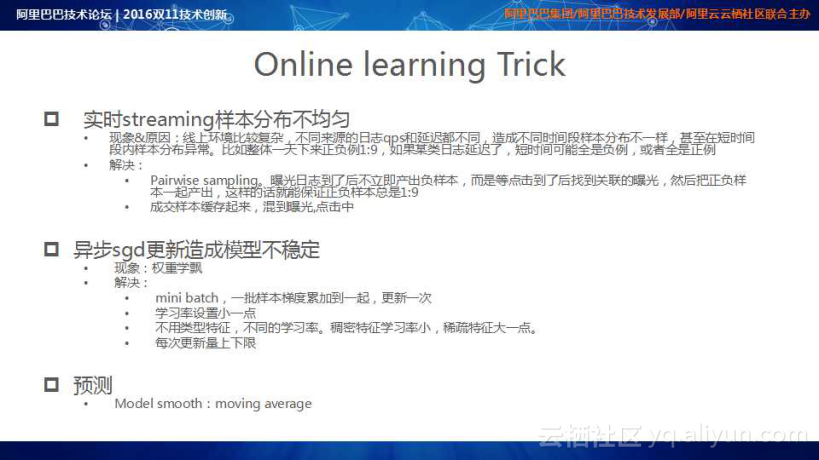
Online Learning和Batch Learning有很大的区别,在Online Learning的研发过程中,总结了一些技巧:
实时streaming样本分布不均匀时,由于线上环境比较复杂,不同来源的日志qps和延迟都不同,造成不同时间段样本分布不一样,甚至在短时间段内样本分布异常。比如整体一天下来正负例1:9,如果某类日志延迟了,短时间可能全是负例,或者全是正例,很容易导致特征超出正常值范围。对应的解决方案是提出了一些 Pairwise sampling:曝光日志到了后不立即产出负样本,而是等点击到了后找到关联的曝光,然后把正负样本一起产出,这样的话就能保证正负样本总是1:9;成交样本缓存起来,正样本发放混到曝光点击中,慢慢将Training信号发放到样本空间中。
异步sgd更新造成模型不稳定时,由于训练过程采用的是异步SGD计算逻辑,其更新会导致模型不稳定,例如某些权重在更新时会超出预定范围。对应的解决方案是采用mini batch,一批样本梯度累加到一起,更新一次;同时将学习率设置小一点,不同类型特征有不同的学习率,稠密特征学习率小,稀疏特征学习率大一些;此外,对每个特征每次更新量上下限进行限制保护。
预测时,在参数服务器中进行Model Pulling,通过采用合理的Model smooth和Model moving average策略来保证模型的稳定性。
智能化体系中的决策环节
电商平台下的大数据是源自于平台的投放策略和商家的行业活动,这些数据的背后存在很强Bias信息。所有的学习手段都是通过日志数据发现样本空间的特征和目标之间的相关性;进而生成模型;之后利用模型预测线上的点击率或转化率,由于预测模型用于未来流量投放中,因此两者之间存在一定的时间滞后(systematic bias),也就观测到的数据和实际失效的数据存在着Gap。在工作逻辑中,如果一个特征和目标存在很强的Correlation,则该特征就应该在线上的预测中起到重要作用。
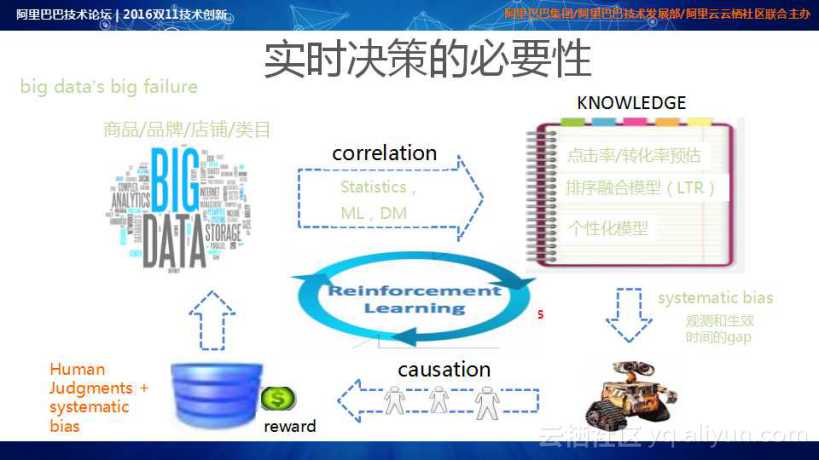
在整个体系中,Systematic Bias很难做到理想化的控制,而且离线模型预期效果与线上的实际生效效果存在差异,这背后的根本原因是Correlation并不等于Causation,也就是特征与目标相关并不意味着特征出现一定导致目标发生。
那么怎么解决Offline Reward Signal不等于Online Dashboard Metrics的问题呢?我们引入了强化学习,通过引入Online User Feedback更好地定义Reward,对线上排序策略进行调整,使其具有更强的自适应性。
搜索/推荐引擎决策体系
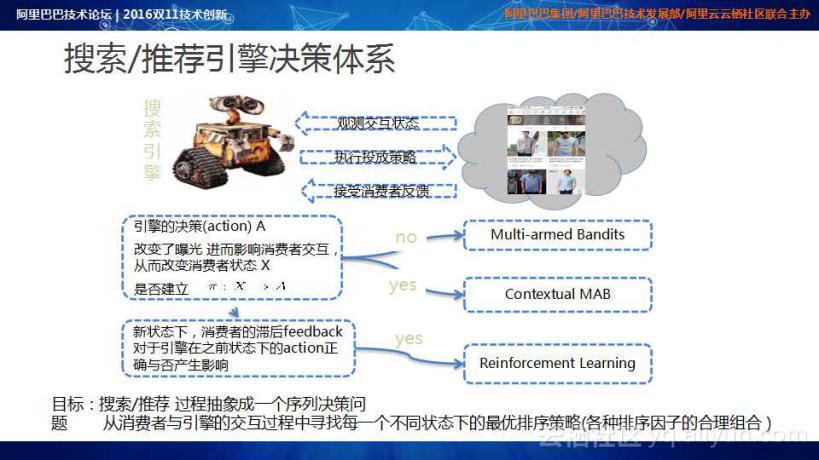
搜索引擎和投放页面天然存在互动:搜索引擎观测消费者的交互状态;搜索引擎根据交互状态执行投放策略;投放策略之后,呈现商品结果页,消费者在商品结果页中的操作行为反馈给搜索引擎。引擎决策实际上能改变投放环境,进而影响消费者的交互,改变消费者的状态。如果不需要建立从状态到动作的策略映射,可以采用Multi-armed Bandits方法进行流量探索;如果需要建立该映射时,需要采用Contextual MAB方法;在新状态下,考虑消费者的滞后Feedback对于引擎在之前状态下的Action正确与否产生影响,需要引入强化学习的思想。
搜索和推荐过程可以抽象成一个序列决策问题,从消费者与引擎的交互过程中寻找每一个不同状态下的最优排序策略(各种排序因子的合理组合)。

我们的目标是希望搜索引擎决策体系进化为具有强化学习能力的智能化平台。过去的搜索,我们只能做到遇到同样的用户购物诉求下,尽可能保证做得不必以前最好的方法差,也就是所谓的Historical Signal==Best Strategy;一切模型都是建立在优化直接收益的基础上。未来的搜索,我们希望能够保证长期收益最大化来决定引擎的排序策略,也就是Immediate Reward+Future Expectation=Best Strategy;未来的排序融合入模式都是建立在优化马尔科夫决策过的基础上,最大化The Discounted Reward。
基于强化学习的实时搜索排序调控
下面简要介绍下为应对今年双11提出的基于强化学习的实时搜索排序调控算法。

对于强化学习,它的目标是最大化时刻T所选择的策略的长期收益最大。对于离散state和离散Action的情况,可以采用Tabular RL方法求解;对于连续State和连续Action,采用RL with Function Approximation。其中State表示用户近期发生行为商品的可量化特征,Action表示权重量化(维度是排序特征分),Reward是Systematic Valid User Feedback。
双11采用Q-learning的方式进行实时策略排序的学习,将状态值函数从状态和策略空间将其参数化,映射到状态值函数的参数空间中,在参数空间中利用Policies Gradient进行求解;将状态值函数Q拆解成状态值函数V(s)和优势函数A(s,a)进行表达。

其算法逻辑如上图所示,基本算法是实现线上几十个排序分的有效组合,样本包括日志搜集到的状态空间、Action Space(这里对应的是排序分空间),奖赏是用户有效的Feedback,具体的排序策略表达公式以及策略更新和值函数更新的公式可以参考Maei,HR的《Toward off-policy learning control with function approximation》一文。
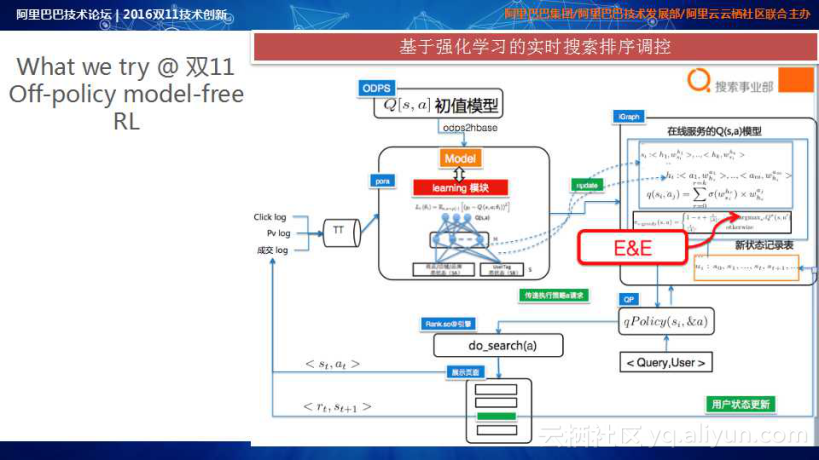
在双11采用的基于强化学习的实时搜索排序调控的实现体系如上图所示。当用户输入query时,会向系统询问哪一种排序策略最适合自己;该查询策略请求会上传至在线策略决策引擎,在线策略决策引擎通过实时学习的Q(s,a)模型合理选择有效策略,然后再返回给搜索引擎;搜索引擎依据当前状态下最有效策略执行搜索排序;在搜索排序页面展示的同时,系统会及时搜集相应的状态 action以及用户feedback的信号,并进入到Online Training Process;而Online Training Process会通过Off-policy model-free RL方法学习State To Action的映射关系,再从映射关系中得到线上排序所需要的策略参数;该策略参数由在线策略决策引擎通过Policy Invalid Process输出给在线搜索引擎。
总结
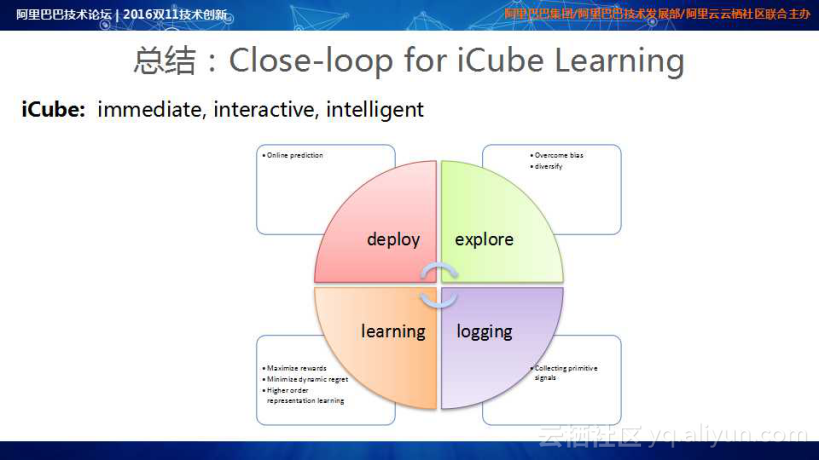
整体搜索/推荐希望建立一个Close-loop for iCube learning体系,其中iCube要求系统具备immediate、interactive、intelligent的能力。整体从日志搜集到maximize rewards、minimize dynamic regret实现Online Training;其中Training模块能够高效地部署到Online Service;而Online Service必须具有很强的探索和overcome bias能力,进而使得整个体系能够适应新的数据,提升流量投放效率,同时能够探索新奇和未知的空间。
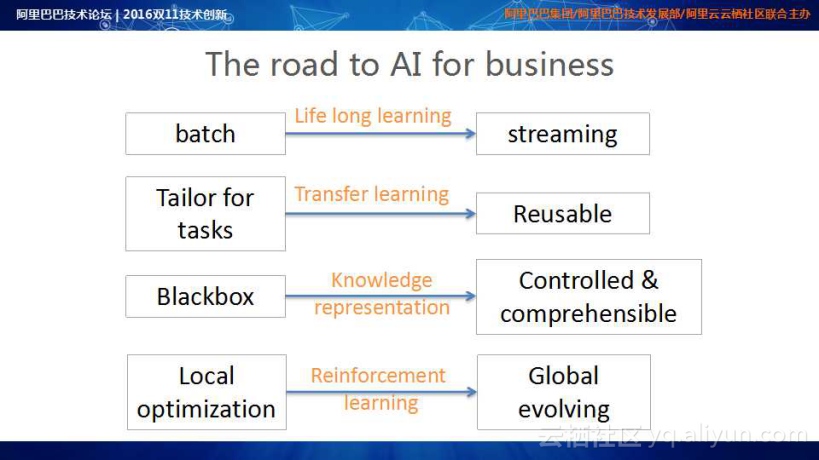
在AI应用到商业的过程中,未来努力方向是:
From batch to streaming,希望从historical batch learning转化为life long learning;
整个学习体系由tailor for tasks 向利用transfer learning实现不同渠道、应用下学习模型的复用转变;
Training process 从Blackbox转变为实现合理的knowledge representation,实现线上投放逻辑的controlled&comprehensible;
学习体系随着强化学习和在线决策能力的增强,从local optimization向global evolving转变。
大会所有资源(视频回放、PDF、文章整理)一键下载:https://yq.aliyun.com/articles/65238
大会系列整理文章:
阿里双11背后的网络自动化技术——张铭(阿里巴巴研究员)
演讲整理文章:https://yq.aliyun.com/articles/64680
阿里大规模数据计算与处理平台——林伟(阿里巴巴资深技术专家)
演讲整理文章:https://yq.aliyun.com/articles/66113
在线AI技术在搜索与推荐场景的应用——徐盈辉(阿里巴巴研究员)
演讲整理文章:https://yq.aliyun.com/articles/66158
揭秘阿里虚拟互动实验室——袁岳峰(阿里巴巴高级技术专家)
演讲整理文章:https://yq.aliyun.com/articles/66105
阿里超大规模Docker化之路——林昊(阿里巴巴研究员)
演讲整理文章:https://yq.aliyun.com/articles/65377
双11媒体大屏背后的数据技术和产品——罗金鹏(阿里巴巴高级技术专家)
演讲整理文章:https://yq.aliyun.com/articles/66098
数据赋能商家背后的AI技术——魏虎(阿里巴巴资深技术专家)
演讲整理文章:https://yq.aliyun.com/articles/66159
面对双11的前端“极限挑战”——舒文亮(阿里巴巴高级技术专家)
演讲整理文章:https://yq.aliyun.com/articles/66106
创业邦携手阿里云推出创业四重礼,包括1-3万免费云资源、35+产品6个月免费等福利>>http://www.cyzone.cn/aliyun/